《python自然语言处理》第三章 加工原料文本
本章解决的问题:
1. 编写程序访问本地和网络上的文件(后的语言材料)
2.把文档分割成单独的词和标点符号(加工原料文本)
3.编写程序产生格式化的输出,把结果保存在一个文件中
NLP的流程
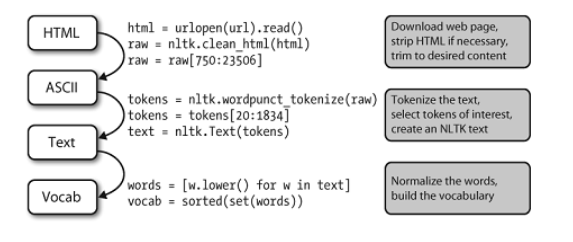
图处理流程:
打开一个URL,读里面HTML格式的内容,去除标记,并选择字符的切片,然后分词,是否转换为nltk.Text对象是可选择的。我们也可以将所有词汇小写并提取词汇表。
在这条流程后面还有很多操作。要正确理解它,这样有助于明确其中提到的每个变量的类型。使用type(x)我们可以找出任一Python对象x的类型,如type(1)是<int>因为1是一个整数。
当我们载入一个URL或文件的内容时,或者当我们去掉HTML标记时,我们正在处理字符串,也就是Python的<str>数据类型:
>>>raw=open('document.txt').read()>>>type(raw) <type'str'>
当我们将一个字符串分词,会产生一个(词的)链表,这是Python的<list>类型。规范化和排序链表产生其它链表:
>>>tokens=nltk.word_tokenize(raw)>>>type(tokens) <type'list'> >>>words=[w.lower()forwintokens]>>>type(words) <type'list'> >>>vocab=sorted(set(words))>>>type(vocab) <type'list'>
导入的包:
from __future__ import division import nltk, re, pprint
从网络上读取文本
from urllib.request import urlopen url = r'http://www.gutenberg.org/files/24272/24272-0.txt' raw = urlopen(url).read() raw = raw.decode('utf-8') print(raw)
#此时 type(raw) 是 <type'str'>
分词
#
tokens = nltk.word_tokenize(raw)
#此时 type(tokens) 为 <type'list'>
text=nltk.Text(tokens)
#此时 type(text) 为 <type'nltk.text.Text'> ,从这个链表创建一个NLTK文本,可以使用第一章语言处理方法
处理HTML
from bs4 import BeautifulSoup
url="http://baidu.com" html = urlopen(url).read() raw = BeautifulSoup(html) # 会将HTML文档中的所有标签清除,返回一个只包含文字的字符串 print(raw.get_text) # 按照标准缩进格式输出 print(raw.prettify())
使用UNICODE进行文字处理
。。。
使用正则表达式检测词组搭配
在Python中使用正则表达式,需要使用importre导入re函数库。还需要一个用于搜索的词汇链表;我们再次使用词汇语料库(2.4节),对它进行预处理消除某些名称。
import re
wordlist=[w for w in nltk.corpus.words.words('en')if w.islower()]
# $美元符号 ,它是正则表达式中有特殊用途的符号,用来匹配单词的末尾
[w for w in wordlist if re.search('ed$',w)]
# 用空格分隔文本
re.split(r' ',raw)
# 遇到空白字符分开
re.split(r'\s+',raw)
# 遇到换行分开
re.split(r'[\n]+',raw)

词形归并
使用nltk库WordNetLemmatizer词形归并
对于任何一个 NLP 流水线,如果想要对相同语义词根的不同拼写形式都做出统一回复的话,那么词形归并工具就很有用,它会减少必须要回复的词的数目,即语言模型的维度。利用词形归并工具,可以让模型更一般化,当然也可能带来模型精确率的降低,因为它会对同一词根的不同拼写形式一视同仁。
from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() # 默认其为名词 print(lemmatizer.lemmatize("better") ) # 如果需要得到更精确的词元,需要告诉 WordNetLemmatizer 你感兴趣的词性是什么。 print(lemmatizer.lemmatize("better", pos="a") ) print(lemmatizer.lemmatize("goods", pos="n") ) new_tokens = [nltk.WordNetLemmatizer().lemmatize(t)for t in tokens]
对字符串的操作
1.访问单个字符(索引)
2.访问子字符串(切片)
3.输出字符串
4.更多操作

读取本地文件
#以读文件的模式打开一个文件对象,使用Python内置的open()函数,传入文件名和标
示符
f=open('C:\\Users\\Yafang\\Desktop\\doc.txt') print(f.read()) for line in f: print(line.strip())#strip()方法删除输入行结尾的换行符
如果文件放在这,就不用写路径
f = open('document.txt') raw = f.read() print(raw)
写回文件
output_file = open('C:\\Users\\Yafang\\Desktop\\doc.txt','w') words = set(nltk.corpus.genesis.words('english-kjv.txt')) for word in sorted(words): output_file.write(word + "\n")

