数据库之MySQL篇
数据库定义语言: 数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER
数据库控制语言: 例如控制用户的访问权限GRANT、REVOKE
数据库操纵语言: 插入数据INSERT、删除数据DELETE、更新数据UPDATE、查询数据SELECT(单表查询、多表查询)
1、MySQL存储引擎
mysql5.6支持的存储引擎包括InnoDB、MyISAM、MEMORY、CSV、BLACKHOLE、FEDERATED、MRG_MYISAM、ARCHIVE、PERFORMANCE_SCHEMA。其中NDB和InnoDB提供事务安全表,其他存储引擎都是非事务安全表。
InnoDB
用于事务处理应用程序,支持外键和行级锁。如果应用对事物的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包括很多更新和删除操作,那么InnoDB存储引擎是比较合适的。InnoDB除了有效的降低由删除和更新导致的锁定,还可以确保事务的完整提交和回滚,对于类似计费系统或者财务系统等对数据准确要求性比较高的系统都是合适的选择。
MyISAM
如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不高,那么可以选择这个存储引擎。
Memory
将所有的数据保存在内存中,在需要快速定位记录和其他类似数据的环境下,可以提供极快的访问。Memory的缺陷是对表的大小有限制,虽然数据库因为异常终止的话数据可以正常恢复,但是一旦数据库关闭,存储在内存中的数据都会丢失。
存储引擎在mysql中的使用
查询:

查看当前的默认存储引擎: mysql> show variables like "default_storage_engine"; 查询当前数据库支持的存储引擎 mysql> show engines \G;
指定:
mysql> create table ai(id bigint(12),name varchar(200)) ENGINE=MyISAM; mysql> create table country(id int(4),cname varchar(50)) ENGINE=InnoDB; 也可以使用alter table语句,修改一个已经存在的表的存储引擎。 mysql> alter table ai engine = innodb;
在配置文件中指定
#my.ini文件 [mysqld] default-storage-engine=INNODB
2、MySQL工作流程
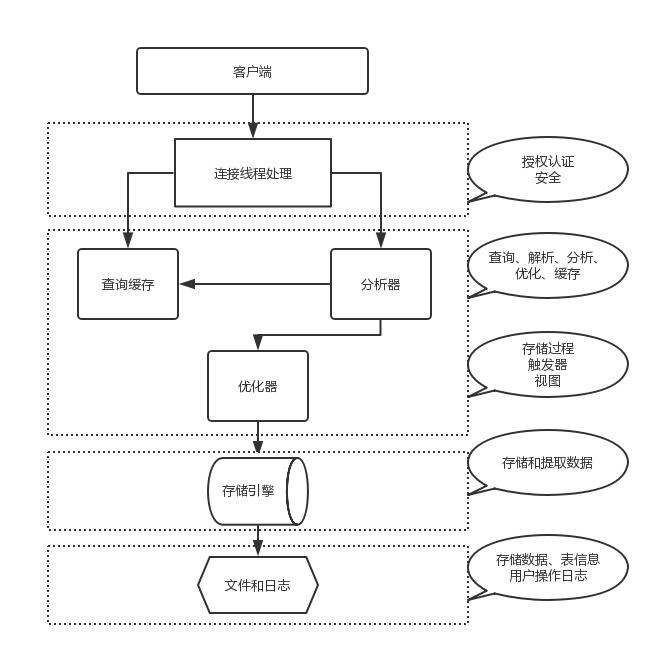
MySQL架构总共四层,在上图中以虚线作为划分。
首先,最上层的服务并不是MySQL独有的,大多数给予网络的客户端/服务器的工具或者服务都有类似的架构。比如:连接处理、授权认证、安全等。
第二层的架构包括大多数的MySQL的核心服务。包括:查询解析、分析、优化、缓存以及所有的内置函数(例如:日期、时间、数学和加密函数)。同时,所有的跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。
第三层包含了存储引擎。存储引擎负责MySQL中数据的存储和提取。服务器通过API和存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明化。存储引擎API包含十几个底层函数,用于执行“开始一个事务”等操作。但存储引擎一般不会去解析SQL(InnoDB会解析外键定义,因为其本身没有实现该功能),不同存储引擎之间也不会相互通信,而只是简单的响应上层的服务器请求。
第四层包含了文件系统,所有的表结构和数据以及用户操作的日志最终还是以文件的形式存储在硬盘上。
#进入mysql客户端 $mysql mysql> select user(); #查看当前用户 mysql> exit # 也可以用\q quit退出 # 默认用户登陆之后并没有实际操作的权限 # 需要使用管理员root用户登陆 $ mysql -uroot -p # mysql5.6默认是没有密码的 #遇到password直接按回车键 mysql> set password = password('root'); # 给当前数据库设置密码 # 创建账号 mysql> create user 'lv'@'192.168.10.%' IDENTIFIED BY '123';# 指示网段 mysql> create user 'lv'@'192.168.10.5' # 指示某机器可以连接 mysql> create user 'lv'@'%' #指示所有机器都可以连接 mysql> show grants for 'lv'@'192.168.10.5';查看某个用户的权限 # 远程登陆 $ mysql -uroot -p123 -h 192.168.10.3 # 给账号授权 mysql> grant all on *.* to 'lv'@'%'; mysql> flush privileges; # 刷新使授权立即生效 # 创建账号并授权 mysql> grant all on *.* to 'lv'@'%' identified by '123'
1. 操作文件夹(库) 增:create database db1 charset utf8; 查:show databases; 改:alter database db1 charset latin1; 删除: drop database db1; 2. 操作文件(表) 先切换到文件夹下:use db1 增:create table t1(id int,name char); 查:show tables; 改:alter table t1 modify name char(3); alter table t1 change name name1 char(2); 删:drop table t1;
简单的增删改查语句:
