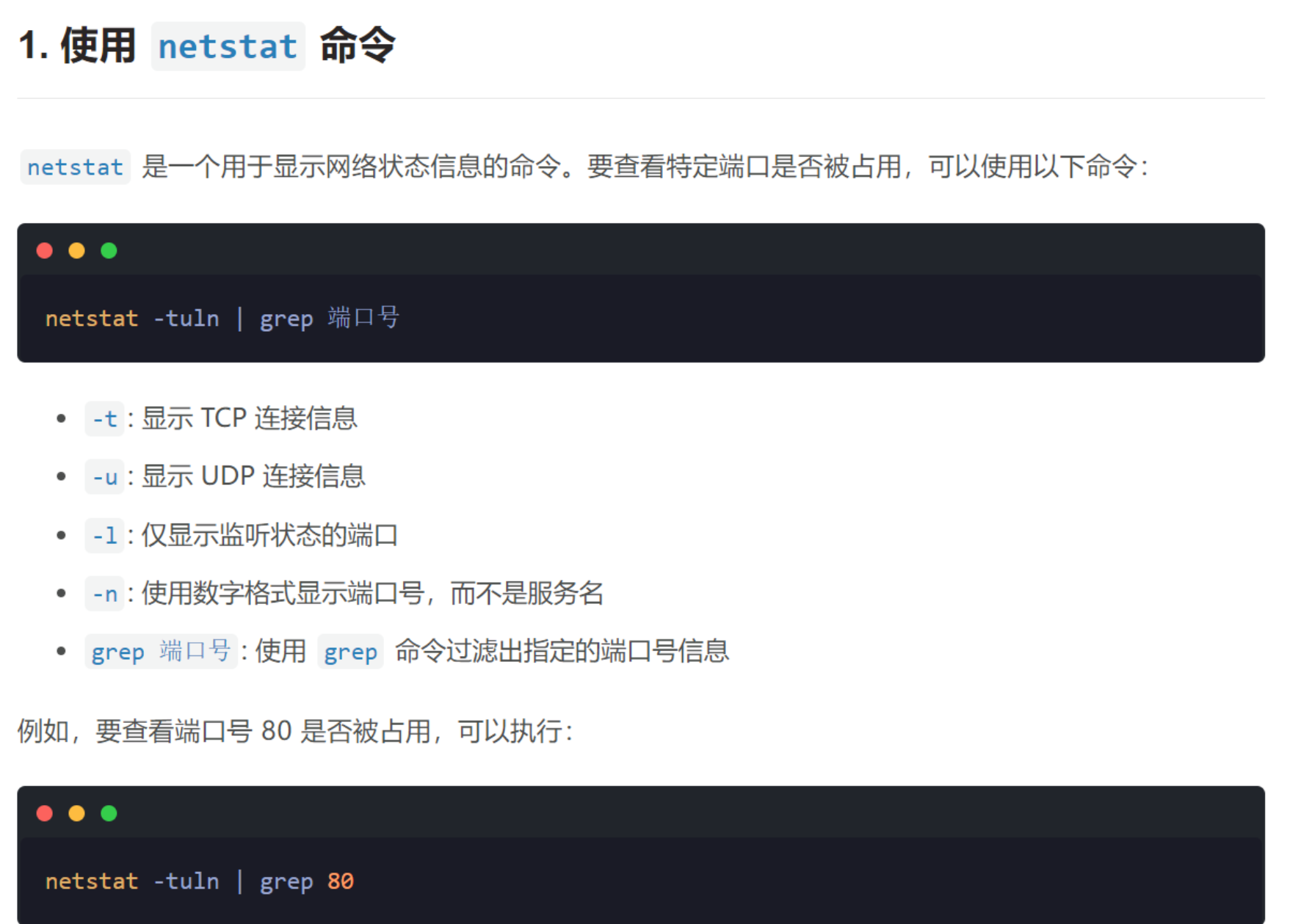
面试疑难问题
- 为什么不直接把CSV文件上传到hdfs而要用flume采集
- 动态分区 提取其中的时间戳
- 断点续传 实时监听不用手动续传
- 要有拦截器 配置
- 事务传输时
- 更多控制能力 积攒到多少批flushing一次
- 忽略哪种类型的不上传 文件太多了一个个手动上传费时费力且容易出错
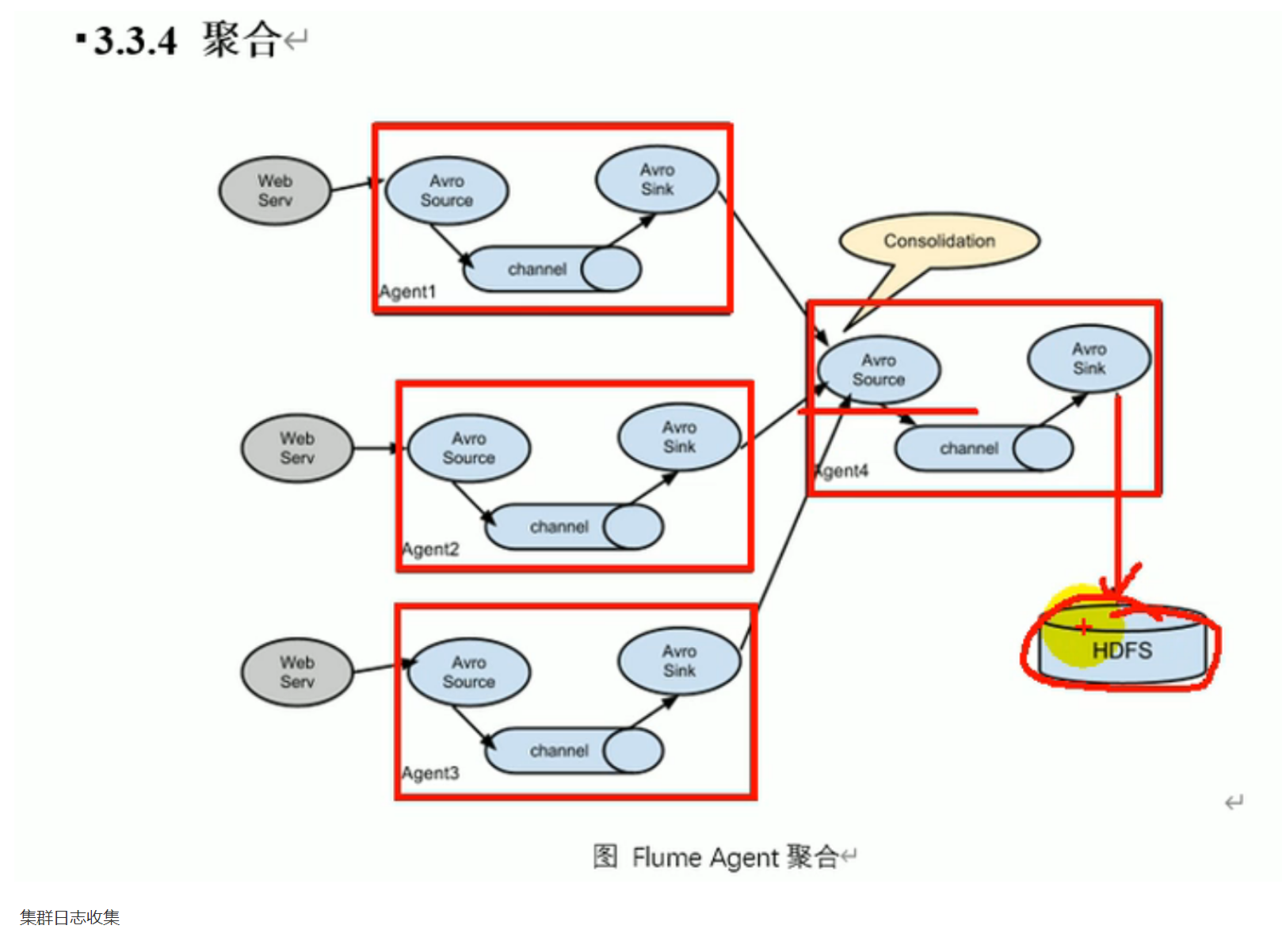
