数据库之Redis篇
1.基于内存的key-value数据库 2.基于c语言编写的,可以支持多种语言的api //set每秒11万次,取get 81000次 3.支持数据持久化(快照与AOF) 4.value可以是string,hash, list, set, sorted set 使用场景 1. 去最新n个数据的操作 2. 排行榜,取top n个数据 //最佳人气前10条 3. 精确的设置过期时间 4. 计数器 5. 实时系统, 反垃圾系统 6. pub, sub发布订阅构建实时消息系统 7. 构建消息队列 8. 缓存

windows下cmd启动server(redis-server.exe 配置文件)
D:\redis\redis-server.exe D:\redis\redis.windows.conf
cmd访问redis redis-cli.exe -h 127.0.0.1 -p 6379 key keys * 获取所有的key select 0 选择第一个库 move myString 1 将当前的数据库key移动到某个数据库,目标库有,则不能移动 flush db 清除指定库 randomkey 随机key type key 类型 set key1 value1 设置key get key1 获取key mset key1 value1 key2 value2 key3 value3 mget key1 key2 key3 del key1 删除key exists key 判断是否存在key expire key 10 10过期 pexpire key 1000 毫秒 persist key 删除过期时间 string set name cxx get name getrange name 0 -1 字符串分段 getset name new_cxx 设置值,返回旧值 mset key1 key2 批量设置 mget key1 key2 批量获取 setnx key value 不存在就插入(not exists) setex key time value 过期时间(expire) setrange key index value 从index开始替换value incr age 递增 incrby age 10 递增 decr age 递减 decrby age 10 递减 incrbyfloat 增减浮点数 append 追加 strlen 长度 getbit/setbit/bitcount/bitop 位操作 hash hset myhash name cxx hget myhash name hmset myhash name cxx age 25 note "i am notes" hmget myhash name age note hgetall myhash 获取所有的 hexists myhash name 是否存在 hsetnx myhash score 100 设置不存在的 hincrby myhash id 1 递增 hdel myhash name 删除 hkeys myhash 只取key hvals myhash 只取value hlen myhash 长度 list lpush mylist a b c 左插入 rpush mylist x y z 右插入 lrange mylist 0 -1 数据集合 lpop mylist 弹出元素 rpop mylist 弹出元素 llen mylist 长度 lrem mylist count value 删除 lindex mylist 2 指定索引的值 lset mylist 2 n 索引设值 ltrim mylist 0 4 删除key linsert mylist before a 插入 linsert mylist after a 插入 rpoplpush list list2 转移列表的数据 set sadd myset redis smembers myset 数据集合 srem myset set1 删除 sismember myset set1 判断元素是否在集合中 scard key_name 个数 sdiff | sinter | sunion 操作:集合间运算:差集 | 交集 | 并集 srandmember 随机获取集合中的元素 spop 从集合中弹出一个元素 zset zadd zset 1 one zadd zset 2 two zadd zset 3 three zincrby zset 1 one 增长分数 zscore zset two 获取分数 zrange zset 0 -1 withscores 范围值 zrangebyscore zset 10 25 withscores 指定范围的值 zrangebyscore zset 10 25 withscores limit 1 2 分页 Zrevrangebyscore zset 10 25 withscores 指定范围的值 zcard zset 元素数量 Zcount zset 获得指定分数范围内的元素个数 Zrem zset one two 删除一个或多个元素 