增:insert into t1 values(1,'egon1'),(2,'egon2'),(3,'egon3'); 查:select * from t1; 改:update t1 set name='sb' where id=2; 删:delete from t1 where id=1; 清空表: delete from t1; #如果有自增id,新增的数据,仍然是以删除前的最后一样作为起始。 truncate table t1;数据量大,删除速度比上一条快,且直接从零开始, *auto_increment 表示:自增 *primary key 表示:约束(不能重复且不能为空);加速查找
1. 插入完整数据(顺序插入) 语法一: INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES(值1,值2,值3…值n); 语法二: INSERT INTO 表名 VALUES (值1,值2,值3…值n); 2. 指定字段插入数据 语法: INSERT INTO 表名(字段1,字段2,字段3…) VALUES (值1,值2,值3…); 3. 插入多条记录 语法: INSERT INTO 表名 VALUES (值1,值2,值3…值n), (值1,值2,值3…值n), (值1,值2,值3…值n); 4. 插入查询结果 语法: INSERT INTO 表名(字段1,字段2,字段3…字段n) SELECT (字段1,字段2,字段3…字段n) FROM 表2 WHERE …;
示例:
mysql> insert into staff_info values (3,'nezha',25,'male',13332353222,'IT'),(4,'boss_jin',40,'male',13332353333,'IT');
语法: DELETE FROM 表名 WHERE CONITION; 示例: DELETE FROM mysql.user WHERE password=’’;
单条删除
delete from user where id=998;
多条语句删除
delete user,details from user,details where `user`.id=details.id and `user`.id=996;
delete from user,details where `user`.id=details.id and `user`.id=995;语法: UPDATE 表名 SET 字段1=值1, 字段2=值2, WHERE CONDITION; 示例: UPDATE mysql.user SET password=password(‘123’) where user=’root’ and host=’localhost’;
单表查询语法
SELECT 字段1,字段2... FROM 表名
WHERE 条件
GROUP BY field
HAVING 筛选
ORDER BY field
LIMIT 限制条数
关键字执行的优先级
from where group by select distinct having order by limit
1.找到表:from
2.拿着where指定的约束条件,去文件/表中取出一条条记录
3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组
4.执行select(去重)
5.将分组的结果进行having过滤
6.将结果按条件排序:order by
7.限制结果的显示条数
普通查询
#简单查询 SELECT * FROM employee; SELECT emp_name,salary FROM employee; #避免重复DISTINCT SELECT DISTINCT post FROM employee; #通过四则运算查询 SELECT emp_name, salary*12 FROM employee; #定义显示格式 CONCAT() 函数用于连接字符串 SELECT CONCAT('姓名: ',emp_name,' 年薪: ', salary*12) AS Annual_salary FROM employee; CONCAT_WS() 第一个参数为分隔符 SELECT CONCAT_WS(':',emp_name,salary*12) AS Annual_salary FROM employee; 结合CASE语句: SELECT ( CASE WHEN emp_name = 'jingliyang' THEN emp_name WHEN emp_name = 'alex' THEN CONCAT(emp_name,'_BIGSB') ELSE concat(emp_name, 'SB') END ) as new_name FROM employee;
where约束 SELECT emp_name,salary FROM employee WHERE post='teacher' AND salary>10000; 关键字BETWEEN AND SELECT emp_name,salary FROM employee WHERE salary BETWEEN 10000 AND 20000; 关键字IS NULL(判断某个字段是否为NULL不能用等号,需要用IS) SELECT emp_name,post_comment FROM employee WHERE post_comment IS NULL; 关键字IN集合查询 SELECT emp_name,salary FROM employee WHERE salary=3000 OR salary=3500 OR salary=4000 OR salary=9000 ; 关键字LIKE模糊查询 通配符’%’ SELECT * FROM employee WHERE emp_name LIKE 'eg%';
GROUP BY 单独使用GROUP BY关键字分组 SELECT post FROM employee GROUP BY post; 注意:我们按照post字段分组,那么select查询的字段只能是post,想要获取组内的其他相关信息,需要借助函数 GROUP BY关键字和GROUP_CONCAT()函数一起使用 SELECT post,GROUP_CONCAT(emp_name) FROM employee GROUP BY post;#按照岗位分组,并查看组内成员名 SELECT post,GROUP_CONCAT(emp_name) as emp_members FROM employee GROUP BY post; GROUP BY与聚合函数一起使用 select post,count(id) as count from employee group by post;#按照岗位分组,并查看每个组有多少人