- 我一直纠结在AV阿罗通信是干什么的,和我的场景搭配不,是做多个项目不同集群的日志收集
![]()
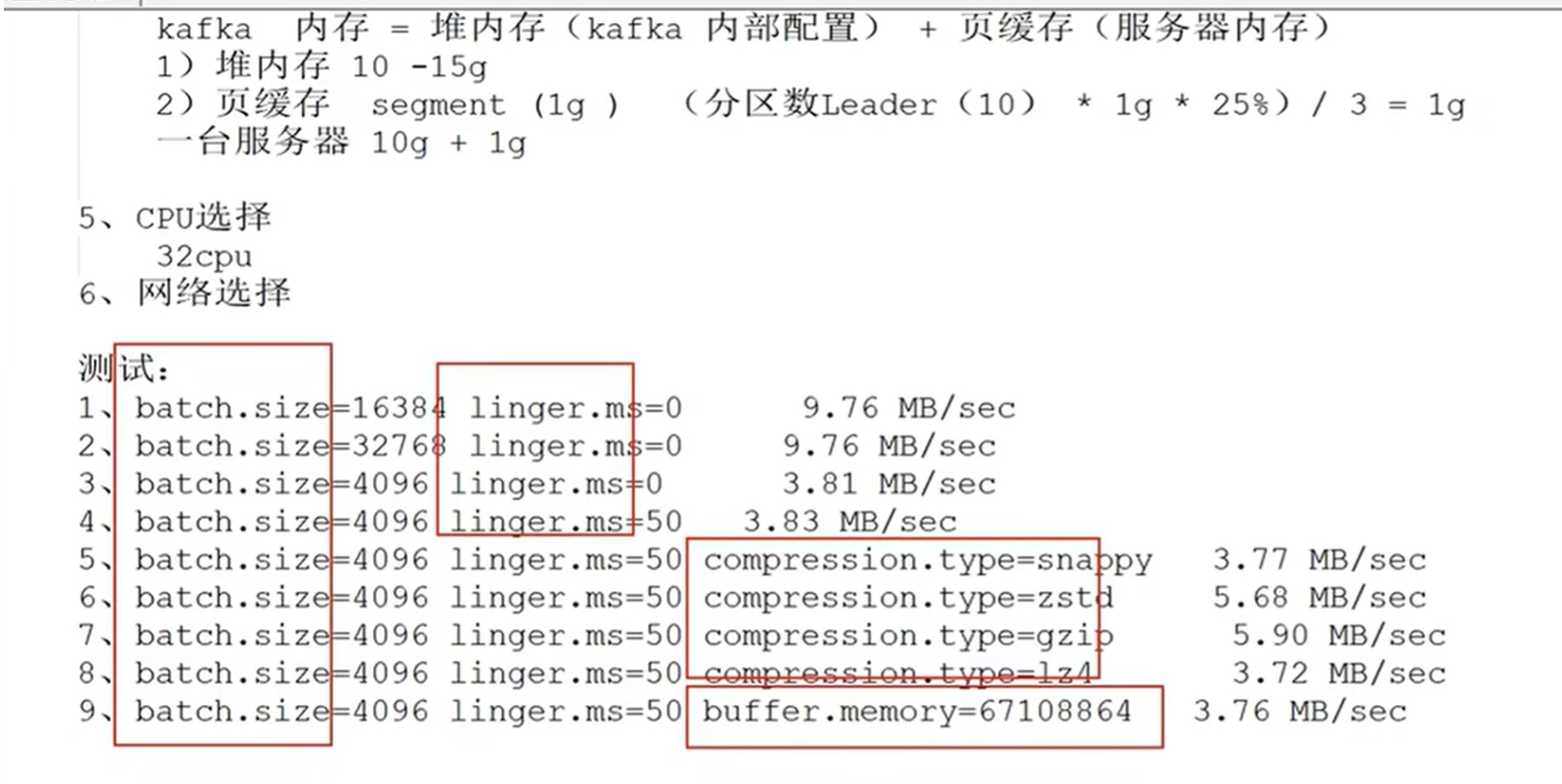
- kafka具体数据量
![]()
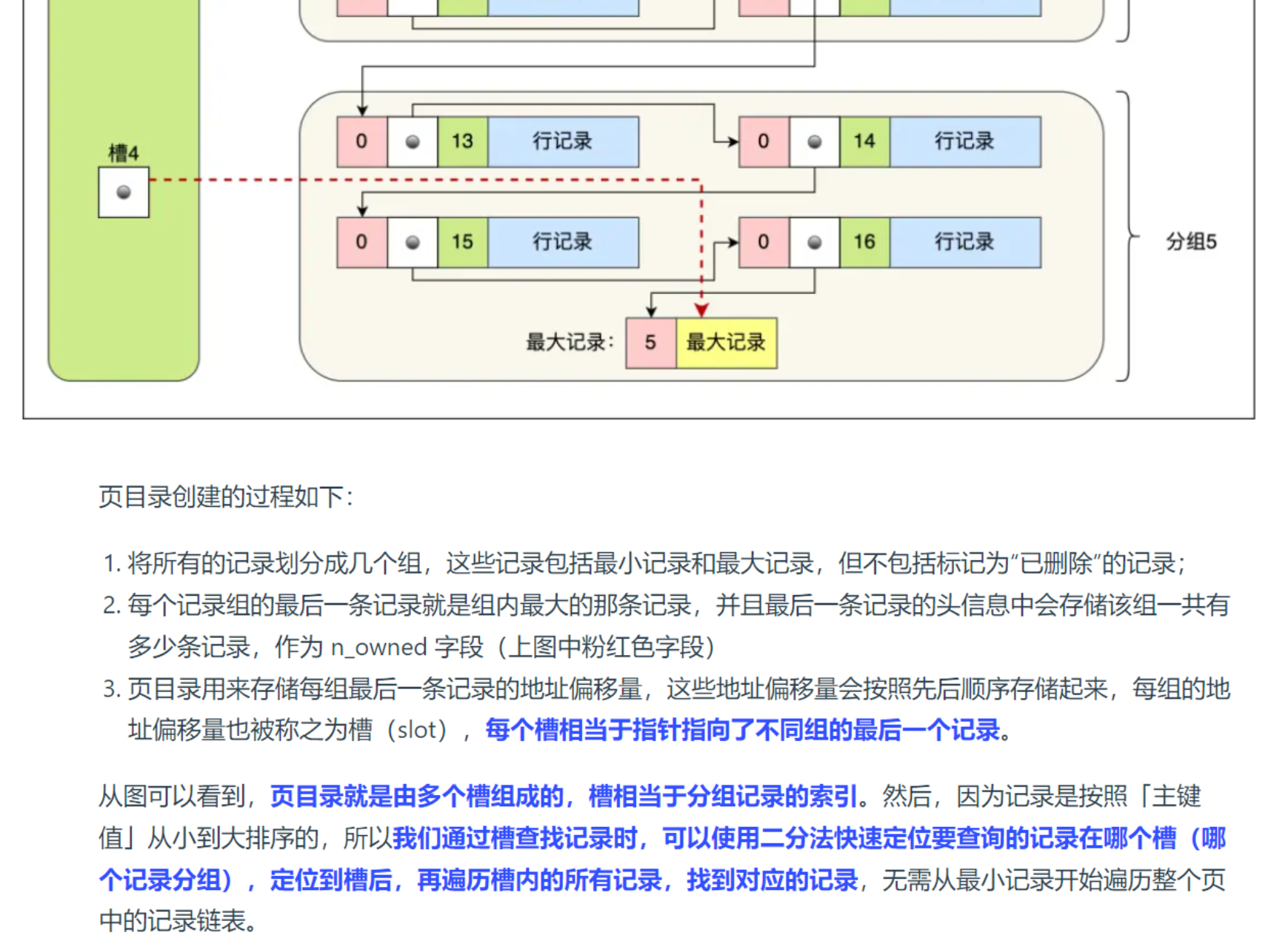
- 页目录 索引下推 reward
![]()
![]()
页组织成双叶链表如果数据量非常大就不是顺序IO,所以有了区1MB
