

redis
1.Redis是单线程的
redis是基于内存操作的,CPU不是操作瓶颈,redis的瓶颈是根据机器内存和网络宽带,那既然CPU不是瓶颈,那就意味着可以用单线程来实现,那就用单线程了!
Redis是C语言写的,官方提供的十万QPS
redis为什么单线程就快?
1.误区:高性能的服务器一定是多线程的,多线程一定比单线程效率高,但其实多线程由于上下文切换是比较影响性能的
2.核心:redis是将所有数据放到内存中的,单线程就是比多线程效率高,省去了多线程的上下文切换的
基本命令:
String命令:
set key value 设置键值对
appen key value 追加值

exists key 判断是否存在键 存在返回1 否则返回0

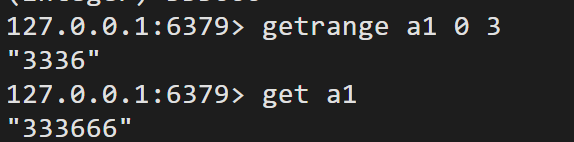
get key 获取键值
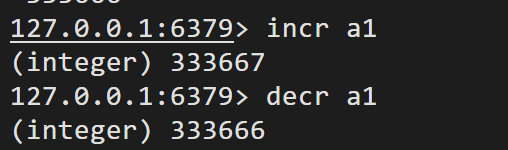
incr key 自动增长1
decr key 自动减1
incrby key num 按步长自动增加
dedrby key num 按步长自动减少
getrange key start end 按照去区间截取字符串
setrange key start value 替换指定位置开始的字符串
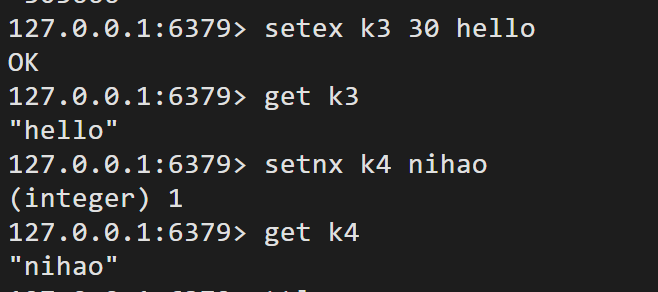