聚合函数 #强调:聚合函数聚合的是组的内容,若是没有分组,则默认一组 示例: SELECT COUNT(*) FROM employee; SELECT COUNT(*) FROM employee WHERE depart_id=1; SELECT MAX(salary) FROM employee; SELECT MIN(salary) FROM employee; SELECT AVG(salary) FROM employee; SELECT SUM(salary) FROM employee; SELECT SUM(salary) FROM employee WHERE depart_id=3;
HAVING过滤 HAVING与WHERE不一样的地方在于: #!!!执行优先级从高到低:where > group by > having #1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。 #2. Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数
ORDER BY 查询排序 按单列排序 SELECT * FROM employee ORDER BY salary; 按多列排序:先按照age排序,如果年纪相同,则按照薪资排序 SELECT * from employee ORDER BY age, salary DESC;
LIMIT 限制查询的记录数 示例: SELECT * FROM employee ORDER BY salary DESC LIMIT 3; #默认初始位置为0 SELECT * FROM employee ORDER BY salary DESC LIMIT 0,5; #从第0开始,即先查询出第一条,然后包含这一条在内往后查5条
使用正则表达式查询 SELECT * FROM employee WHERE emp_name REGEXP 'on$';
#重点:外链接语法 SELECT 字段列表 FROM 表1 INNER|LEFT|RIGHT JOIN 表2 ON 表1.字段 = 表2.字段;
交叉连接:不适用任何匹配条件。生成笛卡尔积 mysql> select * from employee,department; 内连接:只连接匹配的行 mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee inner join department on employee.dep_id=department.id; 外链接之左连接:优先显示左表全部记录 mysql> select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id; 外链接之右连接:优先显示右表全部记录 mysql> select employee.id,employee.name,department.name as depart_name from employee right join department on employee.dep_id=department.id; 全外连接:显示左右两个表全部记录 #注意:mysql不支持全外连接 full JOIN #强调:mysql可以使用此种方式间接实现全外连接 select * from employee left join department on employee.dep_id = department.id union select * from employee right join department on employee.dep_id = department.id ;
符合条件连接查询 #示例:以内连接的方式查询employee和department表,并且以age字段的升序方式显示 select employee.id,employee.name,employee.age,department.name from employee,department where employee.dep_id = department.id and age > 25 order by age asc;
子查询 #1:子查询是将一个查询语句嵌套在另一个查询语句中。 #2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。 #3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字 #4:还可以包含比较运算符:= 、 !=、> 、<等 1 带IN关键字的子查询 #查看技术部员工姓名 select name from employee where dep_id in (select id from department where name='技术'); 2 带比较运算符的子查询 #查询大于部门内平均年龄的员工名、年龄 select t1.name,t1.age from emp t1 inner join (select dep_id,avg(age) avg_age from emp group by dep_id) t2 on t1.dep_id = t2.dep_id where t1.age > t2.avg_age; 3 带EXISTS关键字的子查询 mysql> select * from employee -> where exists -> (select id from department where id=200);
1聚集索引与辅助索引
在数据库中,B+树的高度一般都在2~4层,这也就是说查找某一个键值的行记录时最多只需要2到4次IO,这倒不错。因为当前一般的机械硬盘每秒至少可以做100次IO,2~4次的IO意味着查询时间只需要0.02~0.04秒。
