并发与网编
1.multiprocessing模块
from multiprocessing import Process #示例1: def son_process(i): print('son start',i) time.sleep(1) print('son end',i) if __name__ == '__main__': for i in range(10): p = Process(target=son_process,args=(i,)) p.start() # 通知操作系统 start并不意味着子进程已经开始了 #示例2:join n = [100] def sub_n(): global n # 子进程对于主进程中的全局变量的修改是不生效的 n.append(1) print('子进程n : ',n) time.sleep(10) print('子进程结束') if __name__ == '__main__': p = Process(target = sub_n) p.start() p.join(timeout = 5) # 如果不设置超时时间 join会阻塞直到子进程p结束 # timeout超时 # 如果设置的超时时间,那么意味着如果不足5s子进程结束了,程序结束阻塞 # 如果超过5s还没有结束,那么也结束阻塞 print('主进程n : ',n) p.terminate() # 也可以强制结束一个子进程
2.进程池
# 回调函数 import os import time import random from multiprocessing import Pool # 池 def func(i): # [2,1,1,5,0,0.2] i -= 1 time.sleep(random.uniform(0,2)) return i**2 def back_func(args): print(args,os.getpid()) if __name__ == '__main__': print(os.getpid()) p = Pool(5) l = [] for i in range(100): ret = p.apply_async(func,args=(i,),callback=back_func) # 5个任务 p.close() p.join() # callback回调函数 # 主动执行func,然后在func执行完毕之后的返回值,直接传递给back_func作为参数,调用back_func # 处理池中任务的返回值 # 回调函数是由谁执行的? 主进程 # 5000个网页 # 5个进程 import re import json from urllib.request import urlopen from multiprocessing import Pool def get_page(i): ret = urlopen('https://movie.douban.com/top250?start=%s&filter='%i).read() ret = ret.decode('utf-8') return ret def parser_page(s): com = re.compile( '<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S) ret = com.finditer(s) with open('file','a',encoding='utf-8') as f: for i in ret: dic = { "id": i.group("id"), "title": i.group("title"), "rating_num": i.group("rating_num"), "comment_num": i.group("comment_num"), } f.write(json.dumps(dic,ensure_ascii=False)+'\n') if __name__ == '__main__': p = Pool(5) count = 0 for i in range(10): p.apply_async(get_page,args=(count,),callback=parser_page) count += 25 p.close() p.join() import json with open('file2','w',encoding='utf-8') as f: json.dump({'你好':'alex'},f,ensure_ascii=False)
线程的特点:
轻量级、进程中数据共享(不安全)、是进程的一部分不能独立存在、是CPU调度的最小单位。
线程的使用场景:
socketserver 多线程的;web的框架 django flask tornado 多线程来接收用户并发的请求。
多线程的开启:
#开启线程(循环方式) from threading import Thread def func(): print('start',os.getpid()) time.sleep(1) print('end') if __name__ == '__main__': t = Thread(target=func) t.start() for i in range(5): print('主线程',os.getpid()) time.sleep(0.3) #join import time from threading import Thread def func(): n = 1 + 2 + 3 n ** 2 if __name__ == '__main__': start = time.time() lst = [] for i in range(100): t = Thread(target=func) t.start() lst.append(t) for t in lst: t.join() print(time.time() - start) # 5.threading模块中的其他功能 import time from threading import Thread,currentThread,activeCount,enumerate class Mythread(Thread): def __init__(self,arg): super().__init__() self.arg = arg def run(self): time.sleep(1) print('in son',self.arg,currentThread()) for i in range(10): t = Mythread(123) t.start() print(t.ident) print(activeCount()) print(enumerate())