Zremrangebyrank zset 0 1 按照排名范围删除元素 Zremrangebyscore zset 0 1 按照分数范围删除元素 Zrank zset 0 -1 分数最小的元素排名为0 Zrevrank zset 0 -1 分数最大的元素排名为0 Zinterstore zunionstore rank:last_week 7 rank:20150323 rank:20150324 rank:20150325 weights 1 1 1 1 1 1 1 排序: sort mylist 排序 sort mylist alpha desc limit 0 2 字母排序 sort list by it:* desc by命令 sort list by it:* desc get it:* get参数 sort list by it:* desc get it:* store sorc:result sort命令之store参数:表示把sort查询的结果集保存起来 订阅与发布: 订阅频道:subscribe chat1 发布消息:publish chat1 "hell0 ni hao" 查看频道:pubsub channels 查看某个频道的订阅者数量: pubsub numsub chat1 退订指定频道: unsubscrible chat1 , punsubscribe java.* 订阅一组频道: psubscribe java.* redis事物: 隔离性,原子性, 步骤: 开始事务,执行命令,提交事务 multi //开启事务 sadd myset a b c sadd myset e f g lpush mylist aa bb cc lpush mylist dd ff gg 服务器管理 dump.rdb appendonly.aof //BgRewriteAof 异步执行一个aop(appendOnly file)文件重写 会创建当前一个AOF文件体积的优化版本 //BgSave 后台异步保存数据到磁盘,会在当前目录下创建文件dump.rdb //save同步保存数据到磁盘,会阻塞主进程,别的客户端无法连接 //client kill 关闭客户端连接 //client list 列出所有的客户端 //给客户端设置一个名称 client setname myclient1 client getname config get port //configRewrite 对redis的配置文件进行改写 rdb save 900 1 save 300 10 save 60 10000 aop备份处理 appendonly yes 开启持久化 appendfsync everysec 每秒备份一次 命令: bgsave异步保存数据到磁盘(快照保存) lastsave返回上次成功保存到磁盘的unix的时间戳 shutdown同步保存到服务器并关闭redis服务器 bgrewriteaof文件压缩处理(命令)
Redis 的持久化机制有两种,第一种是快照,第二种是 AOF 日志。快照是一次全量备份,AOF 日志是连续的增量备份。快照是内存数据的二进制序列化形式,在存储上非常紧凑,而 AOF 日志记录的是内存数据修改的指令记录文本。AOF 日志在长期的运行过程中会变的无比庞大,数据库重启时需要加载 AOF 日志进行指令重放,这个时间就会无比漫长。所以需要定期进行 AOF 重写,给 AOF 日志进行瘦身。
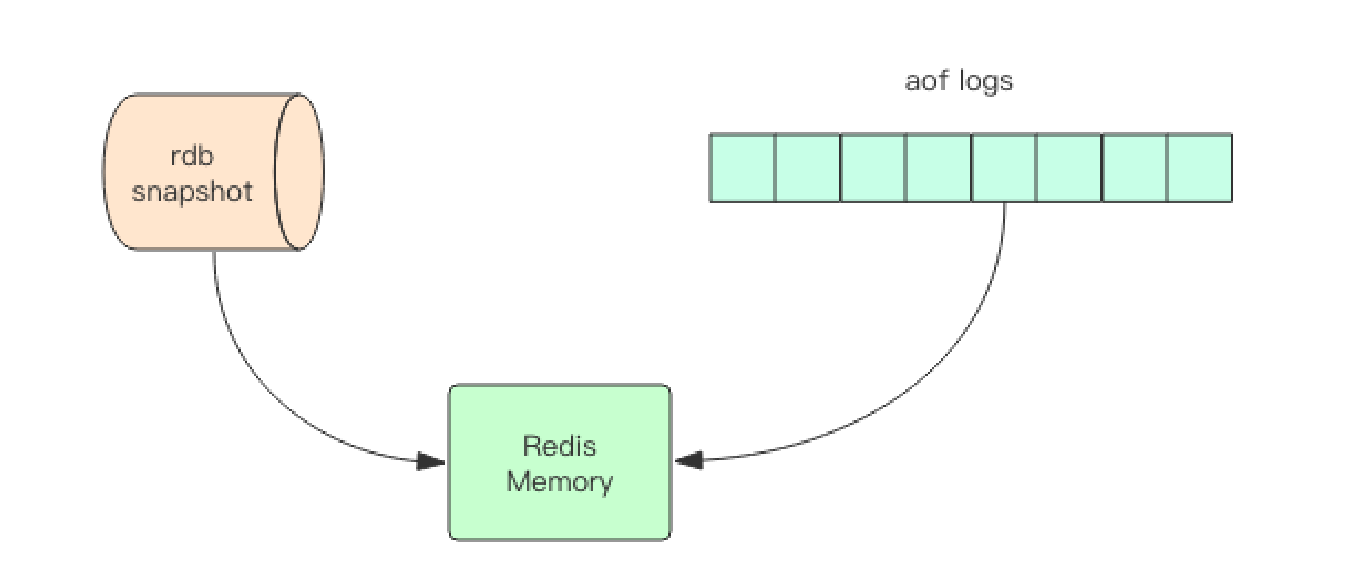
Redis 使用操作系统的多进程 COW(Copy On Write) 机制来实现快照持久化。
Redis 在持久化时会调用 glibc 的函数 fork 产生一个子进程,快照持久化完全交给子进程来处理,父进程继续处理客户端请求。子进程刚刚产生时,它和父进程共享内存里面的代码段和数据段。子进程做数据持久化,它不会修改现有的内存数据结构,它只是对数据结构进行遍历读取,然后序列化写到磁盘中。但是父进程不一样,它必须持续服务客户端请求,然后对内存数据结构进行不间断的修改。子进程因为数据没有变化,它能看到的内存里的数据在进程产生的一瞬间就凝固了,再也不会改变,这也是为什么 Redis 的持久化叫「快照」的原因。
AOF 日志存储的是 Redis 服务器的顺序指令序列,AOF 日志只记录对内存进行修改的指令记录。
Redis 会在收到客户端修改指令后,先进行参数校验,如果没问题,就立即将该指令文本存储到 AOF 日志中,也就是先存到磁盘,然后再执行指令。这样即使遇到突发宕机,已经存储到 AOF 日志的指令进行重放一下就可以恢复到宕机前的状态。
Redis 提供了 bgrewriteaof 指令用于对 AOF 日志进行瘦身。其原理就是开辟一个子进程对内存进行遍历转换成一系列 Redis 的操作指令,序列化到一个新的 AOF 日志文件中。序列化完毕后再将操作期间发生的增量 AOF 日志追加到这个新的 AOF 日志文件中,追加完毕后就立即替代旧的 AOF 日志文件了,瘦身工作就完成了。
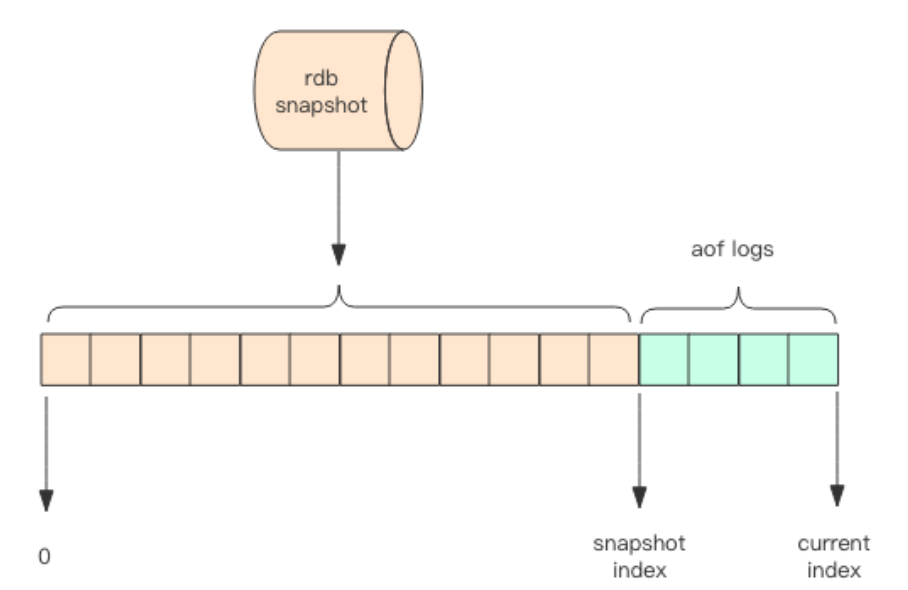
