
Python RegEx
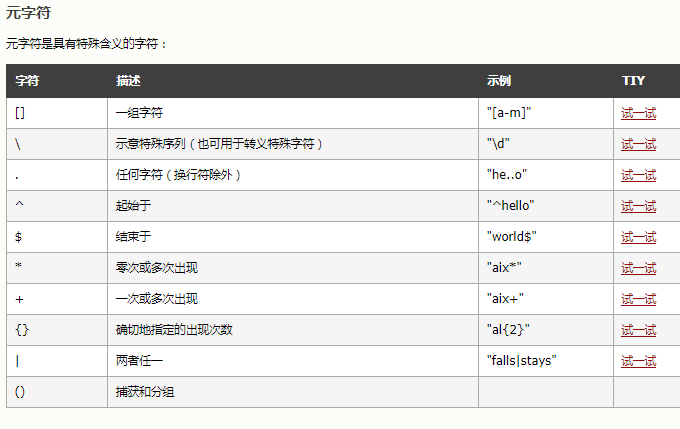
RegEx 或正则表达式是形成搜索模式的字符序列。
RegEx 可用于检查字符串是否包含指定的搜索模式。
RegEx 模块
Python 提供名为 re 的内置包,可用于处理正则表达式。
导入 re 模块:
#引入 正则 import re text='china is a great country' x=re.search('^china.*country$',text)#<re.Match object; span=(0, 24), match='china is a great country'> print(x) if (x): print('YES,this is at least on meatch')#YES,this is at least on meatch else: print('NO MEACH')
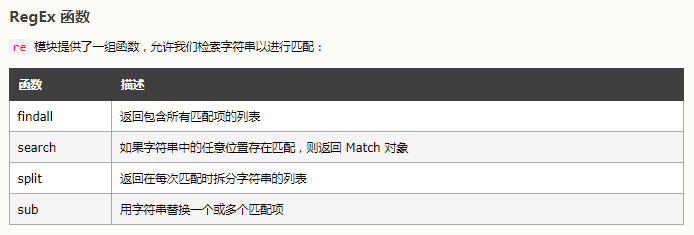
常用的几个正则方法
finall()函数返回 函数返回包含所有匹配项的列表。
#如果未找到匹配,则返回空列表:
split() 函数返回一个列表,其中字符串在每次匹配时被拆分:
#您可以通过指定 maxsplit 参数来控制拆分次数:
search() 函数搜索字符串中的匹配项,如果存在匹配则返回 Match 对象
#如果有多个匹配,则仅返回首个匹配项:search()方法
#如果未找到匹配,则返回值 None
search() 方法 后还可以接
.string 返回原始字符串
.span() 返回匹配到的元组的起始位置到结束为止
.group() 返回匹配的字符串部分
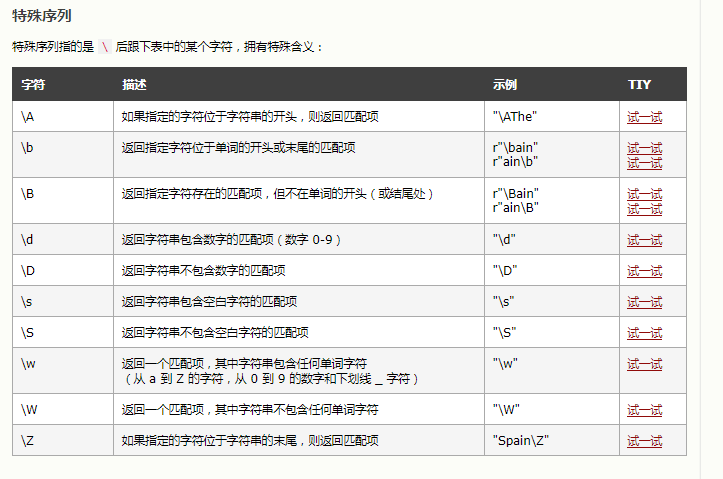
#引入 正则 import re text = 'china is a great country' #search() 函数搜索字符串中的匹配项,如果存在匹配则返回 Match 对象。 #如果有多个匹配,则仅返回首个匹配项:search()方法 #如果未找到匹配,则返回值 None str = re.search('\s', text) print('The first white-space is located in position: ', str.start()) #The first white-space is located in position: 5 # split() 函数返回一个列表,其中字符串在每次匹配时被拆分: #您可以通过指定 maxsplit 参数来控制拆分次数: str1 = re.split('\s', text) str2 = re.split('\s', text, 1) print(str1) #['china', 'is', 'a', 'great', 'country'] print(str2) #['china', 'is a great country'] #findall()函数返回 函数返回包含所有匹配项的列表。 #如果未找到匹配,则返回空列表: str3 = re.findall('a', text) print(str3) #['a', 'a', 'a'] #sub(a,b,str,num)函数把str中匹配a(中的num个,不填默认全部替换)替换b: #count 参数来控制替换次数: str4 = re.sub('\s','9',text )# str5=re.sub('\s','-hello world-',text,2)# 把空格替换成 '-hello world-' 替换次数是2 print(str4)#china9is9a9great9country #空格全部替换成9 print(str5) #Match 对象 #查找含有关搜索和结果信息的对象。 #注释:如果没有匹配,则返回值 None,而不是 Match 对象。 #span() 返回的元组包含了匹配的开始和结束位置 #.string 返回传入函数的字符串 #group() 返回匹配的字符串部分 text1="China is a great country" str6=re.search(r"\bC\w+",text1) print(str6)#<re.Match object; span=(0, 5), match='China'> print(str6.span())#(0, 5) span() 返回的元组包含了匹配的开始和结束位置 print(str6.string)#China is a great country .string 打印传入的字符串 print(str6.group())# China group() 返回匹配的字符串部分


 浙公网安备 33010602011771号
浙公网安备 33010602011771号