守护线程
import time from threading import Thread def func(): while True: print('in func') time.sleep(0.5) def func2(): print('start func2') time.sleep(10) print('end func2') Thread(target=func2).start() t = Thread(target=func) t.setDaemon(True) t.start() print('主线程') time.sleep(2) print('主线程结束')
线程池
from concurrent.futures import ThreadPoolExecutor def func(num): print('in %s func'%num,currentThread()) time.sleep(5) return num**2 tp = ThreadPoolExecutor(5) ret_l = [] for i in range(30): ret = tp.submit(func,i) ret_l.append(ret) for ret in ret_l: print(ret.result())
爬虫scrapy框架对对线程的设置:
#settings文件中 CONCURRENT_REQUESTS = 32
异步 :在一个任务中调用另一个任务,不需要等待这个任务的结果,继续做其他事儿
同步 :在一个任务中调用另一个任务,要等待这个任务的结果
阻塞 :只要CPU不工作
非阻塞 : 只要cpu工作
同步阻塞 :input recv accept recvfrom requests.get q.get() q.put()
同步非阻塞 :调用一个函数需要等待这个函数执行完毕但是在这个等待的过程中cpu还工作
异步阻塞 : 调用一个方法,不需要等待这个方法结果,但是你的程序还阻塞了
celery 获取结果的时候 :谁先回来先取谁的结果(异步) 如果没有任何任务结束,只能等待结果(阻塞)
io多路复用,监听多个sk连接对象
异步非阻塞 :
调用一个方法,不需要等待这个方法结果,并且也不阻塞
start,terminate,setblocking=False(recv,recvfrom,accept)
q.get_nowait q.put_nowait
from celery import Celery import time c = Celery("task", broker="redis://:alexdsb@10.0.0.133:6379/1",backend="redis://:alexdsb@10.0.0.133:6379/2") @c.task def myfun1(a,b): time.sleep(20) return f"myfun1--{a}--{b}" @c.task def myfun2(): return "myfun2" @c.task def myfun3(): return "myfun3" #其中,broker是一个消息传输中间件,每当应用程序调用celery的异步任务的时候,会向broker传递消息,而后celery的worker将会取到消息。而通常程序发送的消息,发完就完了,可能都不知道对方时候接受了。为此,celery实现了一个backend,用于存储这些消息以及celery执行的一些消息和结果。
gevent模块的使用:
import gevent def play(): # 协程1 print(time.time()) print('start play') gevent.sleep(1) print('end play') def sleep(): # 协程2 print('start sleep') print('end sleep') print(time.time()) g1 = gevent.spawn(play) g2 = gevent.spawn(sleep) # g1.join() # g2.join() # 精准的控制协程任务,一定是执行完毕之后join立即结束阻塞 gevent.joinall([g1,g2])
gevent实现异步爬虫
# 协程的爬虫 import time from gevent import monkey;monkey.patch_all() import gevent url_lst = ['https://www.python.org/','https://www.yahoo.com/','https://github.com/'] def get_page(url): ret = urlopen(url).read() return ret.decode('utf-8') start = time.time() g_l = [] for url in url_lst: g = gevent.spawn(get_page,url) g_l.append(g) gevent.joinall(g_l) print(time.time()-start)
asyncio使用技巧:
await async 事件循环event_loop
await io操作
必须写在async函数里,async表示的是这是一个协程函数
协程函数()调用不执行而是返回一个协程对象
你提交的多个协程任务,谁先执行 谁后执行 谁阻塞 怎么切换这些都是由时间循环控制的
基本用法:
import asyncio async def hello(): print("Hello world!") r = await asyncio.sleep(1) print("Hello again!") loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait([hello(),hello()])) loop.close()
单线程+异步协程实现高性能爬虫