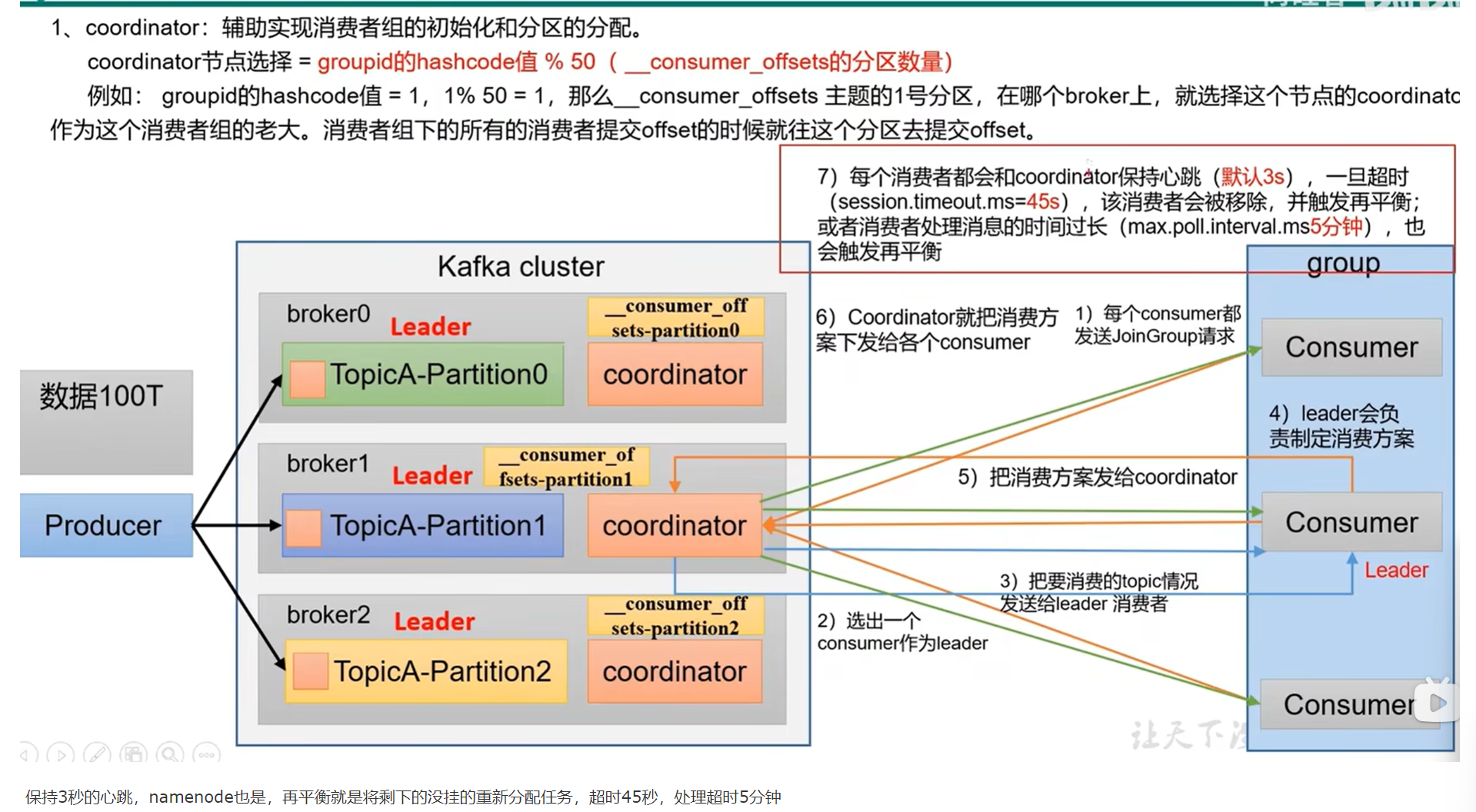
- kafka精确一次 扩容broker分区 下游的消费者
![]()
-
![]()
进程切换 要交换的信息保存在pcb中
- kafka再平衡 粘性策略
![]()
consumer消费者组中也是有leader的,有协调器选出 协调器把要消费的topic情况发给leader,leader制定消费方案 协调器下发消费方案
![]()
![]()
