4.17思凡特面试
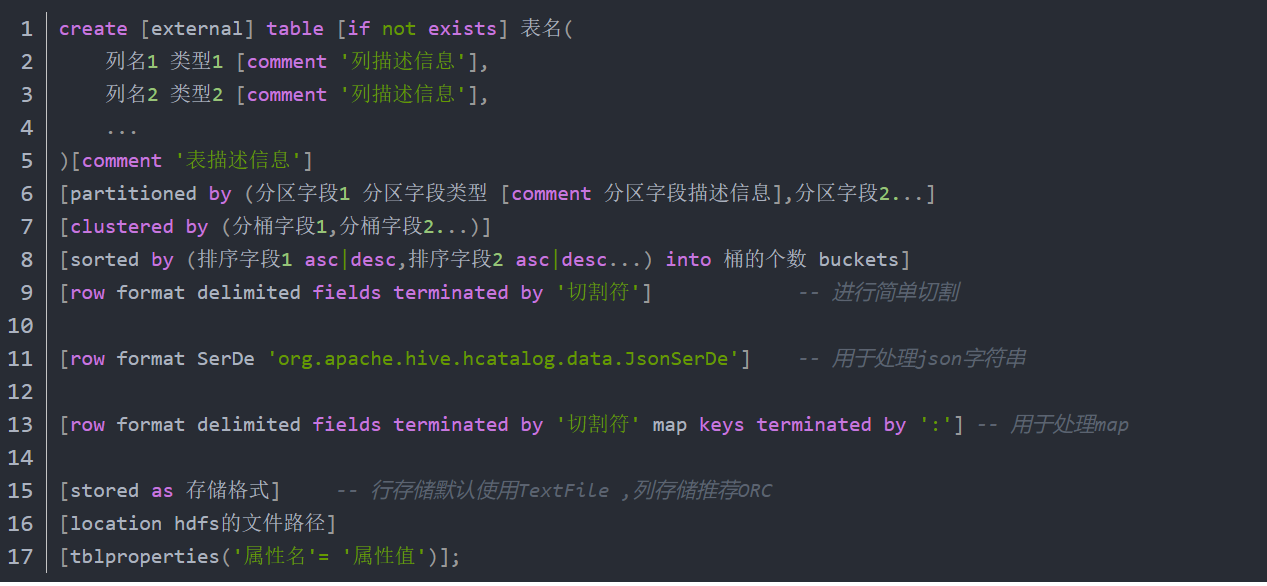
- hive语法重视
![]()
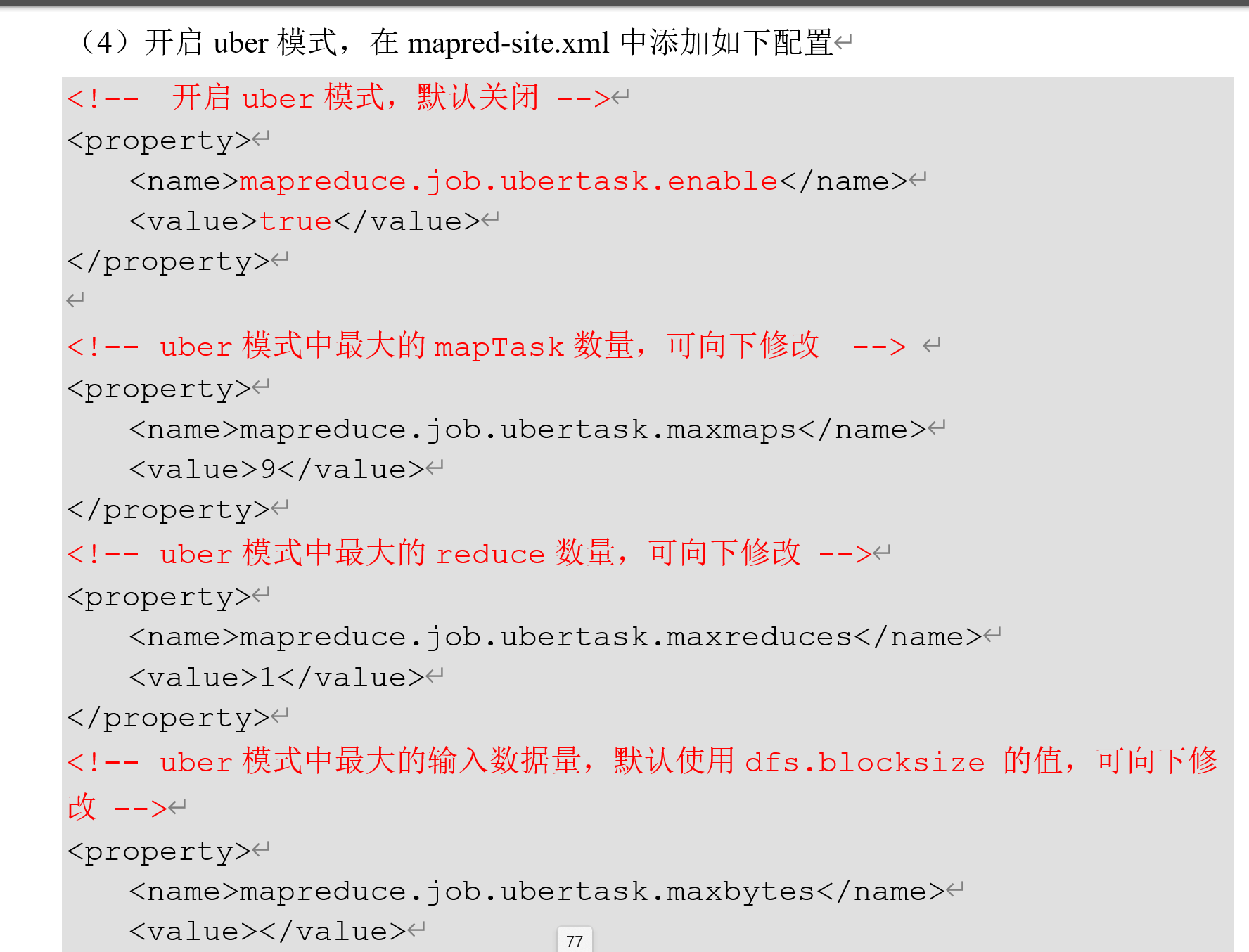
- hdfs调优
![]()
![]()
![]()
![]()
![]()
![]()
- 怎么编写清洗
![]()
![]()
- 怎么写支持压缩的map中间结果
![]()
![]()
- 一些误区
- datanode接受数据是一个块一个块往上传,后面两个节点是依次调用的