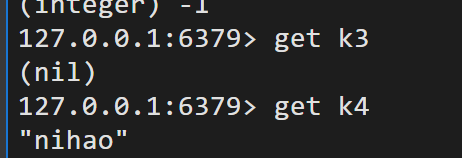
setnx key value 不存在键则设置,存在则不操作(f常用在分布式锁中)
setex key expire value 设置过期时间
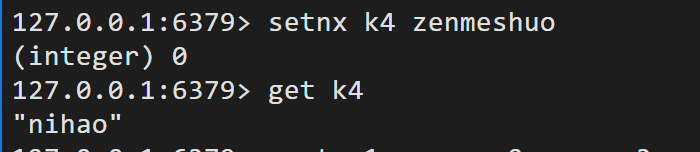
mset(msetnx) key1 value1 key2 value2...... 一次性设置多个键值对,原子性操作(一个操作失败,全部都失败)
mget key1 key2...... 一次性获取多个键值对
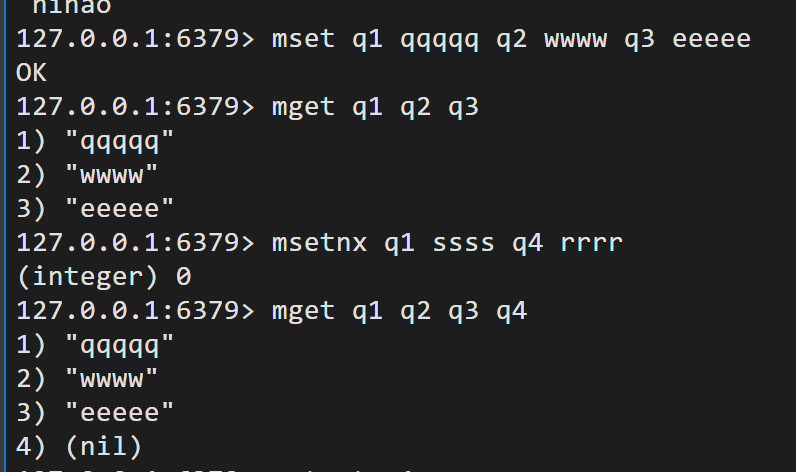
getset 先get再set
List命令:
所有的list命令都是以l开头
lpush/rpush kay value
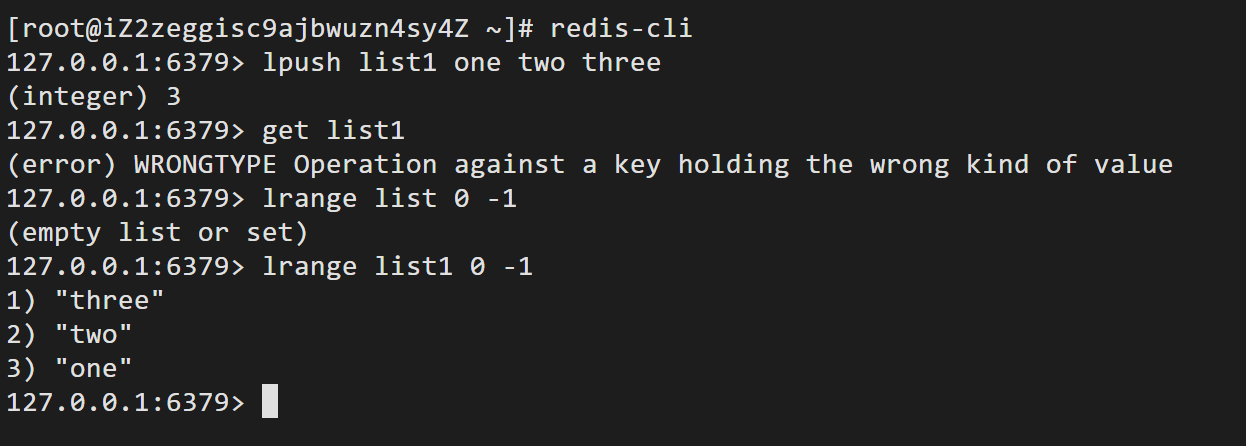
lpop/rpop 从左/右边弹出第一个元素
lindex key index
llen key 获取长度
lrem key count value 移除指定值
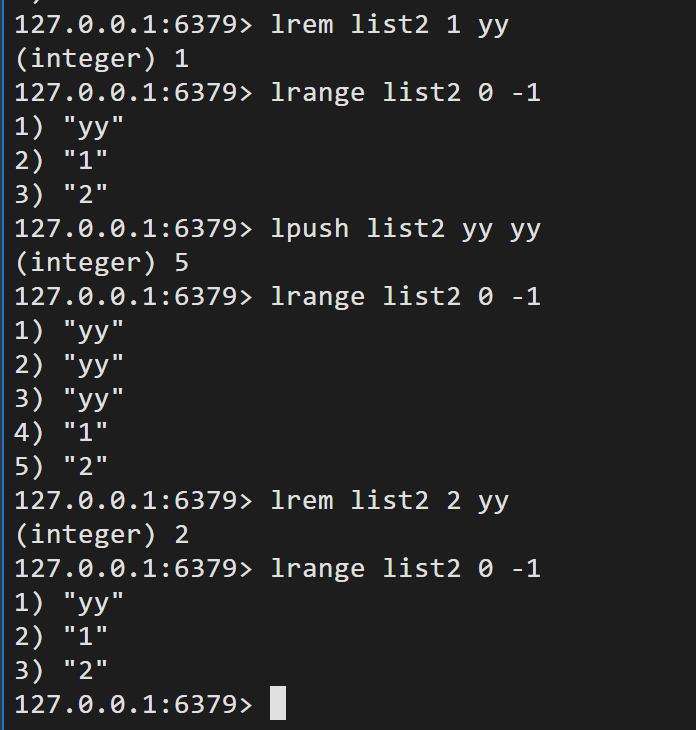
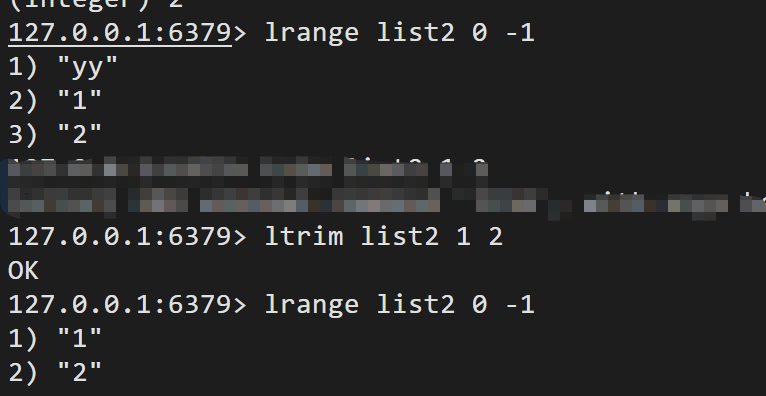
trim key start end 修剪