手动提交 漏消费 异步同步两种方式
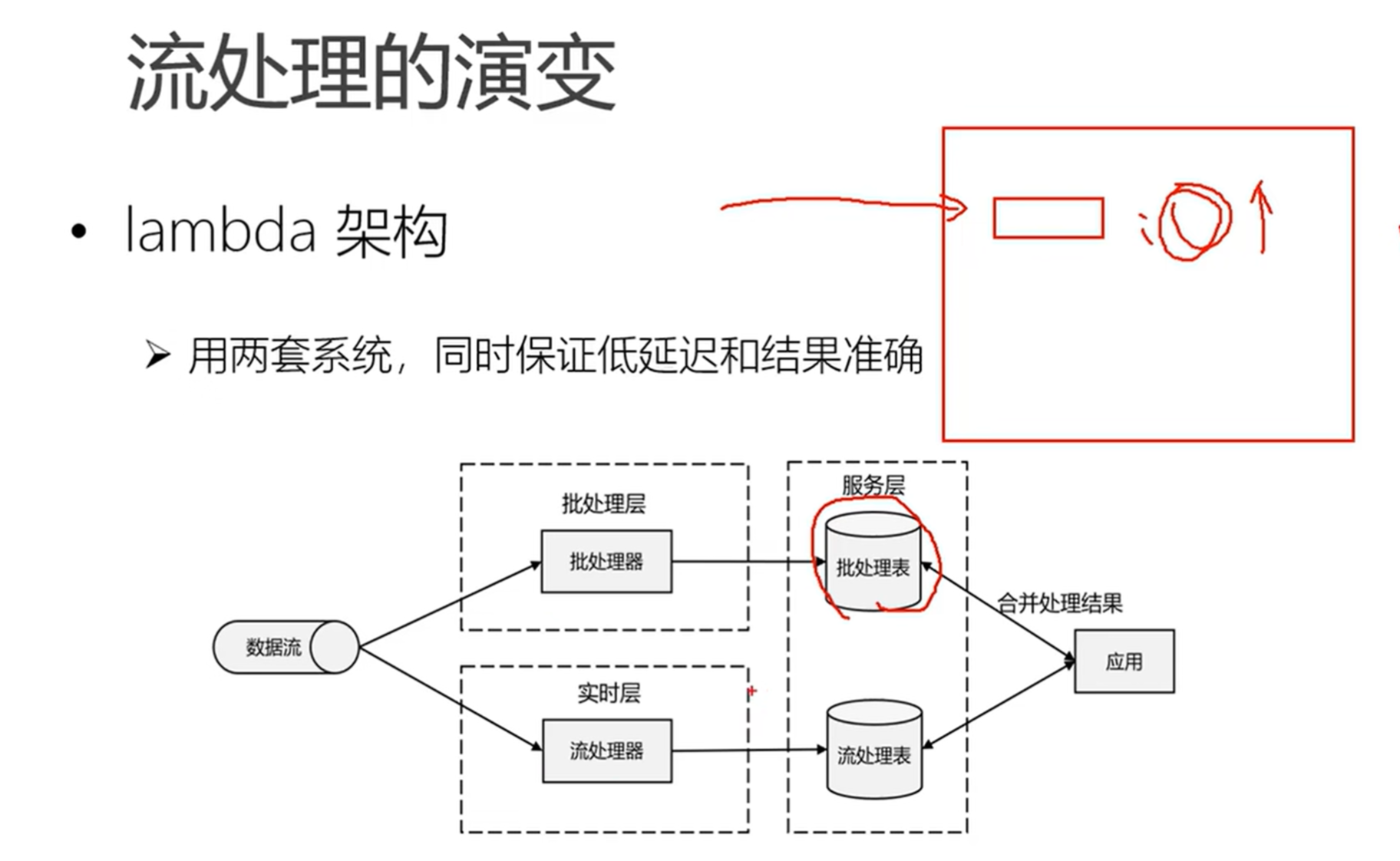
- flink
![]()
![]()
物理分区是并行度的改变 打散shuffle 冲缩放 轮训
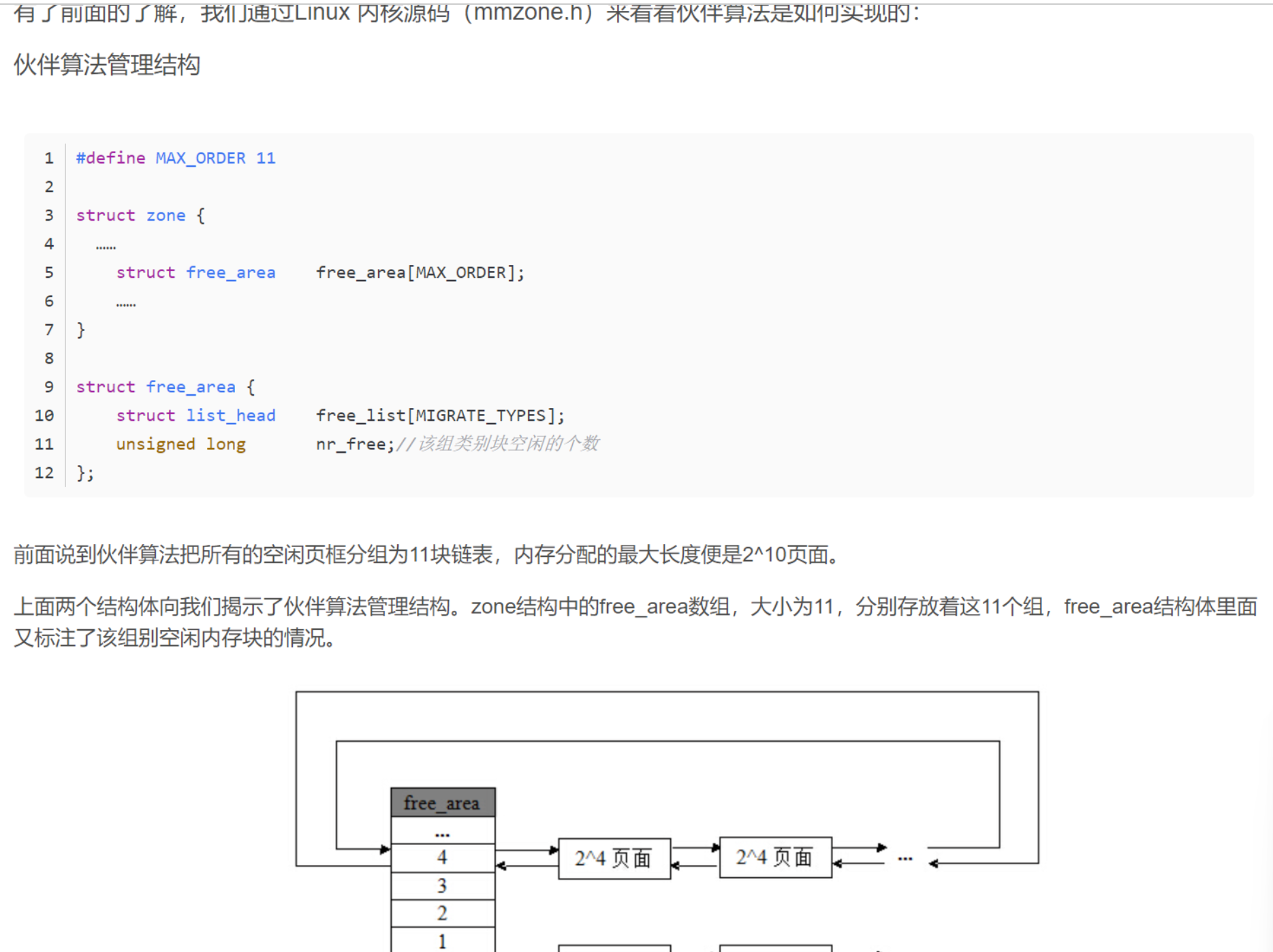
- Linux内核页面分配算法 伙伴算法
![]()
![]()
![]()
![]()
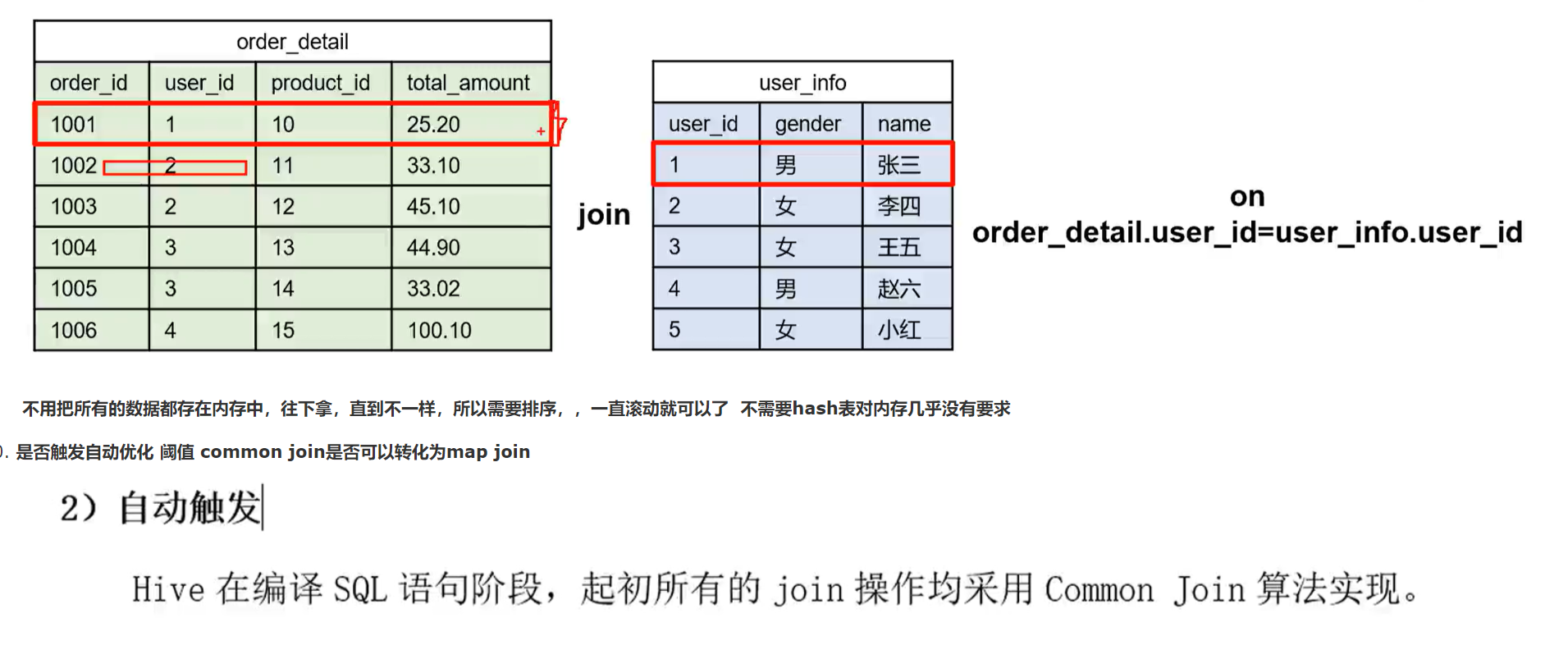