重启 Redis 时,rdb 恢复会丢失大量数据。重放 AOF 日志性能相对 rdb 来说要慢很多。Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。将 rdb 文
件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是自持久化开始到持久化结束的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小。于是在 Redis 重启的时候,可以先加载 rdb 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,重启效率因此大幅得到提升。
非原子性、只是对多命令的打包(事务的四大特性:原子性、隔开性、一致性、持久性)。watch乐观锁。
> multi OK > incr books QUEUED > incr books QUEUED > exec (integer) 1 (integer) 2
所有的指令在 exec 之前不执行,而是缓存在服务器的一个事务队列中,服务器一旦收到 exec 指令,才开执行整个事务队列,执行完毕后一次性返回所有指令的运行结果。
redis的事务不是原子性的:
> multi OK > set books iamastring QUEUED > incr books QUEUED > set poorman iamdesperate QUEUED > exec 1) OK 2) (error) ERR value is not an integer or out of range 3) OK > get books "iamastring" > get poorman "iamdesper
考虑到一个业务场景,Redis 存储了我们的账户余额数据,它是一个整数。现在有两个并发的客户端要对账户余额进行修改操作,这个修改不是一个简单的 incrby 指令,而是要对余额乘以一个倍数。Redis 可没有提供 multiplyby 这样的指令。我们需要先取出余额然后在内存里乘以倍数,再将结果写回 Redis。
Redis 提供了这种 watch 的机制,它就是一种乐观锁。
watch 会在事务开始之前盯住 1 个或多个关键变量,当事务执行时,也就是服务器收到了 exec 指令要顺序执行缓存的事务队列时,Redis 会检查关键变量自 watch 之后,是否被修改了 (包括当前事务所在的客户端)。如果关键变量被人动过了,exec 指令就会返回 null回复告知客户端事务执行失败,这个时候客户端一般会选择重试
# -*- coding: utf-8 import redis def key_for(user_id): return "account_{}".format(user_id) def double_account(client, user_id): key = key_for(user_id) while True: client.watch(key) value = int(client.get(key)) value *= 2 # 加倍 pipe = client.pipeline(transaction=True) pipe.multi() pipe.set(key, value) try: pipe.execute() break # 总算成功了 except redis.WatchError: continue # 事务被打断了,重试 return int(client.get(key)) # 重新获取余额 client = redis.StrictRedis() user_id = "abc" client.setnx(key_for(user_id), 5) # setnx 做初始化 print double_account(client, user_id)
from redis import Redis REDISDB = Redis("127.0.0.1",6379,db=8)
from setting import REDISDB # 存储 - 未读 和 离线 消息数量 def set_chat(to_user,from_user): my_world = REDISDB.get(to_user) if not my_world: setchat = {from_user: 1} setchat_json = json.dumps(setchat) else: my_world_dict = json.loads(my_world) if my_world_dict.get(from_user): my_world_dict[from_user] += 1 else: my_world_dict[from_user] = 1 setchat_json = json.dumps(my_world_dict) REDISDB.set(to_user,setchat_json)