数据库中的B+树索引可以分为聚集索引(clustered index)和辅助索引(secondary index),
聚集索引与辅助索引相同的是:不管是聚集索引还是辅助索引,其内部都是B+树的形式,即高度是平衡的,叶子结点存放着所有的数据。
聚集索引与辅助索引不同的是:叶子结点存放的是否是一整行的信息
聚集索引
#InnoDB存储引擎表是索引组织表,即表中数据按照主键顺序存放。
而聚集索引(clustered index)就是按照每张表的主键构造一棵B+树,同时叶子结点存放的即为整张表的行记录数据,也将聚集索引的叶子结点称为数据页。
聚集索引的这个特性决定了索引组织表中数据也是索引的一部分。同B+树数据结构一样,每个数据页都通过一个双向链表来进行链接。 #如果未定义主键,MySQL取第一个唯一索引(unique)而且只含非空列(NOT NULL)作为主键,InnoDB使用它作为聚簇索引。 #如果没有这样的列,InnoDB就自己产生一个这样的ID值,它有六个字节,而且是隐藏的,使其作为聚簇索引。 #由于实际的数据页只能按照一棵B+树进行排序,因此每张表只能拥有一个聚集索引。
在多数情况下,查询优化器倾向于采用聚集索引。因为聚集索引能够在B+树索引的叶子节点上直接找到数据。
此外由于定义了数据的逻辑顺序,聚集索引能够特别快地访问针对范围值得查询。
聚集索引的好处之一:它对主键的排序查找和范围查找速度非常快,叶子节点的数据就是用户所要查询的数据。如用户需要查找一张表,查询最后的10位用户信息,由于B+树索引是双向链表,所以用户可以快速找到最后一个数据页,并取出10条记录
聚集索引的好处之二:范围查询(range query),即如果要查找主键某一范围内的数据,通过叶子节点的上层中间节点就可以得到页的范围,之后直接读取数据页即可。
2、辅助索引
表中除了聚集索引外其他索引都是辅助索引(Secondary Index,也称为非聚集索引),与聚集索引的区别是:辅助索引的叶子节点不包含行记录的全部数据。
叶子节点除了包含键值以外,每个叶子节点中的索引行中还包含一个书签(bookmark)。该书签用来告诉InnoDB存储引擎去哪里可以找到与索引相对应的行数据。
由于InnoDB存储引擎是索引组织表,因此InnoDB存储引擎的辅助索引的书签就是相应行数据的聚集索引键;
辅助索引的存在并不影响数据在聚集索引中的组织,因此每张表上可以有多个辅助索引,但只能有一个聚集索引。当通过辅助索引来寻找数据时,InnoDB存储引擎会遍历辅助索引并通过叶子级别的指针获得只想主键索引的主键,然后再通过主键索引来找到一个完整的行记录。
聚集索引 1.纪录的索引顺序与无力顺序相同 因此更适合between and和order by操作 2.叶子结点直接对应数据 从中间级的索引页的索引行直接对应数据页 3.每张表只能创建一个聚集索引 非聚集索引 1.索引顺序和物理顺序无关 2.叶子结点不直接指向数据页 3.每张表可以有多个非聚集索引,需要更多磁盘和内容 多个索引会影响insert和update的速度
3、索引功能
#1. 索引的功能就是加速查找 #2. mysql中的primary key,unique,联合唯一也都是索引,这些索引除了加速查找以外,还有约束的功能
4、MySQL常用的索引
普通索引INDEX:加速查找 唯一索引: -主键索引PRIMARY KEY:加速查找+约束(不为空、不能重复) -唯一索引UNIQUE:加速查找+约束(不能重复) 联合索引: -PRIMARY KEY(id,name):联合主键索引 -UNIQUE(id,name):联合唯一索引 -INDEX(id,name):联合普通索引
5、创建/删除索引的语法及示例
#方法一:创建表时 CREATE TABLE 表名 ( 字段名1 数据类型 [完整性约束条件…], 字段名2 数据类型 [完整性约束条件…], [UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY [索引名] (字段名[(长度)] [ASC |DESC]) ); #方法二:CREATE在已存在的表上创建索引 CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 ON 表名 (字段名[(长度)] [ASC |DESC]) ; #方法三:ALTER TABLE在已存在的表上创建索引 ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 (字段名[(长度)] [ASC |DESC]) ; #删除索引:DROP INDEX 索引名 ON 表名字;
#方式一 create table t1( id int, name char, age int, sex enum('male','female'), unique key uni_id(id), index ix_name(name) #index没有key ); create table t1( id int, name char, age int, sex enum('male','female'), unique key uni_id(id), index(name) #index没有key ); #方式二 create index ix_age on t1(age); #方式三 alter table t1 add index ix_sex(sex); alter table t1 add index(sex); #查看 mysql> show create table t1; | t1 | CREATE TABLE `t1` ( `id` int(11) DEFAULT NULL, `name` char(1) DEFAULT NULL, `age` int(11) DEFAULT NULL, `sex` enum('male','female') DEFAULT NULL, UNIQUE KEY `uni_id` (`id`), KEY `ix_name` (`name`), KEY `ix_age` (`age`), KEY `ix_sex` (`sex`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1