- 对mapjoin和bucket map join SMBjoin的理解出现了问题
![]()
![]()
- 应对数据倾斜
![]()
第一个是map端聚合 将倾斜的键聚合在一起,一般都能解决
![]()
![]()
![]()
![]()
![]()
![]()
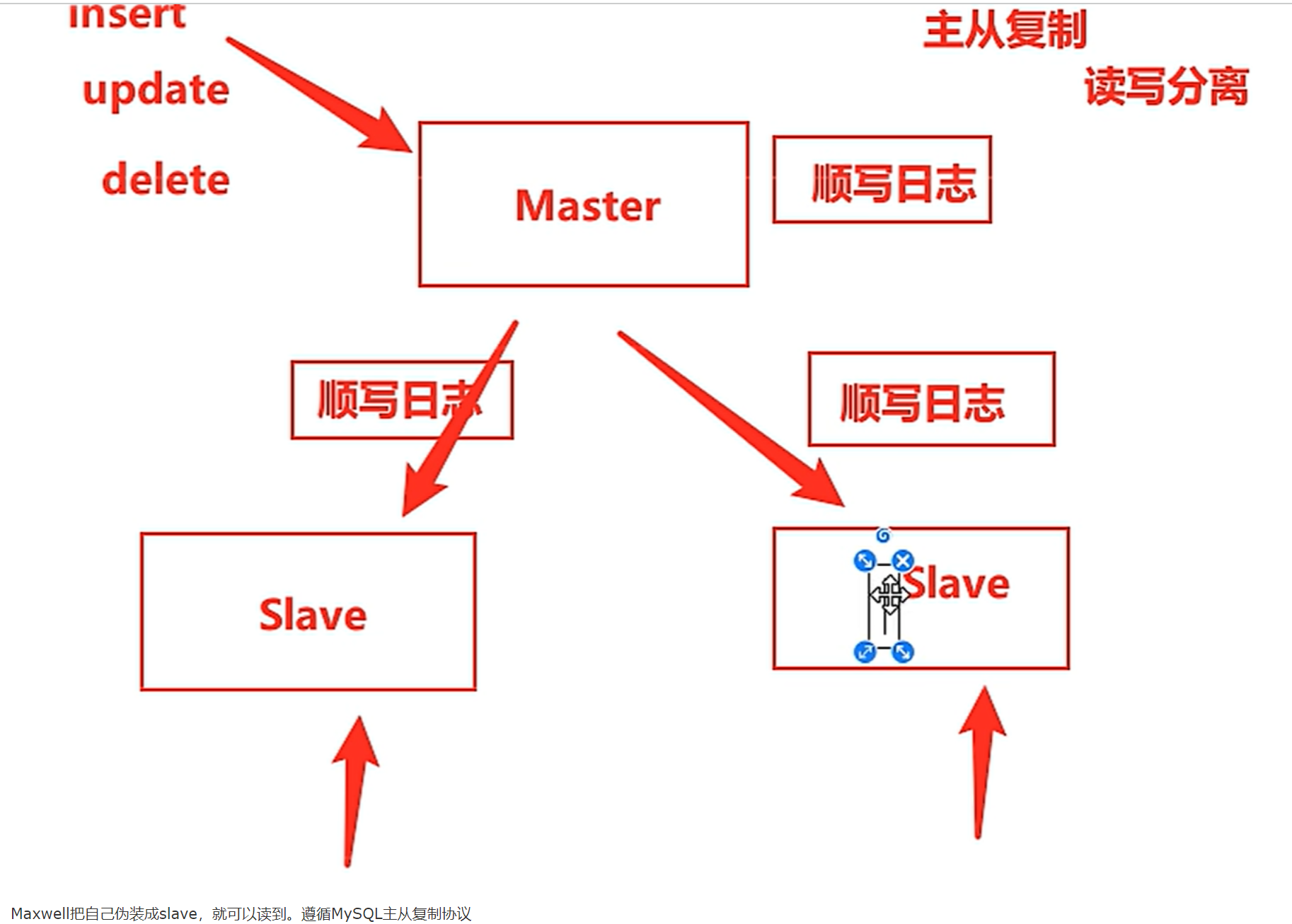
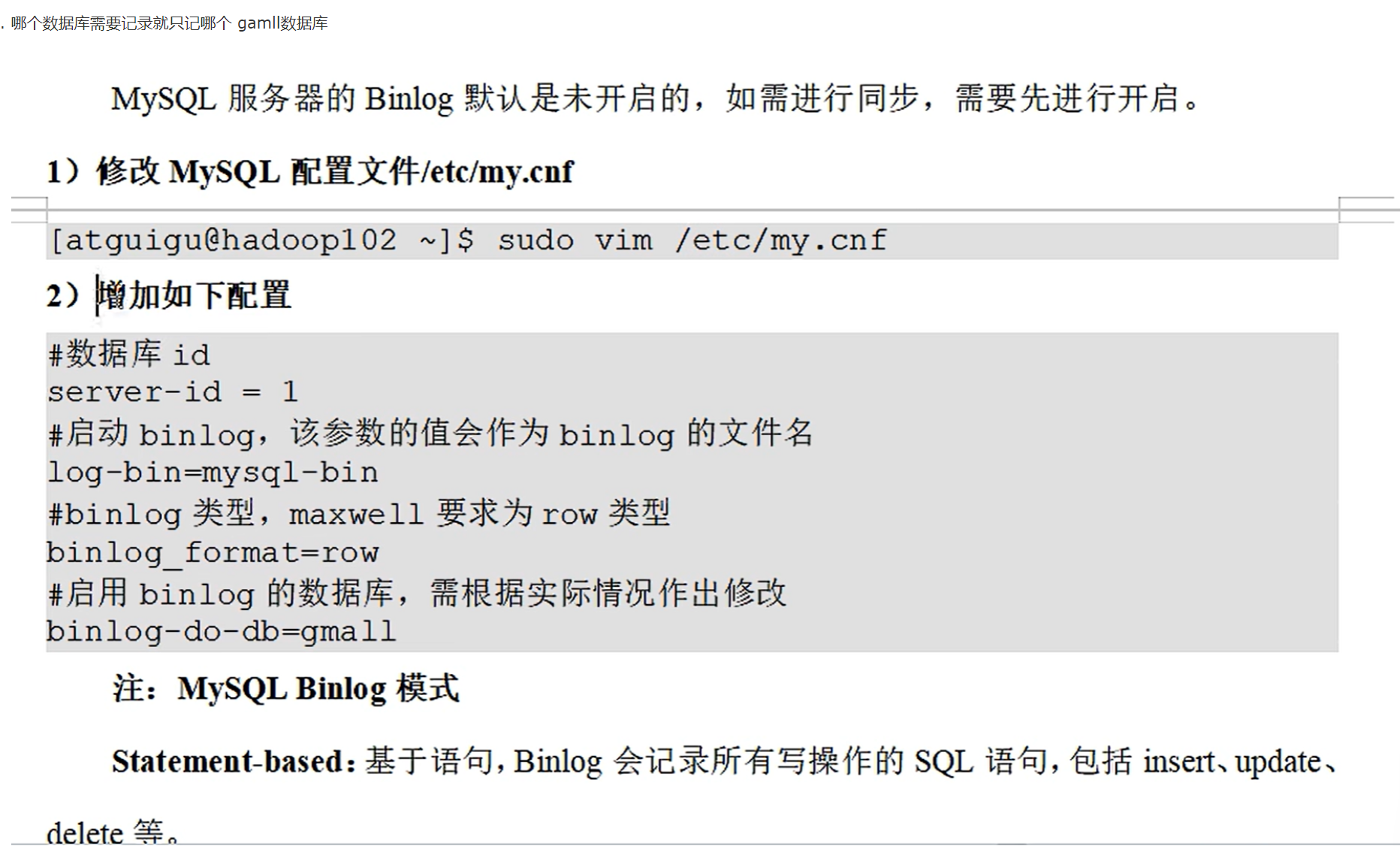