- 元数据得在namenode内存中加载,而非仅存在磁盘上
- Fsimage保存目录和iNode,eidts记录更新操作 两个并不是一致的,第一次就会相当于合并
- datanode上也有元信息,汇报给namenode
![]()
- 容量采用深度优先算法,优先那些资源占用率低的,而公平优先资源差额大的
![]()
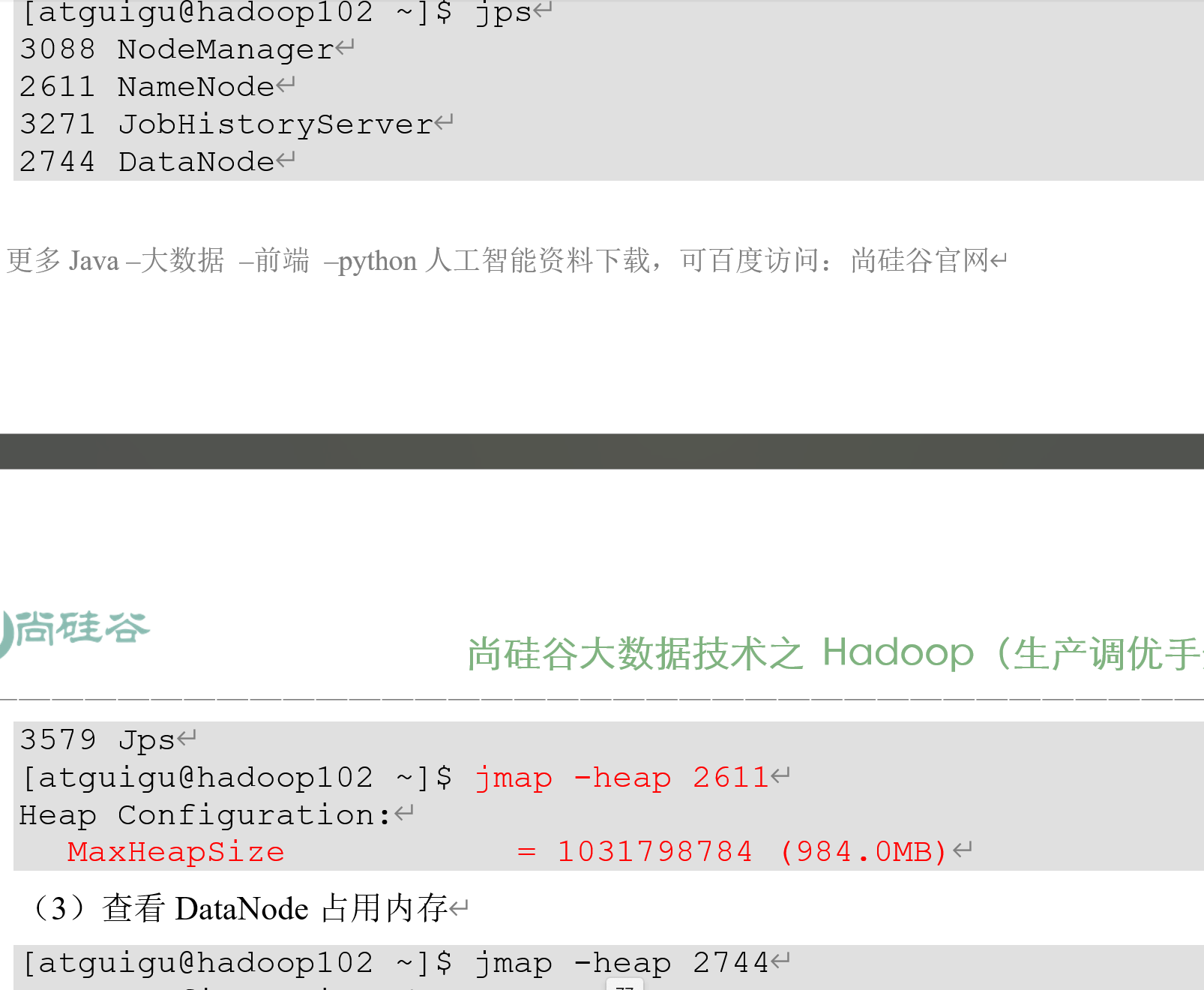
- yarn 查看集群使用内存情况jmap