import aiohttp import asyncio #回调函数:解析响应数据 def callback(task): print('this is callback()') #获取响应数据 page_text = task.result() print('在回调函数中,实现数据解析') async def get_page(url): async with aiohttp.ClientSession() as session: async with await session.get(url=url) as response: page_text = await response.text() #read() json() # print(page_text) return page_text start = time.time() urls = [ 'http://127.0.0.1:5000/bobo', 'http://127.0.0.1:5000/jay', 'http://127.0.0.1:5000/tom', ] tasks = [] loop = asyncio.get_event_loop() for url in urls: c = get_page(url) task = asyncio.ensure_future(c) #给任务对象绑定回调函数用于解析响应数据 task.add_done_callback(callback) tasks.append(task) loop.run_until_complete(asyncio.wait(tasks)) print('总耗时:',time.time()-start)
osi七层模型:
人们按照分工不同把互联网协议从逻辑上划分了层级:

| 划分 | osi层级 | 协议 | 硬件 |
| 应用 | 应用层 | http https ftp dns websocket smtp | |
| socket | 传输层 |
tcp/udp协议
|
四层交换机 四层路由器
|
| 网络层 |
ip协议,rarp协议
|
三层交换机、路由器 | |
| 数据链路层 | arp协议 | 交换机、网卡 | |
| 物理层 |
TCP/UDP协议:
TCP(Transmission Control Protocol)可靠的、面向连接的协议(eg:打电话)、传输效率低全双工通信(发送缓存&接收缓存)、面向字节流。使用TCP的应用:Web浏览器;电子邮件、文件传输程序。
UDP(User Datagram Protocol)不可靠的、无连接的服务,传输效率高(发送前时延小),一对一、一对多、多对一、多对多、面向报文,尽最大努力服务,无拥塞控制。使用UDP的应用:域名系统 (DNS);视频流;IP语音(VoIP)。
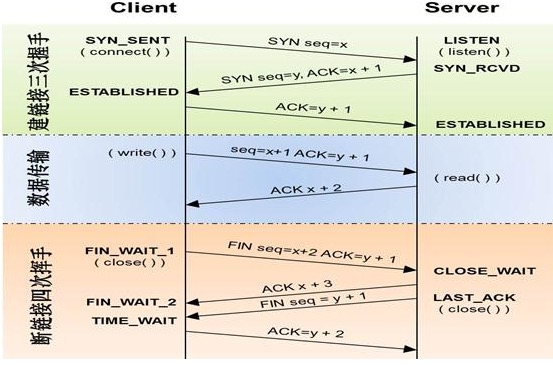
三次握手过程:
TCP是因特网中的传输层协议,使用三次握手协议建立连接。当主动方发出SYN连接请求后,等待对方回答SYN+ACK[1],并最终对对方的 SYN 执行 ACK 确认。这种建立连接的方法可以防止产生错误的连接。[1] TCP三次握手的过程如下: 客户端发送SYN(SEQ=x)报文给服务器端,进入SYN_SEND状态。 服务器端收到SYN报文,回应一个SYN (SEQ=y)ACK(ACK=x+1)报文,进入SYN_RECV状态。 客户端收到服务器端的SYN报文,回应一个ACK(ACK=y+1)报文,进入Established状态。 三次握手完成,TCP客户端和服务器端成功地建立连接,可以开始传输数据了。
四次挥手过程:
建立一个连接需要三次握手,而终止一个连接要经过四次握手,这是由TCP的半关闭(half-close)造成的。 (1) 某个应用进程首先调用close,称该端执行“主动关闭”(active close)。该端的TCP于是发送一个FIN分节,表示数据发送完毕。 (2) 接收到这个FIN的对端执行 “被动关闭”(passive close),这个FIN由TCP确认。 注意:FIN的接收也作为一个文件结束符(end-of-file)传递给接收端应用进程,放在已排队等候该应用进程接收的任何其他数据之后,因为,FIN的接收意味着接收端应用进程在相应连接上再无额外数据可接收。 (3) 一段时间后,接收到这个文件结束符的应用进程将调用close关闭它的套接字。这导致它的TCP也发送一个FIN。 (4) 接收这个最终FIN的原发送端TCP(即执行主动关闭的那一端)确认这个FIN。[1] 既然每个方向都需要一个FIN和一个ACK,因此通常需要4个分节。 注意: (1) “通常”是指,某些情况下,步骤1的FIN随数据一起发送,另外,步骤2和步骤3发送的分节都出自执行被动关闭那一端,有可能被合并成一个分节。[2] (2) 在步骤2与步骤3之间,从执行被动关闭一端到执行主动关闭一端流动数据是可能的,这称为“半关闭”(half-close)。 (3) 当一个Unix进程无论自愿地(调用exit或从main函数返回)还是非自愿地(收到一个终止本进程的信号)终止时,所有打开的描述符都被关闭,这也导致仍然打开的任何TCP连接上也发出一个FIN。 无论是客户还是服务器,任何一端都可以执行主动关闭。通常情况是,客户执行主动关闭,但是某些协议,例如,HTTP/1.0却由服务器执行主动关闭。
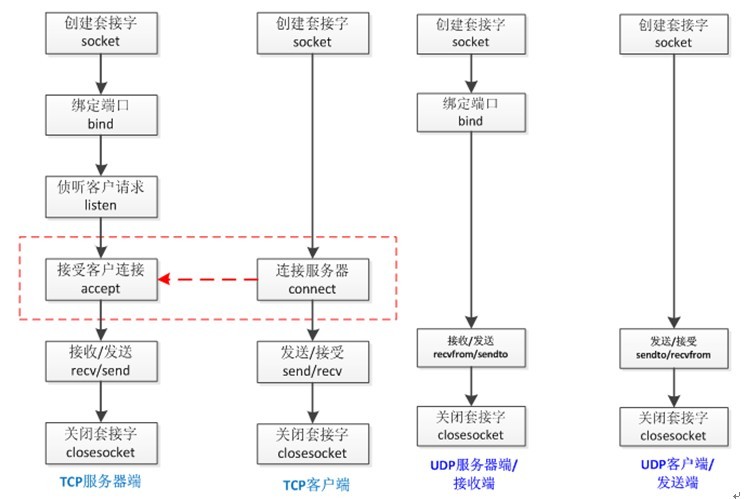
基于TCP协议的socket:
tcp是基于链接的,必须先启动服务端,然后再启动客户端去链接服务端
server端

import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8898)) #把地址绑定到套接字
sk.listen() #监听链接
conn,addr = sk.accept() #接受客户端链接
ret = conn.recv(1024) #接收客户端信息
print(ret) #打印客户端信息
conn.send(b'hi') #向客户端发送信息
conn.close() #关闭客户端套接字
sk.close() #关闭服务器套接字(可选)
client端
import socket
sk = socket.socket() # 创建客户套接字
sk.connect(('127.0.0.1',8898)) # 尝试连接服务器
sk.send(b'hello!')