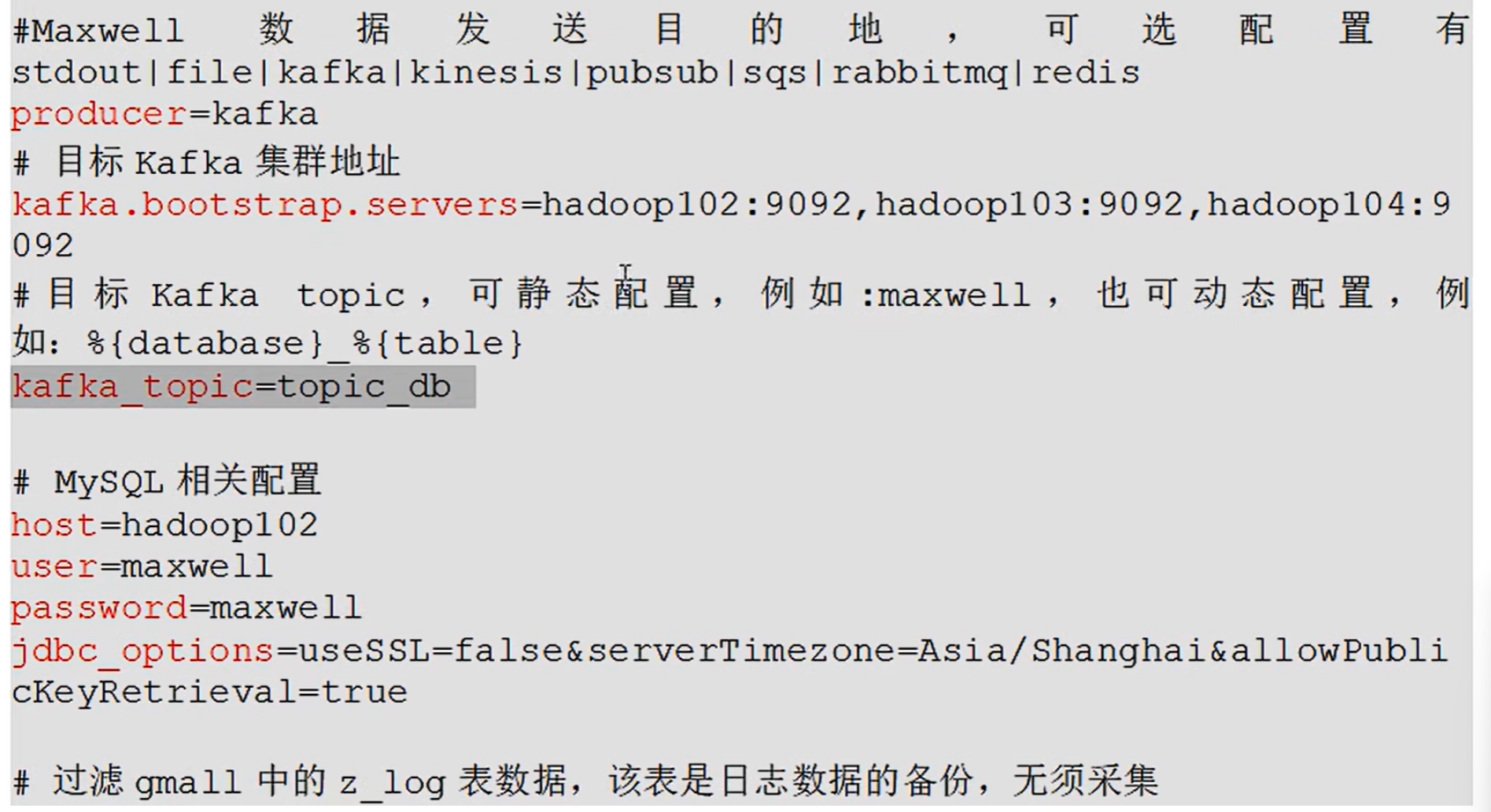
- 为什么要用Maxwell收集这些信息
![]()
-
Maxwell工作详解
![]()
![]()
![]()
![]()
-
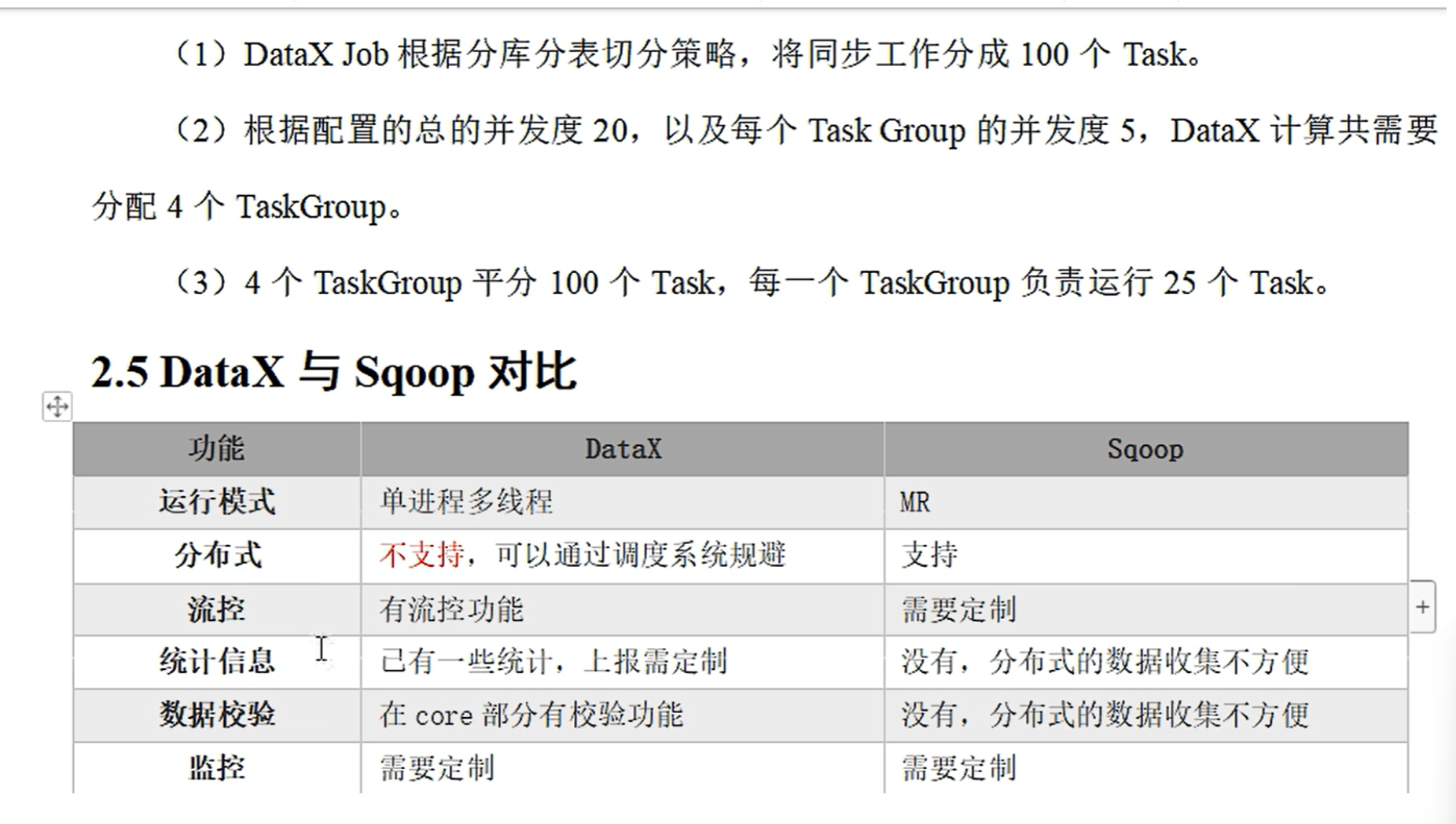
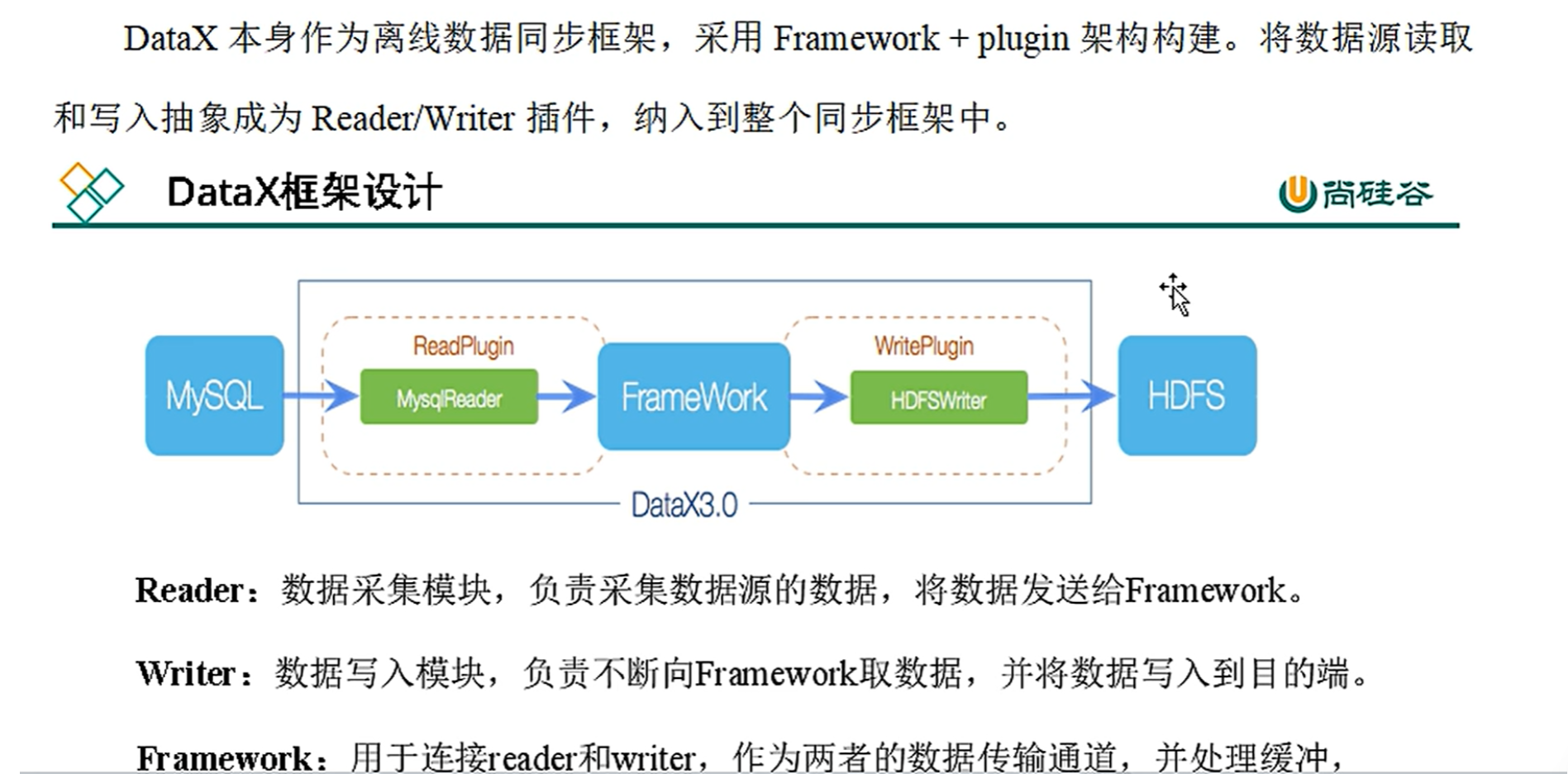
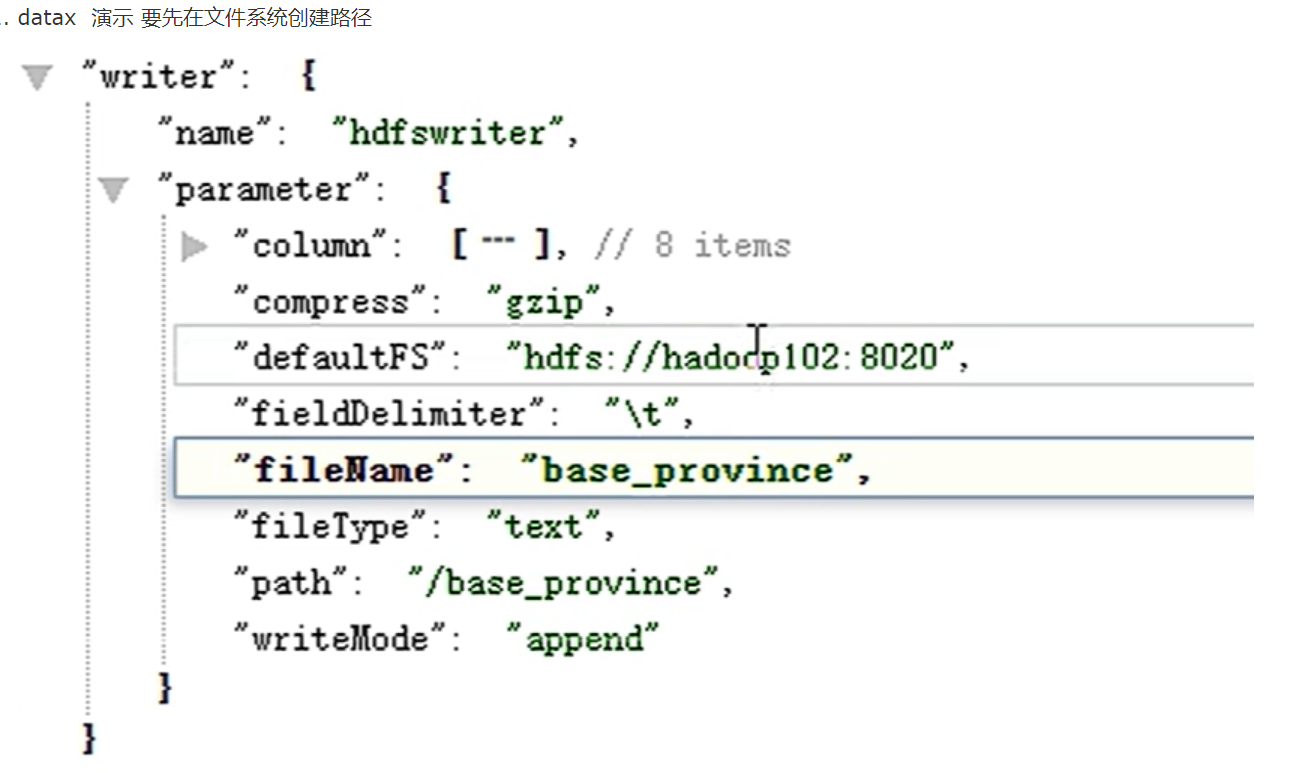