begin; # 开启事务 select * from emp where id = 1 for update; # 查询id值,for update添加行锁; update emp set salary=10000 where id = 1; # 完成更新 commit; # 提交事务
备份 #语法: # mysqldump -h 服务器 -u用户名 -p密码 数据库名 > 备份文件.sql #示例: #单库备份 mysqldump -uroot -p123 db1 > db1.sql mysqldump -uroot -p123 db1 table1 table2 > db1-table1-table2.sql #多库备份 mysqldump -uroot -p123 --databases db1 db2 mysql db3 > db1_db2_mysql_db3.sql #备份所有库 mysqldump -uroot -p123 --all-databases > all.sql 恢复 #方法一: [root@egon backup]# mysql -uroot -p123 < /backup/all.sql #方法二: mysql> use db1; mysql> SET SQL_LOG_BIN=0; #关闭二进制日志,只对当前session生效 mysql> source /root/db1.sql
废话不多说,直接进入正题
1.安装 Flask-Migrate
pip install Flask-Migrate
2.将 Flask-Migrate 加入到 Flask 项目中 - PS: 注意了 Flask-Migrate 是要依赖 Flask-Script 组件的
1 import MyApp 2 # 导入 Flask-Script 中的 Manager 3 from flask_script import Manager 4 5 # 导入 Flask-Migrate 中的 Migrate 和 MigrateCommand 6 # 这两个东西说白了就是想在 Flask-Script 中添加几个命令和指令而已 7 from flask_migrate import Migrate,MigrateCommand 8 9 app = MyApp.create_app() 10 # 让app支持 Manager 11 manager = Manager(app) # type:Manager 12 13 # Migrate 既然是数据库迁移,那么就得告诉他数据库在哪里 14 # 并且告诉他要支持那个app 15 Migrate(app,MyApp.db) 16 # 现在就要告诉manager 有新的指令了,这个新指令在MigrateCommand 中存着呢 17 manager.add_command("db",MigrateCommand) # 当你的命令中出现 db 指令,则去MigrateCommand中寻找对应关系 18 """ 19 数据库迁移指令: 20 python manager.py db init 21 python manager.py db migrate # Django中的 makemigration 22 python manager.py db upgrade # Django中的 migrate 23 """ 24 25 26 @manager.command 27 def DragonFire(arg): 28 print(arg) 29 30 @manager.option("-n","--name",dest="name") 31 @manager.option("-s","--say",dest="say") 32 def talk(name,say): 33 print(f"{name}你可真{say}") 34 35 if __name__ == '__main__': 36 #app.run() 37 # 替换原有的app.run(),然后大功告成了 38 manager.run()
3.执行数据库初始化指令
python manager.py db init

此后会生成跟Django类似的目录

接下来的操作就和Django中一样了(略)
Django中使用 import pymysql pymysql.install_as_MySQLdb()
python manger.py makemigrations
python manager.py migrate
然后正常Model和ModelForm操作
import pymysql
db = pymysql.connect("数据库ip","用户","密码","数据库" ) # 打开数据库连接
cursor.execute("SELECT VERSION()") # 使用 execute() 方法执行 SQL 查询
data = cursor.fetchone() # 使用 fetchone() 方法获取单条数据
print ("Database version : %s " % data)
db.close() # 关闭数据库连接
备注:更改取出值的类型
cur = conn.cursor(pymysql.cursors.DictCursor) # 设置返回的数据类型是字典
cur = conn.cursor() # 默认返回的数据类型是元组
import pymysql #打开数据库连接 conn = pymysql.connect( host='127.0.0.1', user='root', password="123", database='db1', port=3306, charset='utf8' ) # 创建游标 cur = conn.cursor(pymysql.cursors.DictCursor) #使用execute执行SQL语句 cur.execute(sql,{"name":'lv','sex':'female'}) rets = cur.fetchall() conn.commit() cur.close() conn.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号