ret = sk.recv(1024) # 对话(发送/接收)
print(ret)
sk.close() # 关闭客户套接字
问题:重启服务端时可能会遇到
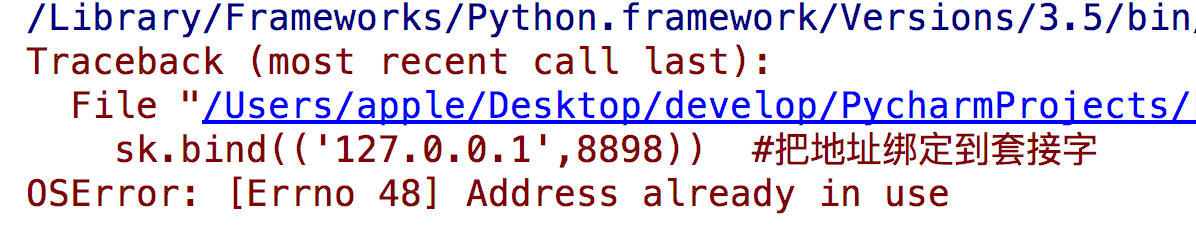
解决方法:
#加入一条socket配置,重用ip和端口
import socket
from socket import SOL_SOCKET,SO_REUSEADDR
sk = socket.socket()
sk.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #就是它,在bind前加
sk.bind(('127.0.0.1',8898)) #把地址绑定到套接字
sk.listen() #监听链接
conn,addr = sk.accept() #接受客户端链接
ret = conn.recv(1024) #接收客户端信息
print(ret) #打印客户端信息
conn.send(b'hi') #向客户端发送信息
conn.close() #关闭客户端套接字
sk.close() #关闭服务器套接字(可选)
基于UDP协议的socket
udp是无链接的,启动服务之后可以直接接受消息,不需要提前建立链接
server端
import socket
udp_sk = socket.socket(type=socket.SOCK_DGRAM) #创建一个服务器的套接字
udp_sk.bind(('127.0.0.1',9000)) #绑定服务器套接字
msg,addr = udp_sk.recvfrom(1024)
print(msg)
udp_sk.sendto(b'hi',addr) # 对话(接收与发送)
udp_sk.close() # 关闭服务器套接字
client端
import socket
ip_port=('127.0.0.1',9000)
udp_sk=socket.socket(type=socket.SOCK_DGRAM)
udp_sk.sendto(b'hello',ip_port)
back_msg,addr=udp_sk.recvfrom(1024)
print(back_msg.decode('utf-8'),addr
websocket
Websocket是一种在单个TCP连接上进行全双工通讯的协议,双工(duplex)是指两台通讯设备之间,允许有双向的资料传输。全双工的是指,允许两台设备间**同时**进行双向资料传输。这是相对于半双工来说的,半双工不能同时进行双向传输,这期间的区别相当于手机和对讲机的区别,手机在讲话的同时也能听到对方说话,对讲机只能一个说完另一个才能说。
长话短说,在Websocket协议中,客户端和服务端只需要做一个握手的动作,就能形成一条通道,两者之间可以进行数据互相传送。
所以WebSocket协议分为两部分:
1. 握手
客户端发送一个请求,服务器回应
握手时,客户端发送一个随机的Sec-WebSocket-Key,服务端根据这个key做一些处理,返回一个Sec-WebSocket-Accept的值给客户端,
2.数据传输
这是Websocket的数据传输协议,聊天信息一般会按照这个协议的规则来传输
详情见https://www.cnblogs.com/lvxw/articles/10590941.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号