

使用selenium模拟登陆豆瓣网对搜索功能抓取数据
首先安装
selenium可以直接可以用pip安装。
1 | pip install selenium |
接下来安装谷歌驱动,chromedriver的安装一定要与Chrome的版本一致。
安装地址如下:
注:查看自己的谷歌浏览器版本信息:在浏览器中输入chrome://version/
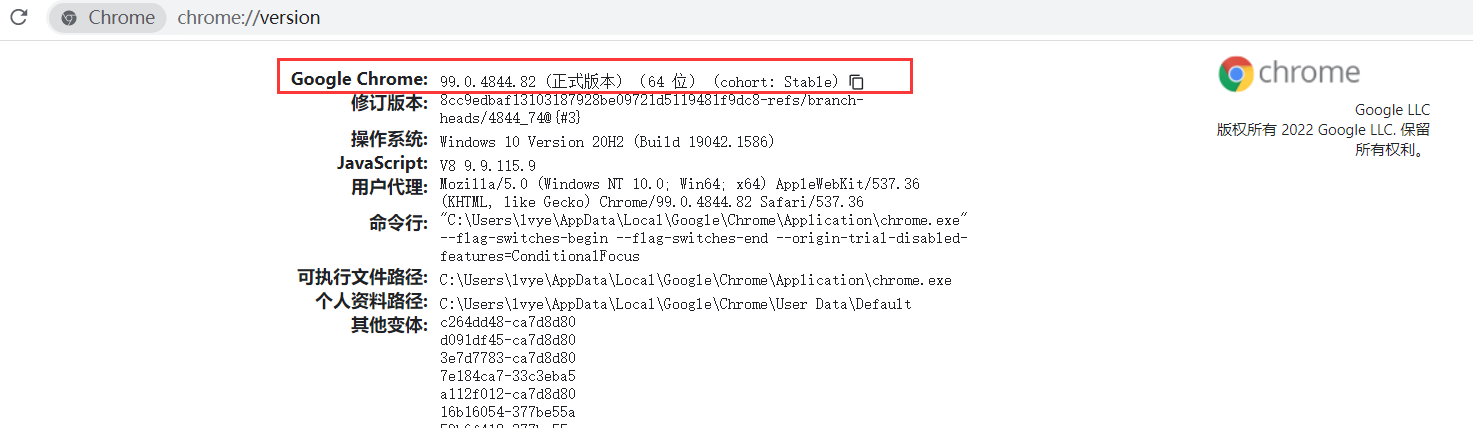
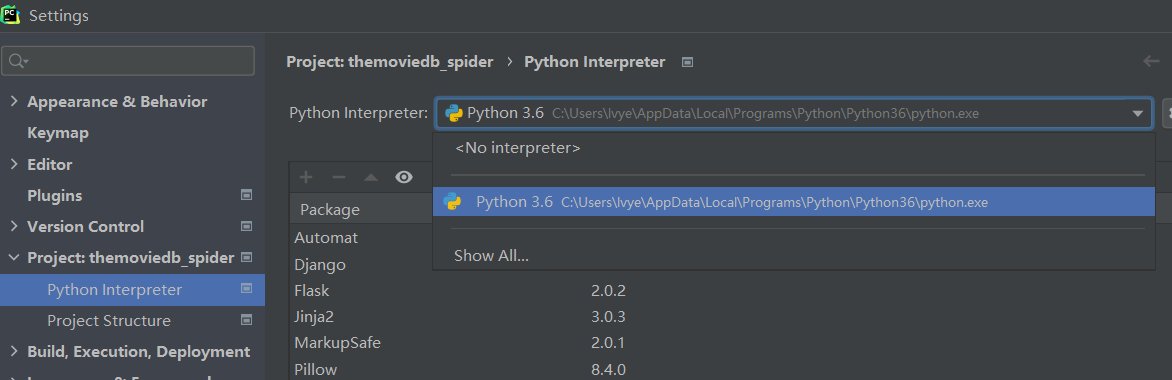
下载之后解压,存放到python目录下,你的python环境安装目录如下:
一切就绪后测试代码是否可以启动浏览器
1 2 3 4 | from selenium import webdriverbrowsers = webdriver.Chrome()browsers.get('https://movie.douban.com/') |
下面上豆瓣网搜索功能代码:

from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By from selenium import webdriver import json from lxml import etree from difflib import SequenceMatcher import re options = webdriver.ChromeOptions() options.add_argument( 'user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36"' ) prefs = { 'profile.default_content_setting_values': { 'images': 2 } } options.add_experimental_option('prefs', prefs) #不加载图片 options.add_argument('--headless') # 浏览器不提供可视化页面 options.add_argument('--disable-gpu')#谷歌文档提到需要加上这个属性来规避bug browser = webdriver.Chrome(chrome_options=options) class DoubanCrawler(): def get_cookies(self): browser.get('https://movie.douban.com/') browser.implicitly_wait(2) browser.find_element_by_xpath('/html/body/div/div/div[2]/p/a').click() browser.find_element_by_xpath('//*[@id="account"]/div[2]/div[2]/div/div[1]/div/div[1]/a[1]').click() WebDriverWait(browser,20).until(EC.presence_of_element_located((By.ID,'inp-query'))) cookies_data = browser.get_cookies() with open('cookes.txt','w')as f: f.write(json.dumps(cookies_data)) def set_cookies(self,movie_name):#模拟登陆进行搜索 browser.get('https://www.douban.com/') with open('cookes.txt','r')as f: cookie_lists = json.loads(f.read()) for cookie in cookie_lists: cookie_dict = { 'domain': '.douban.com', 'name': cookie.get('name'), 'value': cookie.get('value'), "expires": cookie.get('expires'), 'path': '/', } browser.add_cookie(cookie_dict) browser.refresh() browser.find_element_by_xpath("//div[@class='bd']/div[@class='global-nav-items']/ul/li[3]/a").click() browser.switch_to_window(browser.window_handles[1]) #切换tab窗口 browser.find_element_by_xpath("//input[@id='inp-query']").send_keys(movie_name) browser.find_element_by_xpath('//*[@id="db-nav-movie"]/div[1]/div/div[2]/form/fieldset/div[2]/input').click() if not '没有找到关于' in browser.page_source: HTML = etree.HTML(browser.page_source) title = HTML.xpath('//*[@id="root"]/div/div[2]/div[1]/div[1]/div[1]/div[1]/div/div[1]/a/text()')[0].replace('\u200e','').split('(')[0].strip() titles =''.join(re.findall(r'[\u4e00-\u9fa5]',title)) #匹配中文 detail_id = HTML.xpath('//*[@id="root"]/div/div[2]/div[1]/div[1]/div[1]/div[1]/div/div[1]/a/@href')[0].split('/')[-2] reslut = self.similarity(movie_name,titles) browser.quit() # 关闭浏览器 if reslut >= 0.7: return titles,detail_id,reslut else: return False else: return False def similarity(self,a, b): #字符串对比 return SequenceMatcher(None, a, b).ratio()#引用ratio方法,返回序列相似性的度量 if __name__ == '__main__': n = DoubanCrawler().set_cookies('小狗吉米走私事件') print(n)
更多关于selenium的使用方法请移步:https://blog.csdn.net/qq_33961117/article/details/86616122
python之selenium设置浏览器为手机模式(开发者模式)https://www.cnblogs.com/FBGG/p/15984400.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?