#redis存储session(flask框架) from flask import session, Flask from flask_session import Session from redis import Redis app = Flask(__name__) app.config["SESSION_TYPE"] = "redis" app.config["SESSION_REDIS"] = Redis("127.0.0.1",6379,db=15) Session(app) @app.route("/login") def login(): session["key"] = "value" return "已经创建了session" @app.route("/look") def look(): return session.get("key") if __name__ == '__main__': app.run()

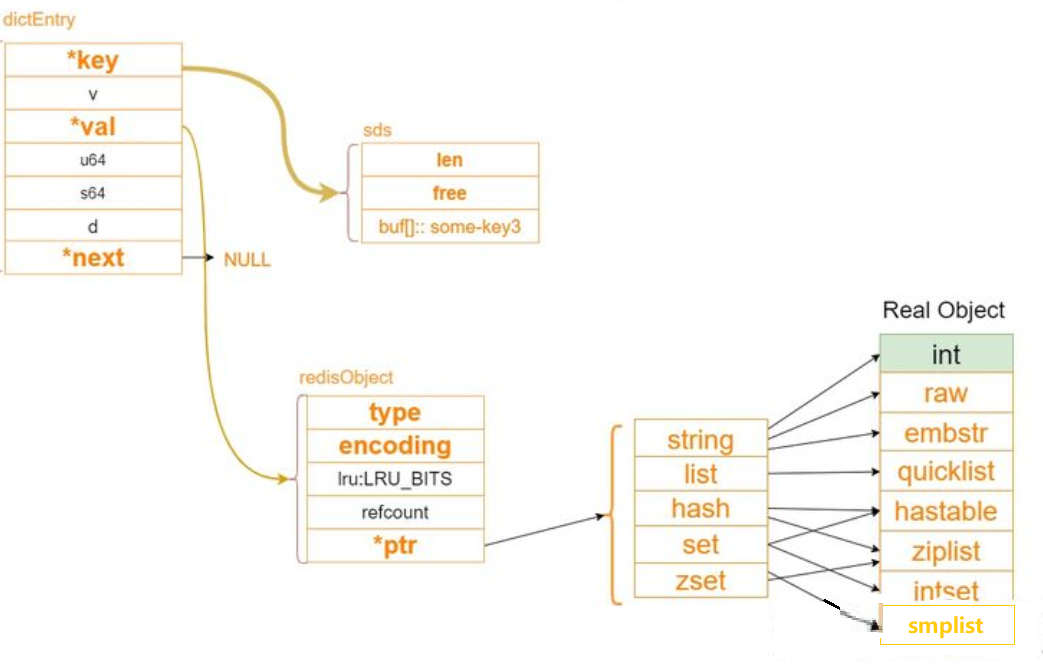
Redis 所有的数据结构都是以唯一的 key字符串作为名称,然后通过这个唯一 key 值来获取相应的 value 数据。不同类型的数据结构的差异就在于 value 的结构不一样。
1、create if not exists。如果容器不存在,那就创建一个,再进行操作。比如 rpush 操作刚开始是没有列表的,Redis 就会自动创建一个,然后再 rpush 进去新元素。
2 、drop if no elements。如果容器里元素没有了,那么立即删除元素,释放内存。这意味着 lpop 操作到最后一个元素,列表就消失了。
过期时间:Redis 所有的数据结构都可以设置过期时间,时间到了,Redis 会自动删除相应的对象。
Redis 的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于 Java 的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。
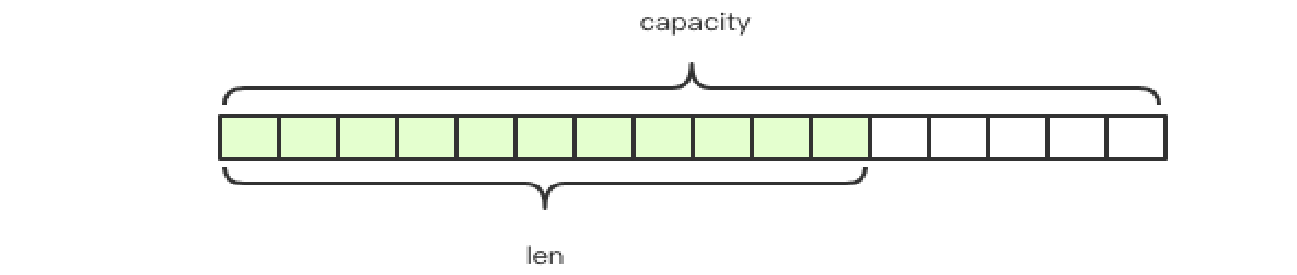
Redis 中的字符串是可以修改的字符串,叫「SDS」,也就是 Simple Dynamic String。它的结构是一个带长度信息的字节数组。
struct SDS<T> { T capacity; // 数组容量 T len; // 数组长度 byte flags; // 特殊标识位,不理睬它 byte[] content; // 数组内容 }
content:存储了真正的字符串内容;capacity:表示所分配数组的长度;len :表示字符串的实际长度。
上面的 SDS 结构使用了范型 T,不同长度的字符串使用不同的结构体来表示。在长度特别短时,使用 emb 形式存储 (embeded),当长度超过 44 时,使用 raw 形式存储。Redis 字符串最大长度 512M 字节,创建字符串时 len 和 capacity 一样长,因为一般不会使用 append 操作来修改字符串。
Redis 对象头结构体,所有的 Redis 对象都有下面的这个结构头:
struct RedisObject { int4 type; // 4bits int4 encoding; // 4bits int24 lru; // 24bits int32 refcount; // 4bytes void *ptr; // 8bytes,64-bit system } robj;
ptr 指针将指向对象内容 (body) 的具体存储位置。这样一个 RedisObject 对象头需要占据 16 字节的存储空间。

redis列表底层存储的是称之为快速链表 quicklist 的一个结构。
list数据的命令行操作:


右边进左边出:队列 > rpush books python java golang (integer) 3 > llen books (integer) 3 > lpop books "python" > lpop books "java" > lpop books "golang" > lpop books (nil) 右边进右边出:栈 > rpush books python java golang (integer) 3 > rpop books "golang" > rpop books "java" > rpop books "python" > rpop books (nil) 慢操作 > rpush books python java golang (integer) 3 > lindex books 1 # O(n) 慎用 "java" > lrange books 0 -1 # 获取所有元素,O(n) 慎用 1) "python" 2) "java" 3) "golang" > ltrim books 1 -1 # O(n) 慎用 OK > lrange books 0 -1 1) "java" 2) "golang" > ltrim books 1 0 # 这其实是清空了整个列表,因为区间范围长度为负 OK > llen books (integer) 0