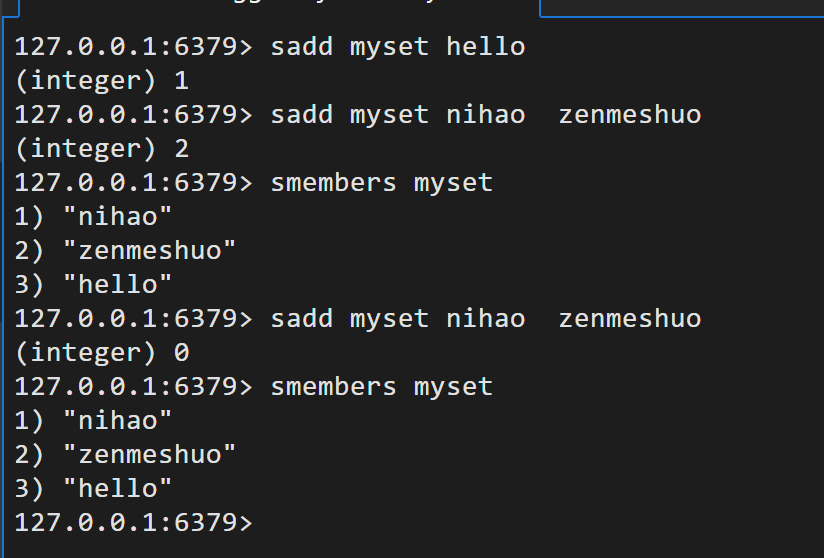
Set命令:无序不重复集合
命令都是以s开头
sadd key value1 value2
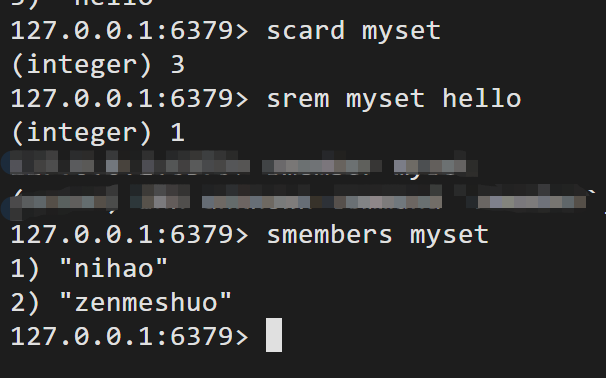
srem key 移除
zset
hash:key-<key,value>(map)集合
Redis三大问题:击穿,穿透,雪崩
1.击穿:这对一个热点key,在key过期的瞬间,大量请求打到了数据库,给数据库造成巨大压力,这就是击穿
解决: 1.如果key特殊的话,可以设置永不过期
2.加锁,在第一个请求没有结束之前,拒绝后续请求,不过高并发分布式锁对是个考验
2.穿透:针对不存在的key在,瞬间大量请求打到数据库,给数据库造成压力
解决: 1.布隆过滤器,将所有可能存在的数据通过hash存储,不存在的请求直接拦截,但有一定的出错几率
2.设置空值,请求不存在的key直接返回null,不推荐,null也占内存而且万一将来有了数据就不统一了
3.雪崩:针对大量key同时失效或者直接缓存失效,大量请求打到数据库
解决: 1.事前:
给这些同一时间过期的加上随机数,是他们在不同时间过期
集群+主从-哨兵
2.事中:限流降级,限制请求数量,超过的降级,直接返回默认值或者空或者某些消息
3.事后:redis数据持久化快照或日志,一旦失效马上恢复

