
SQL -去重Group by 和Distinct的效率
经实际测试,同等条件下,5千万条数据,Distinct比Group by效率高,但是,这是有条件的,这五千万条数据中不重复的仅仅有三十多万条,这意味着,五千万条中基本都是重复数据。
为了验证,重复数据是否对其有影响,本人针对80万条数据进行测试:
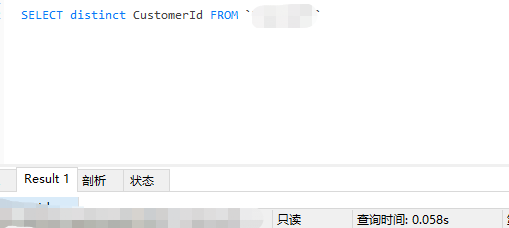
下面是对CustomerId去重,CustomerId的重复项及其多,80万条中仅仅50条不重复的。可以看到,Distinct快一点。
用例1:

用例2:


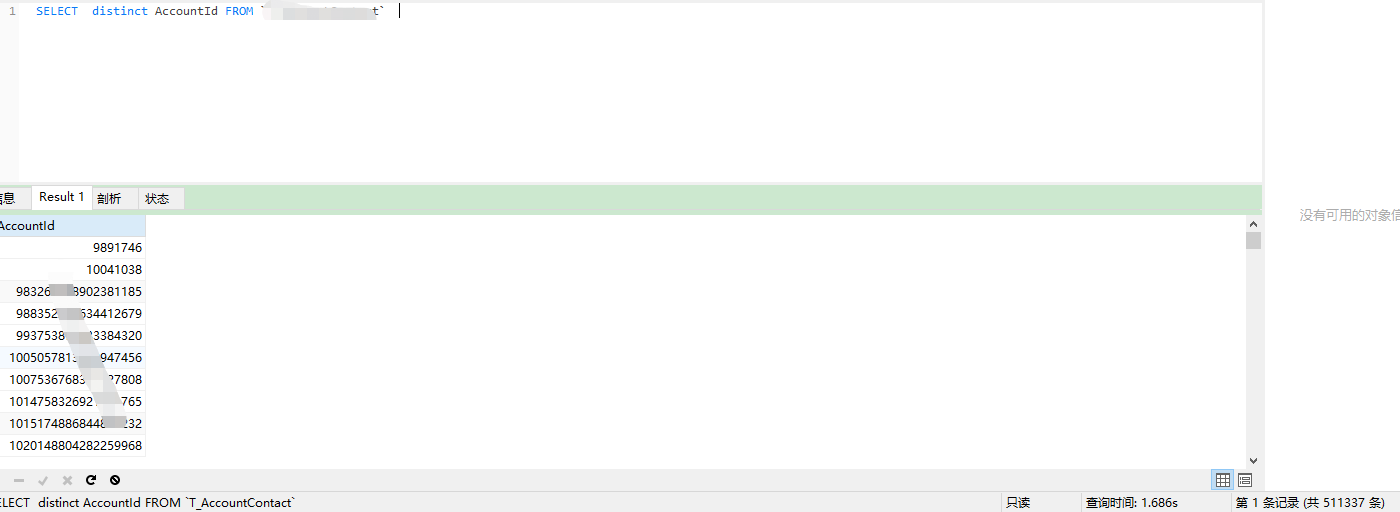
下面是对Id去重,Id基本唯一,80万条中没有重复的。可以看到,Group By更快。


综上所述,其他条件一定时,数据重复项越多,distinct效率越高,反之,数据越唯一,group by效率越高。(测试用例较少,时间差距其实不明显,受电脑影响,数据有时不准。所以具体数据具体试验,不要盲目使用,人云亦云。)
原因:
distinct需要将列中的全部内容都存储在一个内存中,可以理解为一个hash结构,key为列的值,最后计算hash结构中有多少个key即可得到结果。
很明显,需要将所有不同的值都存起来,因此重复数据越多,需要存储的不同项也越少。但这种方式内存消耗可能较大,看你电脑。
而group by的方式是先将列排序。而数据库中的group一般使用sort的方法,即数据库会先对列进行排序。而排序的基本理论是,时间复杂为nlogn,空间为1.,然后只要单纯的计数就可以了。优点是空间复杂度小,缺点是要进行一次排序,执行时间会较长。
两中方法各有优劣,在使用的时候,我们需要根据实际情况进行取舍,不要一刀切。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号