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成 quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间,而且会加重内存的碎片化。比如这个列表里存的只是 int 类型的数据,结构上还需要两个额外的指针 prev 和 next 。所以 Redis 将链表和 ziplist 结合起来组成了 quicklist。也就是将多个ziplist 使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余
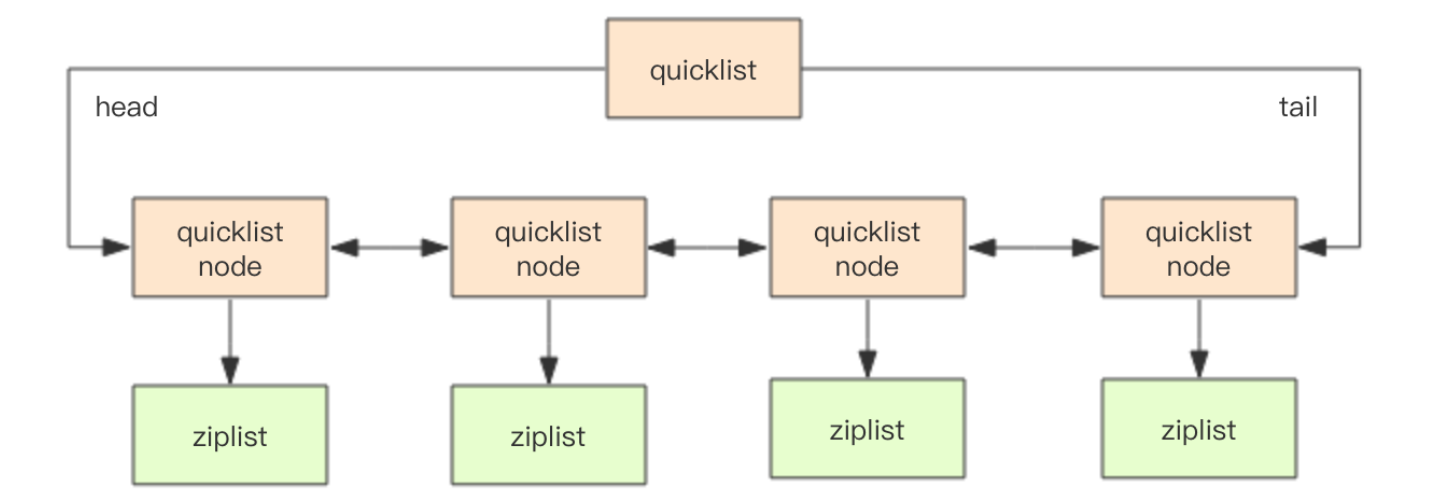
源码:
struct ziplist { ... } struct ziplist_compressed { int32 size; byte[] compressed_data; } struct quicklistNode { quicklistNode* prev; quicklistNode* next; ziplist* zl; // 指向压缩列表 int32 size; // ziplist 的字节总数 int16 count; // ziplist 中的元素数量 int2 encoding; // 存储形式 2bit,原生字节数组还是 LZF 压缩存储 ... } struct quicklist { quicklistNode* head; quicklistNode* tail; long count; // 元素总数 int nodes; // ziplist 节点的个数 int compressDepth; // LZF 算法压缩深度 ... }
quicklist 内部默认单个 ziplist 长度为 8k 字节,超出了这个字节数,就会新起一个ziplist。ziplist 的长度由配置参数 list-max-ziplist-size 决定。
Redis 的字典采用数组 + 链表二维结构。rehash采用渐进式策略。
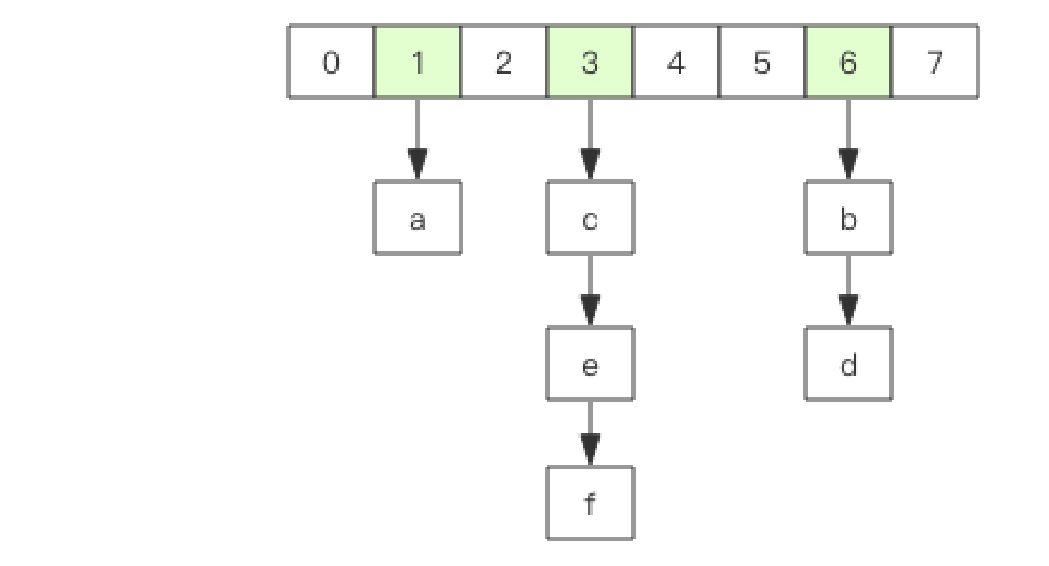
渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个hash 结构,然后在后续的定时任务中以及 hash 的子指令中,循序渐进地将旧 hash 的内容一点点迁移到新的 hash 结构中。
hash 结构也可以用来存储用户信息,不同于字符串一次性需要全部序列化整个对象,hash 可以对用户结构中的每个字段单独存储。这样当我们需要获取用户信息时可以进行部分获取。而以整个字符串的形式去保存用户信息的话就只能一次性全部读取,这样就会比较浪费网络流量。
hash数据的命令行操作:
> hset books java "think in java" # 命令行的字符串如果包含空格,要用引号括起来 (integer) 1 > hset books golang "concurrency in go" (integer) 1 > hset books python "python cookbook" (integer) 1 > hgetall books # entries(),key 和 value 间隔出现 1) "java" 2) "think in java" 3) "golang" 4) "concurrency in go" 5) "python" 6) "python cookbook" > hlen books (integer) 3 > hget books java "think in java" > hset books golang "learning go programming" # 因为是更新操作,所以返回 0 (integer) 0 > hget books golang "learning go programming" > hmset books java "effective java" python "learning python" golang "modern golang programming" # 批量 set OK
第一维是数组,第二维是链表。数组中存储的是第二维链表的第一个元素的指针。
源码:
struct dictEntry { void* key; void* val; dictEntry* next; // 链接下一个 entry } struct dictht { dictEntry** table; // 二维 long size; // 第一维数组的长度 long used; // hash 表中的元素个数 ... }
渐进式 rehash
大字典的扩容是比较耗时间的,需要重新申请新的数组,然后将旧字典所有链表中的元素重新挂接到新的数组下面,这是一个 O(n)级别的操作,作为单线程的 Redis 表示很难承受这样耗时的过程。步子迈大了会扯着蛋,所以 Redis 使用渐进式 rehash 小步搬迁。