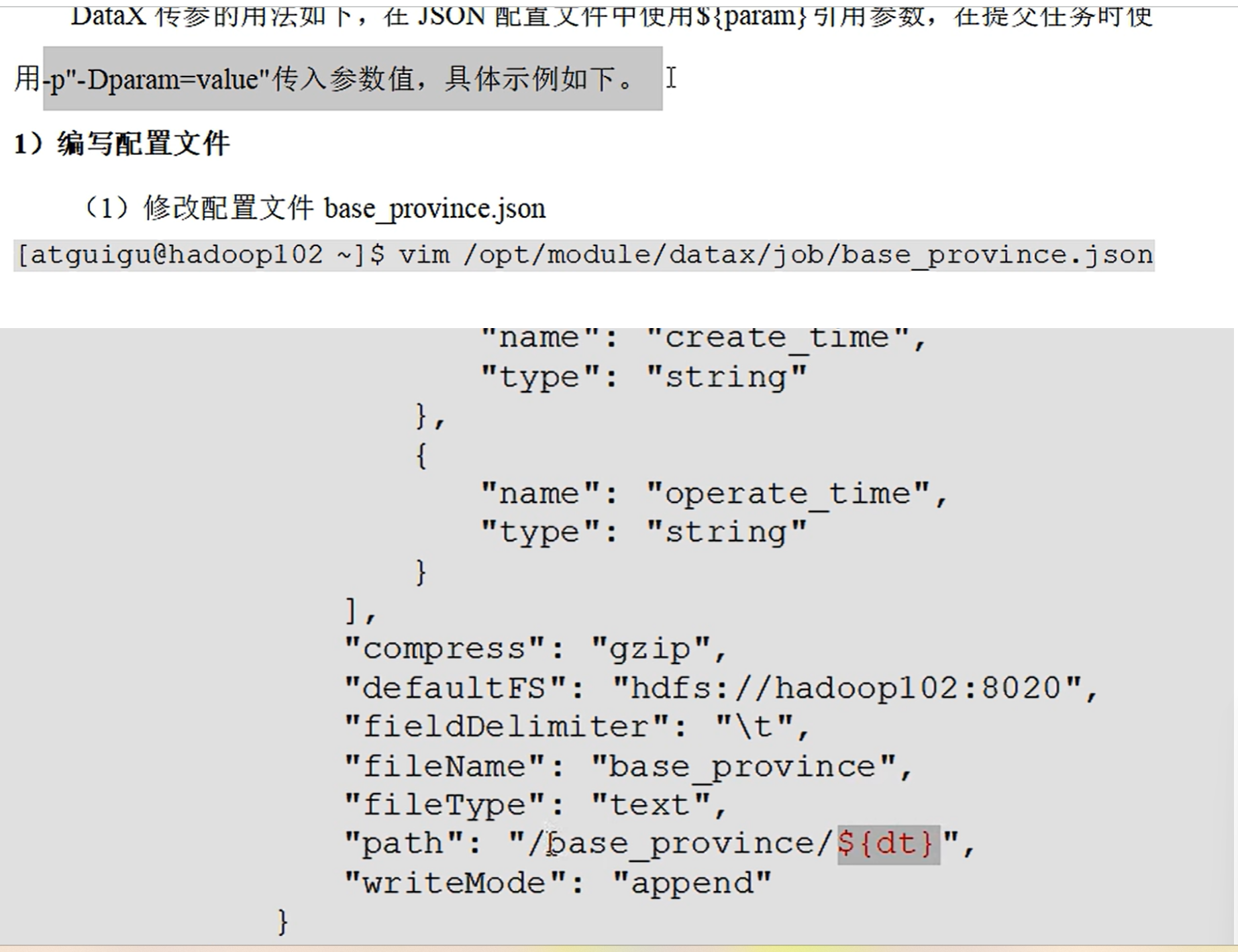
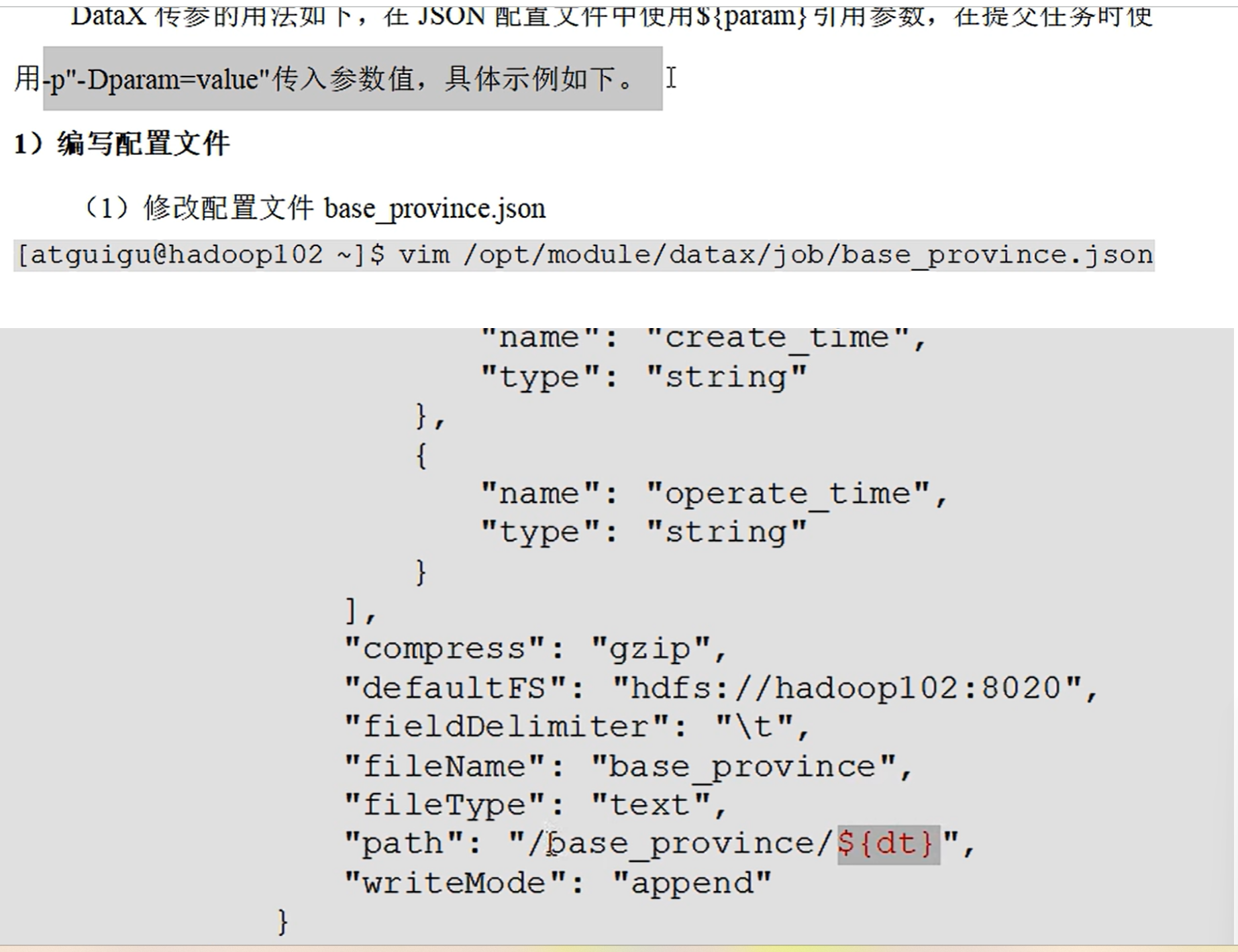
datax有模板
![]()
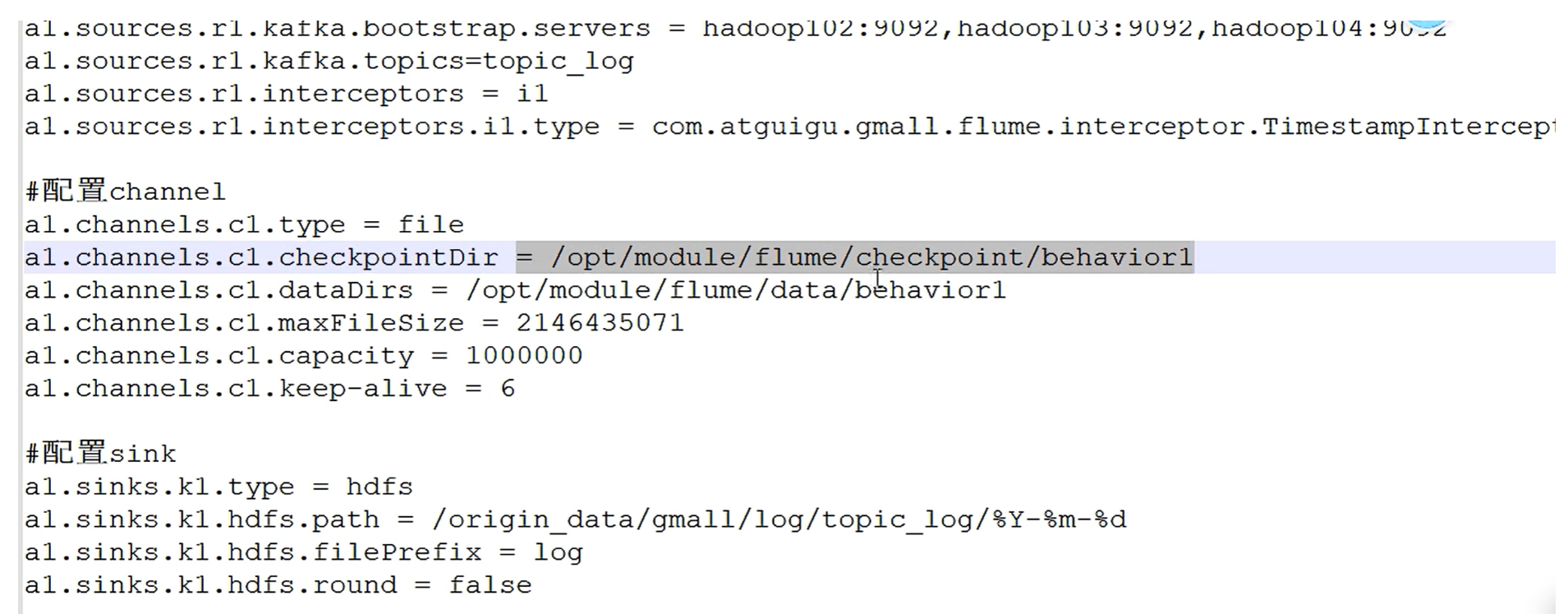
flume也可以配置检查点文件
![]()
![]()
![]()
![]()
- 维度建模
![]()
![]()
![]()
