CentOS 7 的hadoop-3.0.3集群环境搭建
一、基础环境
说明:1.本文基于CentOS 7 操作系统,CentOS-7-x86_64-Minimal-1804.iso。
2.hadoop使用的版本是hadoop-3.0.3.tar.gz。
注:附上本人已搭建好的Hadoop集群环境的master主机文件,可下载后克隆另外两slave从机,即可。
链接: https://pan.baidu.com/s/16lXWV4-JtAXC1BFyVTgAFg 提取码: 3923 复制这段内容后打开百度网盘手机App,操作更方便哦
在Linux上安装Hadoop之前,需要准备好如下基础环境配置:
1. 创建3台虚拟机,分别命名为:master(主节点)、slave1(从节点)、slave2(从节点);
2. 分别配置好3台虚拟机的静态IP,我的:master(192.168.70.10)、slave1(192.168.70.20)、slave2(192.168.70.30);
3. 分别将3台虚拟机重名主机名,并做好IP与主机名的域名映射;
4. 关闭3台虚拟机的防火墙,配置好3台机器的免密登录(SSH);
5. 将3台虚拟机进行网络时间同步;
6. 3台虚拟机都需安装同版本的JDK,要求安装路径绝对一致。
注:jdk配置文件参考
#JAVA JAVA_HOME=/usr/local/jdk1.8.0_191 JRE_HOME=$JAVA_HOME/jre CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export JAVA_HOME JRE_HOME CLASS_PATH PATH
一、hadoop安装配置
注:以下操作都是在master主机(namenode)上完成,除非特别申明。
1.使用rz命令上传hadoop-3.0.3.tar.gz压缩包至master主机,建议在master主机根目录下建立目录/data,用来存放hadoop解压文件;
建立目录命令:
mkdir data
解压压缩包命令:(/data为指定的目录)
tar -zxvf hadoop-3.0.3.tar.gz -C /data
2.配置(全局)环境变量:命令:
vi /etc/profile
配置内容:
#HADOOP HADOOP_HOME=/root/data/hadoop-3.0.3 PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_HOME export PATH export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_ROOT_LOGGER=INFO,console export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" #避免因为缺少用户定义造成的错误 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
注:~/.bashrc(局部)配置文件不要做任何改动
3.然后将这些目录通过scp命令拷贝到Slave1和Slave2的相同目录下
命令:
scp -r /etc/profile root@slave1:/etc/
scp -r /etc/profile root@slave2:/etc/
然后在3台虚拟机上分别运行命令:
source /etc/profile
4.补全配置文件
进入hadoop-3.0.3的配置目录:
cd /root/data/hadoop-3.0.3/etc/hadoop
a.在hadoop-env.sh文件上添加:
export JAVA_HOME=/usr/local/jdk1.8.0_191
b.在workers文件上,删除localhost,加入slave虚拟机的名称一行一个。例如我的是
slave1
slave2
c、创建文件目录
为了便于管理,给Master的hdfs的NameNode、DataNode及临时文件,在用户目录下创建目录:
mkdir /data/hdfs/tmp mkdir /data/hdfs/var mkdir /data/hdfs/logs mkdir /data/hdfs/dfs mkdir /data/hdfs/data mkdir /data/hdfs/name mkdir /data/hdfs/checkpoint mkdir /data/hdfs/edits
注:一定要按要求创建,因为上述2)、配置文件中使用到该部分的目录。
然后将这些目录通过scp命令拷贝到Slave1和Slave2的相同目录下。
scp -r /data/hdfs root@slave1:/data
scp -r /data/hdfs root@slave2:/data
d.依次修改core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml文件.