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing) { long index; dictEntry *entry; dictht *ht; // 这里进行小步搬迁 if (dictIsRehashing(d)) _dictRehashStep(d); /* Get the index of the new element, or -1 if * the element already exists. */ if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1) return NULL; /* Allocate the memory and store the new entry. * Insert the element in top, with the assumption that in a database * system it is more likely that recently added entries are accessed * more frequently. */ // 如果字典处于搬迁过程中,要将新的元素挂接到新的数组下面 ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; entry = zmalloc(sizeof(*entry)); entry->next = ht->table[index]; ht->table[index] = entry; ht->used++; /* Set the hash entry fields. */ dictSetKey(d, entry, key); return entry; }
查找过程
插入和删除操作都依赖于查找,先必须把元素找到,才可以进行数据结构的修改操作。hashtable 的元素是在第二维的链表上,所以首先我们得想办法定位出元素在哪个链表上。
func get(key) { let index = hash_func(key) % size; let entry = table[index]; while(entry != NULL) { if entry.key == target { return entry.value; } entry = entry.next; } }
hash 攻击
如果 hash 函数存在偏向性,黑客就可能利用这种偏向性对服务器进行攻击。存在偏向性的 hash 函数在特定模式下的输入会导致 hash 第二维链表长度极为不均匀,甚至所有的元素都集中到个别链表中,直接导致查找效率急剧下降,从 O(1)退化到 O(n)。有限的服务器计算能力将会被 hashtable 的查找效率彻底拖垮。这就是所谓 hash 攻击。
扩容条件源码:
/* Expand the hash table if needed */ static int _dictExpandIfNeeded(dict *d) { /* Incremental rehashing already in progress. Return. */ if (dictIsRehashing(d)) return DICT_OK; /* If the hash table is empty expand it to the initial size. */ if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); /* If we reached the 1:1 ratio, and we are allowed to resize the hash * table (global setting) or we should avoid it but the ratio between * elements/buckets is over the "safe" threshold, we resize doubling * the number of buckets. */ if (d->ht[0].used >= d->ht[0].size && (dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) { return dictExpand(d, d->ht[0].used*2); } return DICT_OK; }
正常情况下,当 hash 表中元素的个数等于第一维数组的长度时,就会开始扩容,扩容的新数组是原数组大小的 2 倍。不过如果 Redis 正在做 bgsave,为了减少内存页的过多分离 (Copy On Write),Redis 尽量不去扩容 (dict_can_resize),但是如果 hash 表已经非常满了,元素的个数已经达到了第一维数组长度的 5 倍 (dict_force_resize_ratio),说明 hash 表已经过于拥挤了,这个时候就会强制扩容。
Redis 的集合相当于 Java 语言里面的 HashSet,它内部的键值对是无序的唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值 NULL。
set的命令行操作:
> sadd books python (integer) 1 > sadd bookspython # 重复 (integer) 0 > sadd books java golang (integer) 2 > smembers books # 注意顺序,和插入的并不一致,因为 set 是无序的 1) "java" 2) "python" 3) "golang" > sismember books java # 查询某个 value 是否存在,相当于 contains(o) (integer) 1 > sismember books rust (integer) 0 > scard books # 获取长度相当于 count() (integer) 3 > spop books # 弹出一个 "java"
zset 可能是 Redis 提供的最为特色的数据结构,它的内部实现用的是一种叫着「跳跃列表」的数据结构。
zset 还可以用来存储学生的成绩,value 值是学生的 ID,score 是他的考试成绩。
zset的命令行操作:
> zadd books 9.0 "think in java" (integer) 1 > zadd books 8.9 "java concurrency" (integer) 1 > zadd books 8.6 "java cookbook" (integer) 1 > zrange books 0 -1 # 按 score 排序列出,参数区间为排名范围 1) "java cookbook" 2) "java concurrency" 3) "think in java" > zrevrange books 0 -1 # 按 score 逆序列出,参数区间为排名范围 1) "think in java" 2) "java concurrency" 3) "java cookbook" > zcard books # 相当于 count() (integer) 3 > zscore books "java concurrency" # 获取指定 value 的 score "8.9000000000000004" # 内部 score 使用 double 类型进行存储,所以存在小数点精度问题 > zrank books "java concurrency" # 排名 (integer) 1 > zrangebyscore books 0 8.91 # 根据分值区间遍历 zset 1) "java cookbook" 2) "java concurrency" > zrangebyscore books -inf 8.91 withscores # 根据分值区间 (-∞, 8.91] 遍历 zset,同时返 回分值。inf 代表 infinite,无穷大的意思。 1) "java cookbook" 2) "8.5999999999999996" 3) "java concurrency" 4) "8.9000000000000004" > zrem books "java concurrency" # 删除 value (integer) 1 > zrange books 0 -1 1) "java cookbook" 2) "think in java"
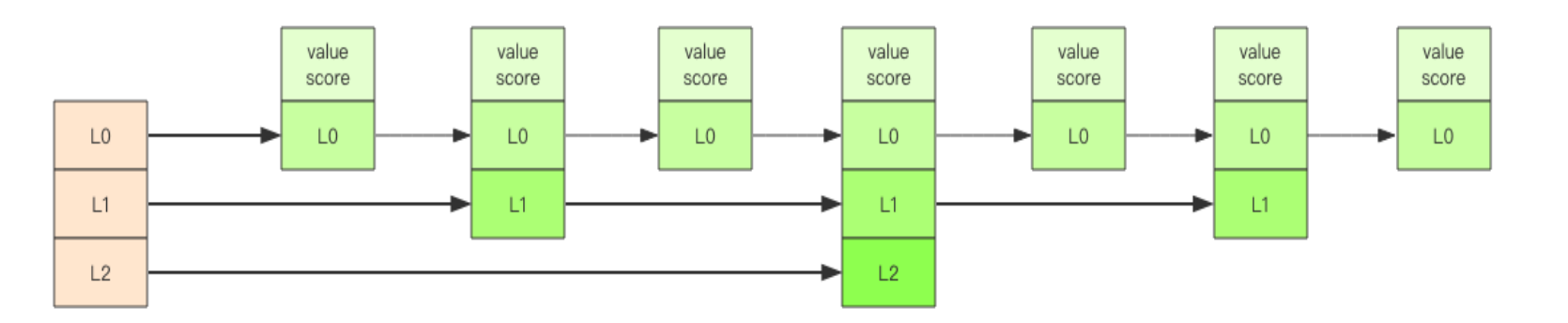
「跳跃列表」之所以「跳跃」,是因为内部的元素可能「身兼数职」,比如上图中间的这个元素,同时处于 L0、L1 和 L2 层,可以快速在不同层次之间进行「跳跃」。
跳跃列表采取一个随机策略来决定新元素可以兼职到第几层。首先 L0 层肯定是 100% 了,L1 层只有 50% 的概率,L2 层只有 25% 的概率,L3层只有 12.5% 的概率,一直随机到最顶层 L31 层。绝大多数元素都过不了几层,只有极少数元素可以深入到顶层。列表中的元素越多,能够深入的层次就越深,能进入到顶层的概率就会越大。
基本结构

上图就是跳跃列表的示意图,图中只画了四层,Redis 的跳跃表共有 64 层,意味着最多可以容纳 2^64 次方个元素。每一个 kv 块对应的结构如下面的代码中的 zslnode 结构,kv header 也是这个结构,只不过 value 字段是 null 值——无效的,score 是Double.MIN_VALUE,用来垫底的。kv 之间使用指针串起来形成了双向链表结构,它们是有序 排列的,从小到大。不同的 kv 层高可能不一样,层数越高的 kv 越少。同一层的 kv会使用指针串起来。每一个层元素的遍历都是从 kv header 出发。
源码:
struct zslnode { string value; double score; zslnode*[] forwards; // 多层连接指针 zslnode* backward; // 回溯指针 } struct zsl { zslnode* header; // 跳跃列表头指针 int maxLevel; // 跳跃列表当前的最高层 map<string, zslnode*> ht; // hash 结构的所有键值对 }
查找过程
一般链表的查找时间复杂度为O(n),跳跃列表有了多层结构之后,这个定位的算法复杂度将会降到O(lg(n))。
