Kafka高性能原因
概述
简单回顾下Kafka消息,Kafka中的消息以主题(Topic)为单位进行分类,主题是一个逻辑上的概念,主题还可以细分为一个或多个分区,一个分区只属于单个主题,所以也可以把分区称为主题分区(Topic-Partition)。同一个主题下的不同分区包含的消息是不同的,每个分区还可以有多个副本用于容灾备份。分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。offset是消息在分区中的唯一标识,Kafka通过它来保证消息在分区内的顺序性,不过offset并不跨越分区,也就是说,Kafka保证的是分区有序而不是主题有序。下图表示了主题、分区、副本、日志之间的关系:一个主题包含至少一个分区,一个分区可以有一个或多个副本,每个副本对应一个日志(实际上是个目录),每个日志里包含多个日志分段(是根据偏移量offset进行分段的),每个日志分段存储日志文件、索引文件等。
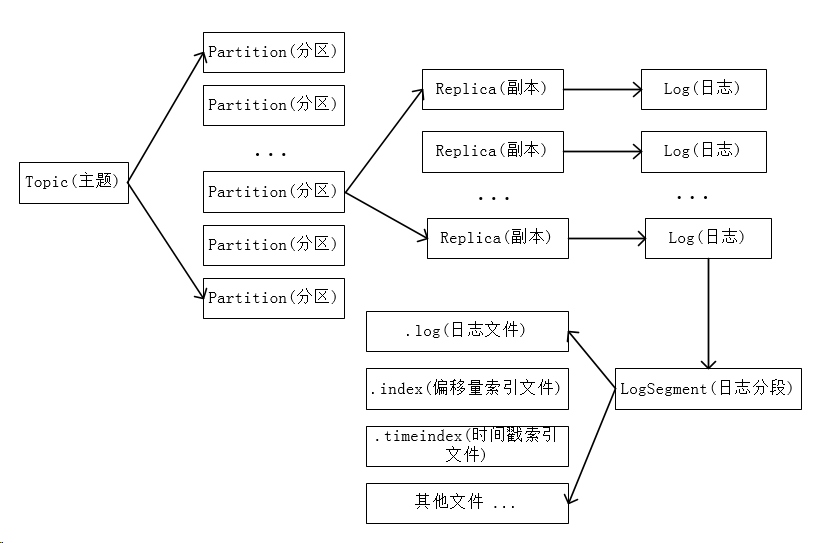
这里还要单独提一下分区的副本。分区使用多副本机制来提升可靠性,每个分区的副本分为leader副本和follower副本,只有leader副本对外提供读写服务,follower副本只负责在内部进行消息同步。如果一个分区的leader副本不可用,Kafka就会从follower副本中选举出一个新的leader副本。Kafka集群的一个broker最多只能有一个分区的一个副本。leader副本所在的broker节点可以称为分区的leader节点,follower副本所在的broker节点就称为分区的follower节点。如果以一个broker上面的拥有不同分区的leader副本太多,就意味着这个leader需要对外承载更大的读写请求,所以一般把不同分区的leader副本均匀地分配到Kafka集群的不同broker节点上。
Kafka高性能的原因就在以下几个方面:
- 分区
- 日志分段存储
- 消息顺序追加
- 页缓存
- 零拷贝
1. 分区
生产者往Kafka发送消息时必须指定发往哪个主题,消费者需要订阅某个主题才能进行消费。一个主题下的分区可以分布在集群的不同broker上面,也就是说,一个主题可以横跨多个broker。这样的话,生产者在指定主题(可以指定也可以不指定分区)发送消息的时候,Kafka会将消息分发至不同的分区,如果这些分区不在同一个broker上,就相当于并发的写入多台broker,性能自然要比写入单台broker要高。对于消费者,Kafka引入了消费组(Consumer Group)的概念,每个消费者都有一个对应的消费组。一个分区只能被一个消费组中的一个消费者消费,但是可以被不同消费组中的另一个消费者消费。可以在一个消费组里起多个消费者,每个消费者消费一个分区,这样就提高了消费者的性能。需要注意的是,消费组里的消费者个数如果多于分区数的话,那些多出来的消费者就会处于空闲状态,所以一个消费组里的消费者个数跟分区数相等就好了。下图展示了消费者组与分区的关系。