1)、core-site.xml
<configuration> <property> <name>fs.checkpoint.period</name> <value>3600</value> </property> <property> <name>fs.checkpoint.size</name> <value>67108864</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/root/data/hdfs/tmp</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration>
2)、hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/root/data/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/root/data/hdfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:50090</value> </property> <property> <name>dfs.namenode.http-address</name> <value>master:50070</value> <description> The address and the base port where the dfs namenode web ui will listen on. If the port is 0 then the server will start on a free port. </description> </property> <property> <name>dfs.namenode.checkpoint.dir</name> <value>file:/root/data/hdfs/checkpoint</value> </property> <property> <name>dfs.namenode.checkpoint.edits.dir</name> <value>file:/root/data/hdfs/edits</value> </property> </configuration>
3)、mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.job.tarcker</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
4)、yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandle</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tarcker.address</name>
<value>master:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8040</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
5.将master(主机)上的拷贝hadoop安装文件到子节点,在主节点(master)上执行:
scp -r /data/hadoop-3.0.3 root@slave1:/data
scp -r /data/hadoop-3.0.3 root@slave2:/data
6.启动,在master上进入cd /data/hadoop-3.0.3/etc/hadoop目录,运行:(不报错并在倒数五六行左右有一句 successfully。。。。即成功)
hdfs namenode -format
注:此命令在初次搭建后,执行一次即可,请勿重复执行!!!若重复(两次及以上)执行,则需删除hdfs目录下的临时文件(三台机器都要删除),再重新操作。
7.推荐使用命令:
start-dfs.sh
start-yarn.sh
启动集群,或者使用命令:(二选一)
start-all.sh
8.运行完后输入jps可看到master下的节点:
6032 ResourceManager 5793 SecondaryNameNode 5538 NameNode 6355 Jps
在slave1上输入jps可以看到从节点:
2440 Jps 2316 NodeManager 2206 DataNode
在slave2上输入jps可以看到从节点:
2342 Jps 2217 NodeManager 2107 DataNode
如此表示成功。
9.测试,打开浏览器输入:http://192.168.70.10:50070
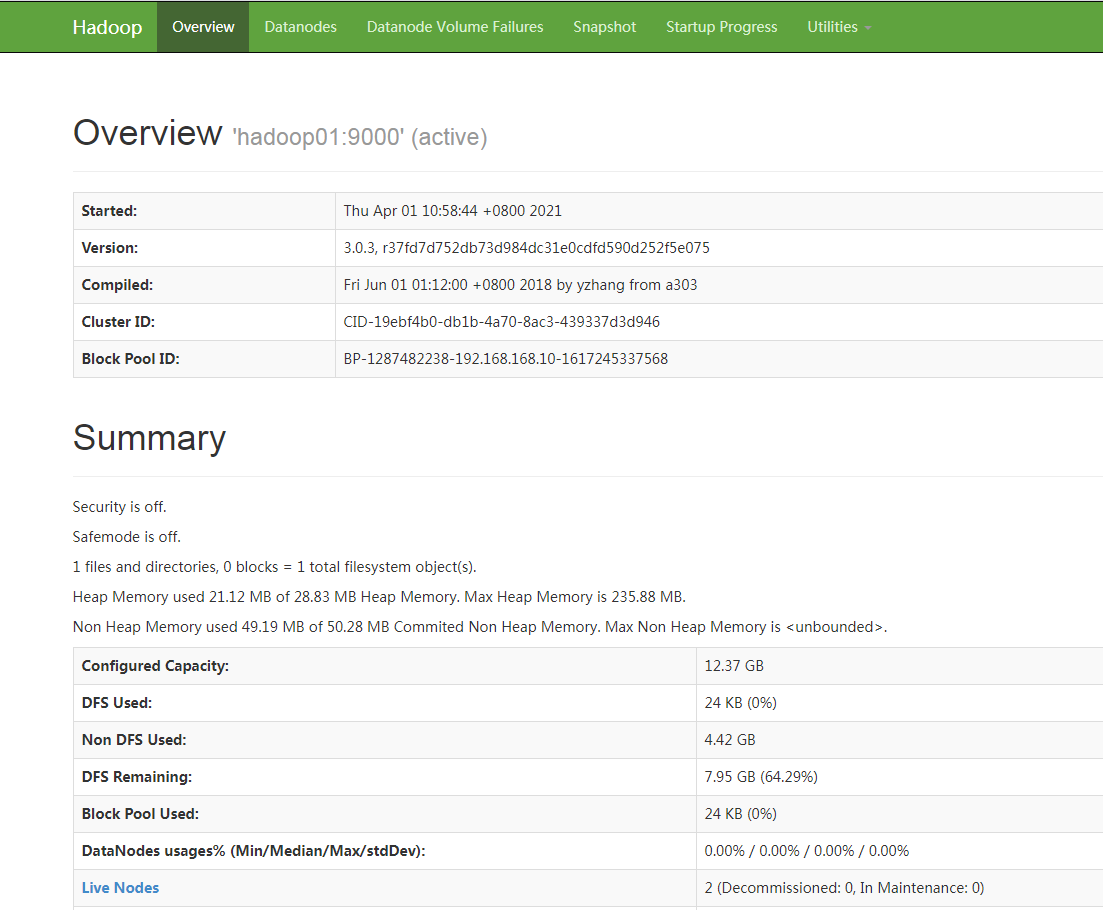
10.打开浏览器输入:http://192.168.70.10:8088
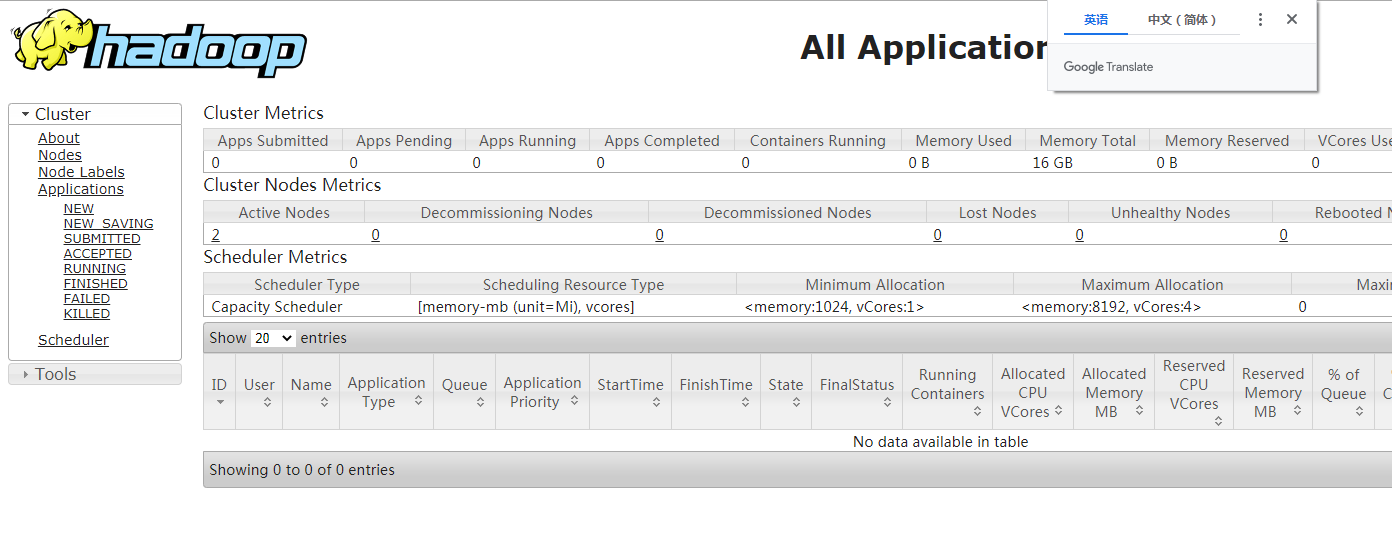
至此,Hadoop集群环境搭建成功!!!
三、注意事项
1.jps实际上是Java进程,若显示“不是命令”,则原因是jdk地址路径问题,找到配置文件,检查更新。
2.三台机器一定要设定ssh登录。
3.Linux系统一定要关闭selinux。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号