![]()
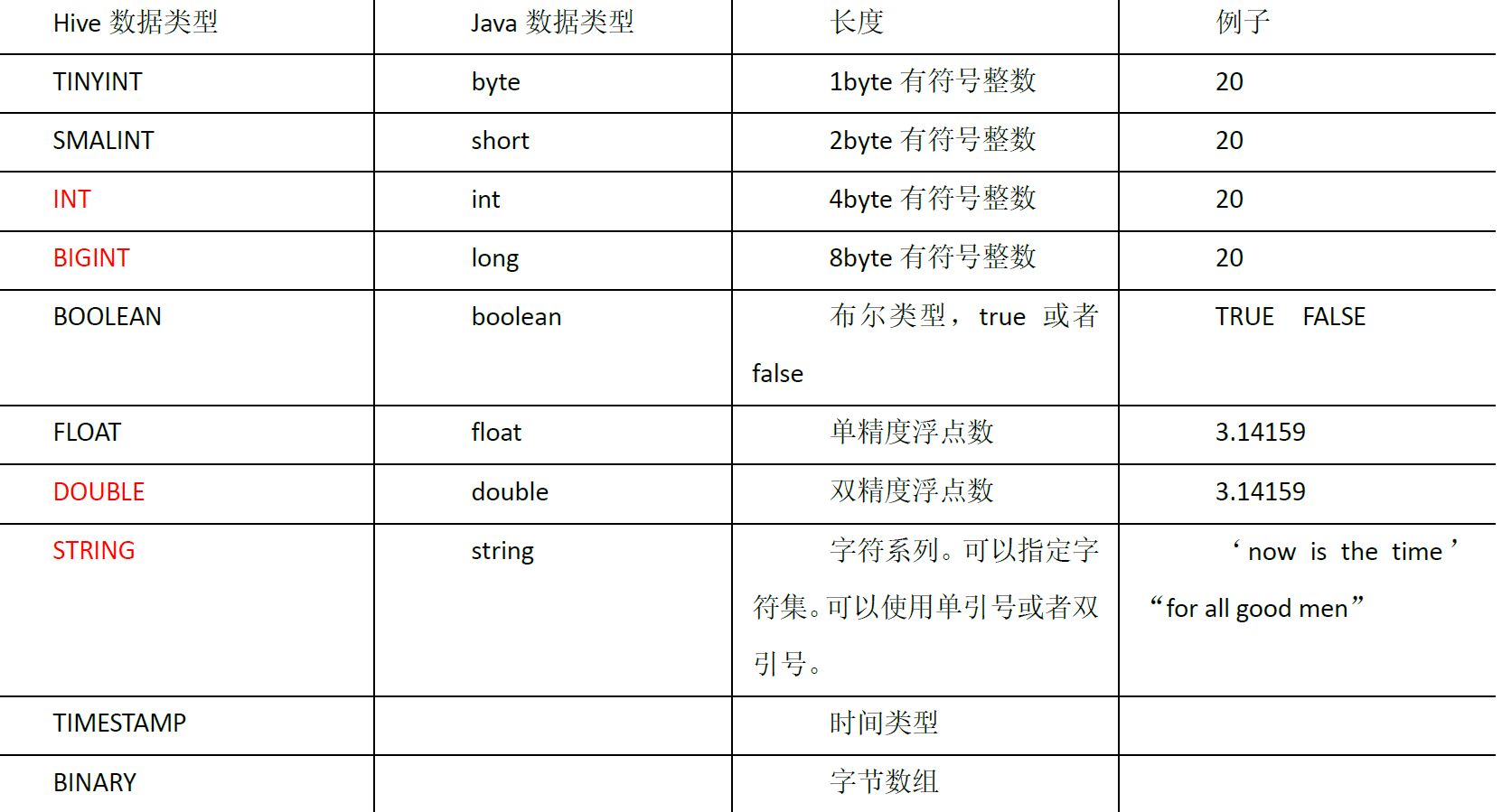
- hive基本类型
![]()
- 如何将数据装载进已有的表中
![]()
location是表建立时用的,load data inpath into是建好以后
- hive优化
![]()
![]()
![]()
![]()
![]()


















 浙公网安备 33010602011771号
浙公网安备 33010602011771号