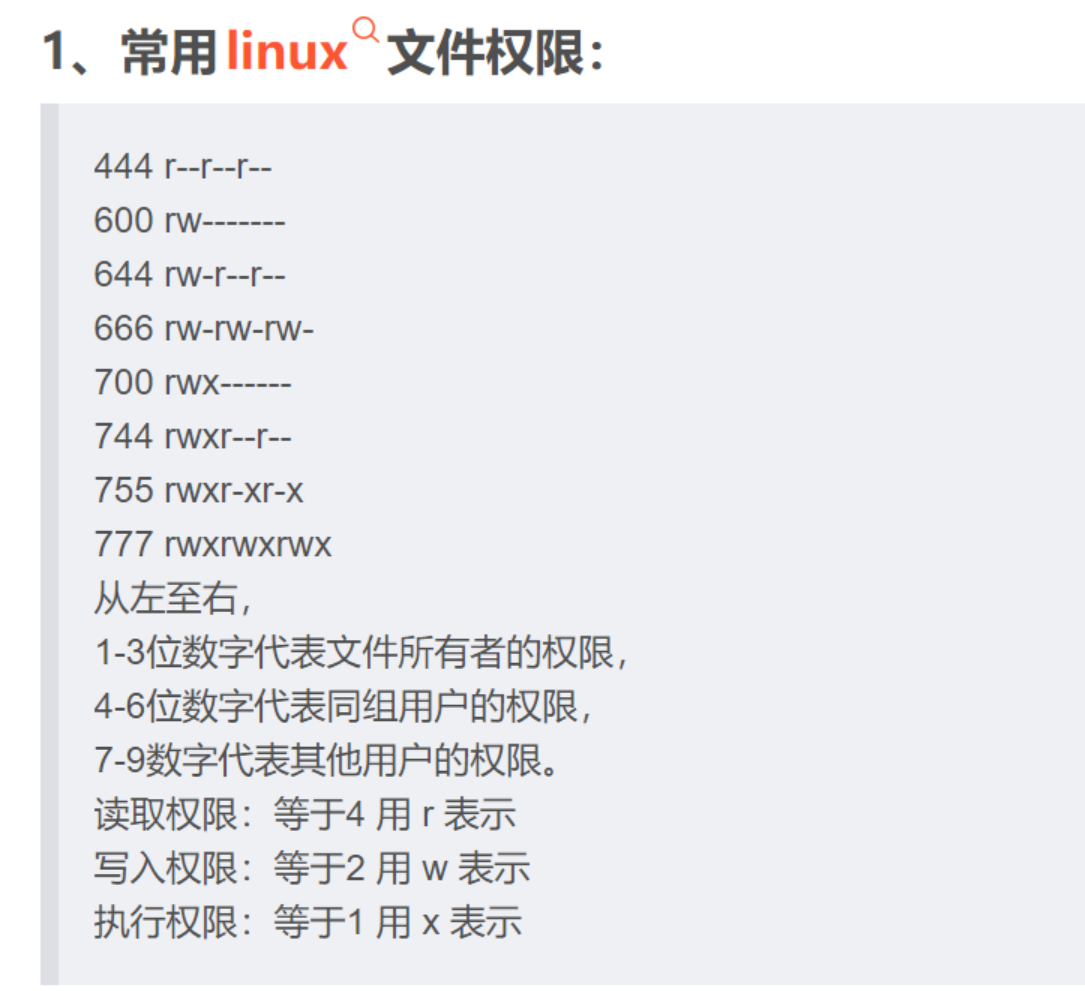
- 删除 QPS
![]()
![]()
![]()
![]()
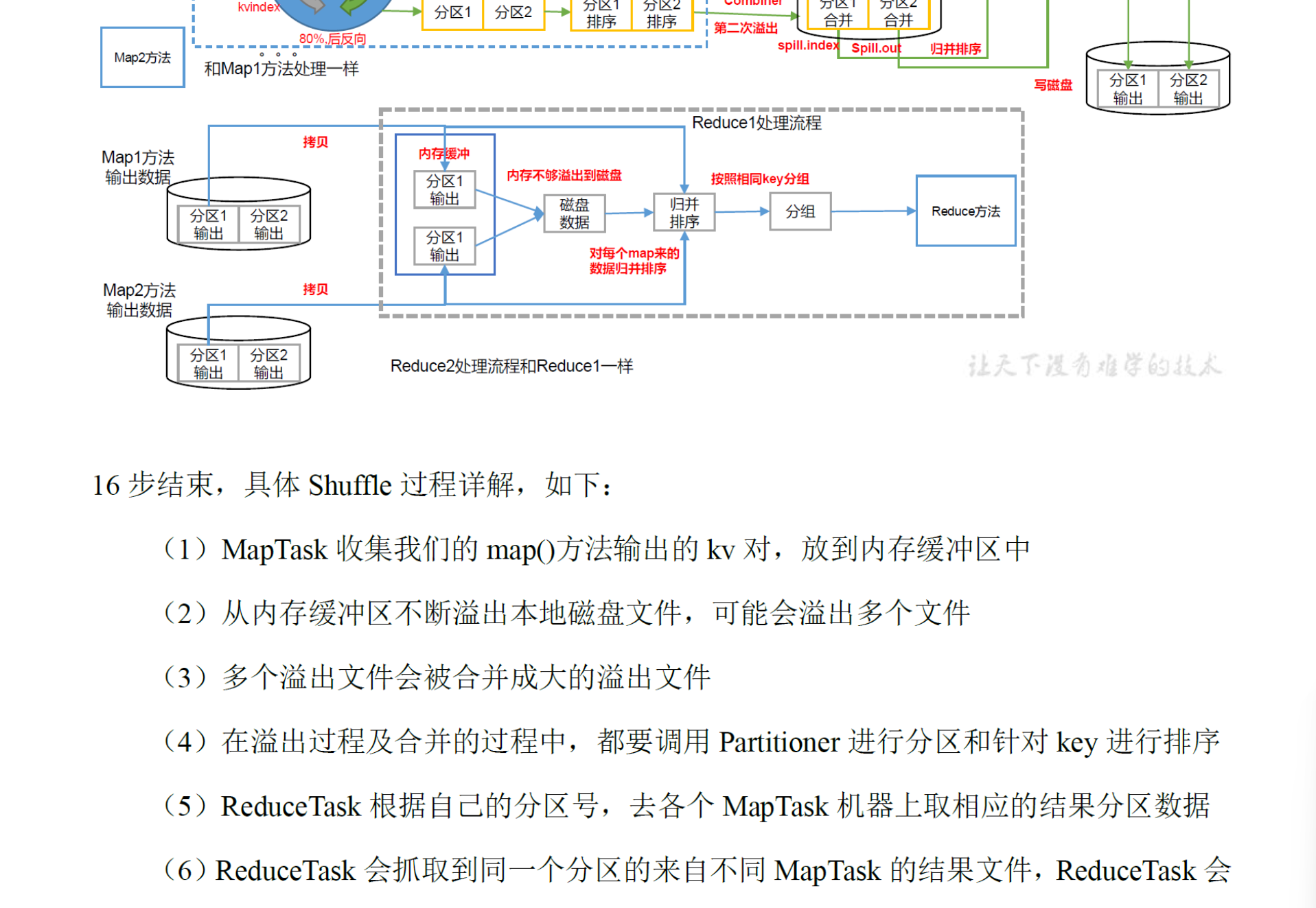
- MapReduce
![]()
![]()
![]()
![]()
-
DataNode
![]()
![]()

























 浙公网安备 33010602011771号
浙公网安备 33010602011771号