centos 6.5 搭建zookeeper集群
为什么使用Zookeeper?
大部分分布式应用需要一个主控、协调器或控制器来管理物理分布的子进程(如资源、任务分配等)
目前,大部分应用需要开发私有的协调程序,缺乏一个通用的机制
协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器
ZooKeeper:提供通用的分布式锁服务,用以协调分布式应用
Zookeeper能帮我们做什么?
Hadoop2.0,使用Zookeeper的事件处理确保整个集群只有一个活跃的NameNode,存储配置信息等.
HBase,使用Zookeeper的事件处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等.
Zookeeper的特性
Zookeeper是简单的
Zookeeper是富有表现力的
Zookeeper具有高可用性
Zookeeper采用松耦合交互方式
Zookeeper是一个资源库
我们使用三台机器搭建Zookeeper集群
设置ip地址与机器名分别为:
192.168.100.104 hadoop4
192.168.100.105 hadoop5
192.168.100.106 hadoop6
1、 修改机器IP 可以在网络连接中直接使用鼠标操作
2、 修改机器名vim /etc/sysconfig/network 修改如下配置:HOSTNAME=机器名称,HOSTNAME=为你的机器名称,三台机器分别设置为:hadoop4、hadoop5、hadoop6
3、 修改机器名称与IP地址对应关系:vim /etc/hosts
添加如下配置:
192.168.100.104 hadoop4
192.168.100.105 hadoop5
192.168.100.106 hadoop6
4、 上传并解压zookeeper-3.4.5.tar.gz进入zookeeper-3.4.5目录创建zoo.cfg文件使用命令(mv zoo_sample.cfg zoo.cfg)
修改zoo.cfg文件
dataDir=/usr/zookeeper-3.4.5/data
在文件底部添加如下配置:
server.4=hadoop4:2888:3888
server.5=hadoop5:2888:3888
server.6=hadoop6:2888:3888
保存退出
zook.cfg文件内容如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/zookeeper/data
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.4=hadoop4:2888:3888
server.5=hadoop5:2888:3888
server.6=hadoop6:2888:3888
1.tickTime:CS通信心跳时间
Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
tickTime=2000
2.initLimit:LF初始通信时限
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
initLimit=5
3.syncLimit:LF同步通信时限
集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
syncLimit=2
4.dataDir:数据文件目录
Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
dataDir=/usr/zookeeper/data
5.clientPort:客户端连接端口
客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
clientPort=2181
6.服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口)
这个配置项的书写格式比较特殊,规则如下:
server.N=YYY:A:B
server.4=hadoop4:2888:3888
server.5=hadoop5:2888:3888
server.6=hadoop6:2888:3888
5、 创建myid文件:在zoo.cfg中设置的dataDir对应的目录中(/usr/zookeeper-3.4.5/data)创建myid文件
并添加如下内容:echo “N” > myid (N为唯一id(最方便可以写机器名称最后一位数字))
添加内容以后:touch myid
注意三台机器都要设置
6、 启动zookeeper进入zookeeper-3.4.5的bin目录:./zkServer.sh start 注意三台机器都要启动
使用 ./zkServer.sh status 可以查看状态,三台机器中有一台会是leader状态其它是follower状态
7、 测试zookeeper
进入zookeeper-3.4.5的bin目录:./zkCli.sh

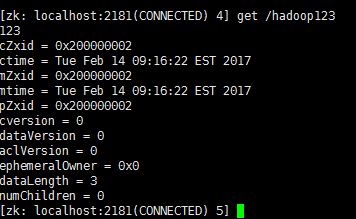
创建一个文件 create /hadoop123 “123test”
使用另外一台机器登录zookeeper: ./zkCli.sh
获取hadoop123文件内容:get hadoop123


 浙公网安备 33010602011771号
浙公网安备 33010602011771号