
Rethinking in my projects
最近在面试过程中,有的面试官针对我的项目问的一些问题令我对自我的项目和经历有了一些新的思考,于是决定花时间来重新整理一下我的项目。
基于美学分析下的多任务CNN显着性分布预测
Motivation: 美学+显著性强相关
多任务CNN
Multitask Learning (MTL) is an inductive transfer mechanism whose principle goal is to improve generalization performance. MTL improves generalization by leveraging the domain-specific information contained in the training signals of related tasks. It does this by training tasks in parallel while using a shared representation.
多任务学习是一种归纳迁移机制,基本目标是提高泛化性能。多任务学习通过相关任务训练信号中的领域特定信息来提高泛化能力,利用共享表示采用并行训练的方法学习多个任务。
MTL中共享表示有两种方式:
- 基于参数的共享(Parameter based):比如基于神经网络的MTL,高斯处理过程。
- 基于约束的共享(regularization based):比如均值,联合特征(Joint feature)学习(创建一个常见的特征集合)。
多任务学习有效的原因
- 添加噪声。辅助任务中不相关的部分,在学习过程中相当于是噪声,因此,引入噪声可以提高学习的泛化(generalization)效果。
- 解决局部极小值问题。单任务学习时,梯度的反向传播倾向于陷入局部极小值。多任务学习中不同任务的局部极小值处于不同的位置,通过相互作用,可以帮助隐含层逃离局部极小值。
- 添加的任务可以改变权值更新的动态特性,可能使网络更适合多任务学习。比如,多任务并行学习,提升了浅层共享层(shared representation)的学习速率,可能,较大的学习速率提升了学习效果。
- 多个任务在浅层共享表示,可能削弱了网络的能力,降低网络过拟合,提升了泛化效果。
不同层次输出语义信息
在深度网络中,多任务的语义信息还可以从不同的层次输出,例如GoogLeNet中的两个辅助损失层。
另外一个例子比如衣服图像检索系统,颜色这类的信息可以从较浅层的时候就进行输出判断,而衣服的样式风格这类的信息,更接近高层语义,需要从更高的层次进行输出,这里的输出指的是每个任务对应的损失层的前一层。
MTL和其他学习算法的关系
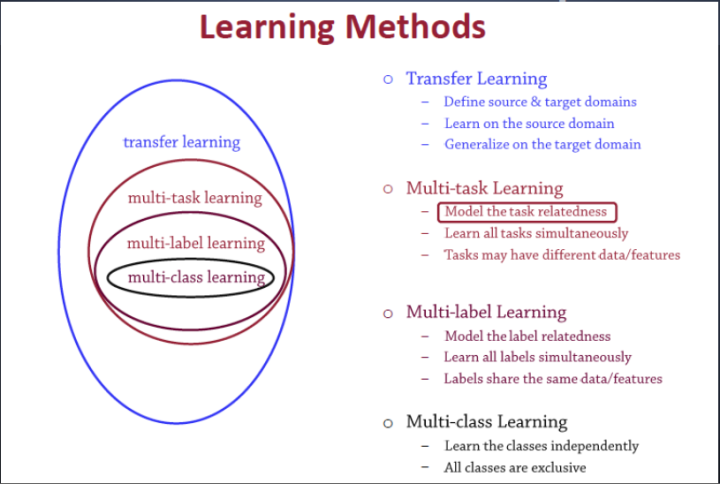
关于迁移学习的理解,参考《深度学习模型-13 迁移学习(Transfer Learning)技术概述》
训练方式
整合损失
每个任务都有一个定义良好的损失函数,多任务就会有多个损失。如果只是简单相加,不同任务损失的尺度差异非常大,导致整体损失被某一个任务所主导,最终导致其他任务的损失无法影响网络共享层的学习过程。
方案:
- 带权相加,但会引入一个超参数。
- 引入不确定性来确定 MTL 中损失的权重,在每个任务的损失函数中学习另一个噪声参数(noise parameter)。见论文《Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics》以及对应的中文详解。大致意思是,文章认为\(p\left(\mathbf{y} | \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right)\)服从高斯分布,通过最大化对数似然函数(log likelihood)推导出带有可学习的噪声的损失函数(感觉其实就是给每个任务赋予一个可学习的权重)。
调节学习率
不同的任务会有不同的学习率,我们可以在各个支路任务中分别调节各自的学习速率,而在共享网络部分,使用另一个学习速率。在单任务学习中也可使用。
all_variables = shared_vars + a_vars + b_vars
all_gradients = tf.gradients(loss, all_variables)
shared_subnet_gradients = all_gradients[:len(shared_vars)]
a_gradients = all_gradients[len(shared_vars):len(shared_vars + a_vars)]
b_gradients = all_gradients[len(shared_vars + a_vars):]
shared_subnet_optimizer = tf.train.AdamOptimizer(shared_learning_rate)
a_optimizer = tf.train.AdamOptimizer(a_learning_rate)
b_optimizer = tf.train.AdamOptimizer(b_learning_rate)
train_shared_op = shared_subnet_optimizer.apply_gradients(zip(shared_subnet_gradients, shared_vars))
train_a_op = a_optimizer.apply_gradients(zip(a_gradients, a_vars))
train_b_op = b_optimizer.apply_gradients(zip(b_gradients, b_vars))
train_op = tf.group(train_shared_op, train_a_op, train_b_op)
面试反思
- 我的项目中,多任务学习成功的原因是引入了别的数据库还是多任务框架本身呢?
这是在【星环科技】的面试中遇到,其实问题本身的提出是有问题的,因为当多任务监督学习的不同任务使用了同样的训练数据时,这就变成了多标签学习或多输出回归。
相关文章
- 如何利用深度学习模型实现多任务学习?这里有三点经验. https://www.jiqizhixin.com/articles/2019-02-16
- 多任务学习概述论文:从定义和方法到应用和原理分析. https://www.jiqizhixin.com/articles/nsr-jan-2018-yu-zhang-qiang-yang