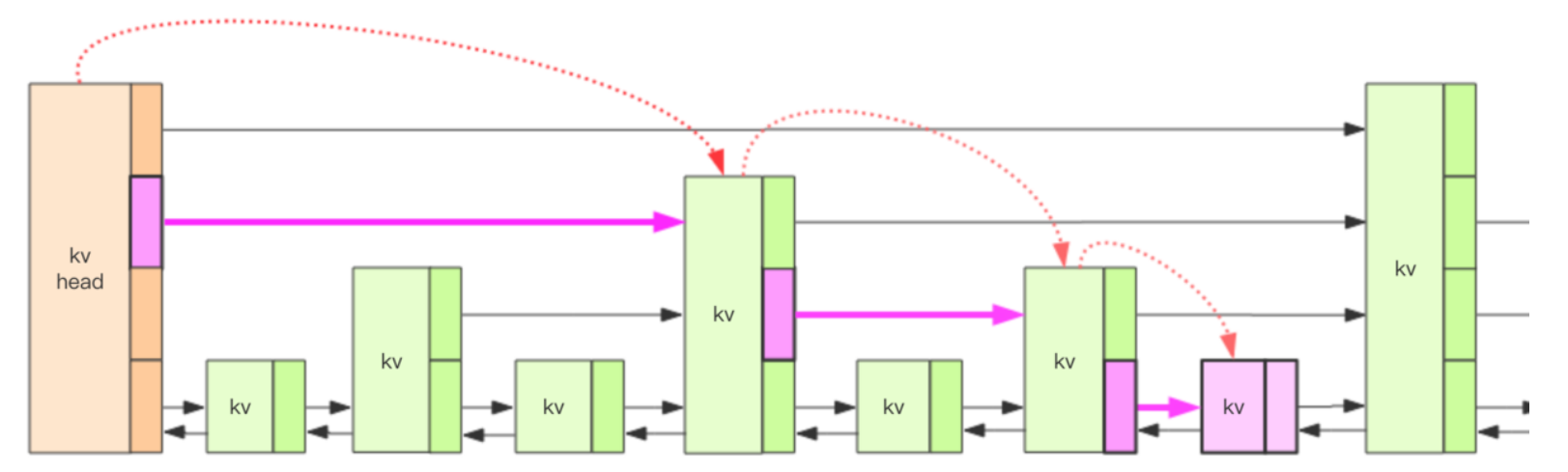
如图所示,我们要定位到那个紫色的 kv,需要从 header 的最高层开始遍历找到第一个节点 (最后一个比「我」小的元素),然后从这个节点开始降一层再遍历找到第二个节点 (最后一个比「我」小的元素),然后一直降到最底层进行遍历就找到了期望的节点 (最底层的最后一个比我「小」的元素)。
插入过程的源码:
/* Insert a new node in the skiplist. Assumes the element does not already * exist (up to the caller to enforce that). The skiplist takes ownership * of the passed SDS string 'ele'. */ zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) { // 存储搜索路径 zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; // 存储经过的节点跨度 unsigned int rank[ZSKIPLIST_MAXLEVEL]; int i, level; serverAssert(!isnan(score)); x = zsl->header; // 逐步降级寻找目标节点,得到「搜索路径」 for (i = zsl->level-1; i >= 0; i--) { /* store rank that is crossed to reach the insert position */ rank[i] = i == (zsl->level-1) ? 0 : rank[i+1]; // 如果 score 相等,还需要比较 value while (x->level[i].forward && (x->level[i].forward->score < score || (x->level[i].forward->score == score && sdscmp(x->level[i].forward->ele,ele) < 0))) { rank[i] += x->level[i].span; x = x->level[i].forward; } update[i] = x; } // 正式进入插入过程 /* we assume the element is not already inside, since we allow duplicated * scores, reinserting the same element should never happen since the * caller of zslInsert() should test in the hash table if the element is * already inside or not. */ // 随机一个层数 level = zslRandomLevel(); // 填充跨度 if (level > zsl->level) { for (i = zsl->level; i < level; i++) { rank[i] = 0; update[i] = zsl->header; update[i]->level[i].span = zsl->length; } // 更新跳跃列表的层高 zsl->level = level; } // 创建新节点 x = zslCreateNode(level,score,ele); // 重排一下前向指针 for (i = 0; i < level; i++) { x->level[i].forward = update[i]->level[i].forward; update[i]->level[i].forward = x; /* update span covered by update[i] as x is inserted here */ x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]); update[i]->level[i].span = (rank[0] - rank[i]) + 1; } /* increment span for untouched levels */ for (i = level; i < zsl->level; i++) { update[i]->level[i].span++; } // 重排一下后向指针 x->backward = (update[0] == zsl->header) ? NULL : update[0]; if (x->level[0].forward) x->level[0].forward->backward = x; else zsl->tail = x; zsl->length++; return x; }
aaa

 浙公网安备 33010602011771号
浙公网安备 33010602011771号