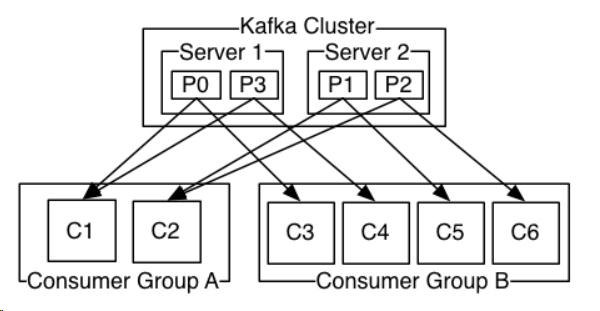
分区的设计使得Kafka消息的读写性能可以突破单台broker的I/O性能瓶颈,可以在创建主题的时候指定分区数,也可以在主题创建完成之后去修改分区数,通过增加分区数可以实现水平扩展,但是要注意,分区数也不是越多越好,一般达到某一个阈值之后,再增加分区数性能反而会下降,具体阈值需要对Kafka集群进行压测才能确定。
2. 日志分段存储
为了防止日志(Log)过大,Kafka引入了日志分段(LogSegment)的概念,将日志切分成多个日志分段。在磁盘上,日志是一个目录,每个日志分段对应于日志目录下的日志文件、偏移量索引文件、时间戳索引文件(可能还有其他文件)。
向日志中追加消息是顺序写入的,只有最后一个日志分段才能执行写入操作,之前所有的日志分段都不能写入数据。
为了便于检索,每个日志分段都有两个索引文件:偏移量索引文件和时间戳索引文件。每个日志分段都有一个基准偏移量baseOffset,用来表示当前日志分段中第一条消息的offset。偏移量索引文件和时间戳索引文件是以稀疏索引的方式构造的,偏移量索引文件中的偏移量和时间戳索引文件中的时间戳都是严格单调递增的。查询指定偏移量(或时间戳)时,使用二分查找快速定位到偏移量(或时间戳)的位置。可见Kafka中对消息的查找速度还是非常快的。
3. 消息顺序追加
Kafka是通过文件追加的方式来写入消息的,只能在日志文件的最后追加新的消息,并且不允许修改已经写入的消息,这种方式就是顺序写磁盘,而顺序写磁盘的速度是非常快的。
4. 页缓存
页缓存是操作系统实现的一种主要的磁盘缓存,以此用来减少对磁盘I/O的操作。具体来说,就是把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问。
Kafka中大量使用了页缓存,消息都是先被写入页缓存,再由操作系统负责具体的刷盘任务(Kafka中也提供了同步刷盘和间断性强制算盘的功能)。
5. 零拷贝
零拷贝技术是一种避免CPU将数据从一块存储拷贝到另一块存储的技术。Kafka使用零拷贝技术将数据直接从磁盘复制到网卡设备缓冲区中,而不需要经过应用程序的转发。
通常应用程序将磁盘上的数据传送至网卡需要经过4步:
1. 调用read(),将数据从磁盘复制到内核模式的缓冲区;
2. CPU会将数据从内核模式复制到用户模式下的缓冲区;
3. 调用write(),将数据从用户模式下复制到内核模式下的Socket缓冲区;
4. 将数据从内核模式的Socket缓冲区复制到网卡设备。
上面的步骤中,第2、3步将数据从内核模式经过用户模式再绕回内核模式,浪费了两次复制过程。采用零拷贝技术,Kafka可以直接请求内核把磁盘中的数据复制到Socket缓冲区,而不用再经过用户模式。
参考文献
- 《深入理解Kafka:核心设计与实践原理》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号