5.RDD操作综合实例
一、词频统计
A. 分步骤实现
1、准备文件
1、下载小说或长篇新闻稿

2、上传到hdfs上
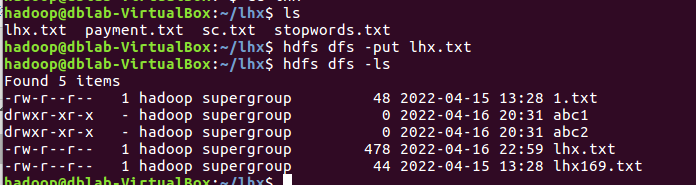
2、读文件创建RDD

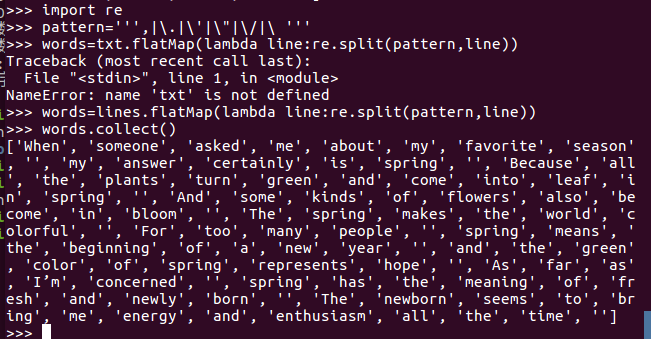
3、分词

4、
标点符号re.split(pattern,str),flatMap(),
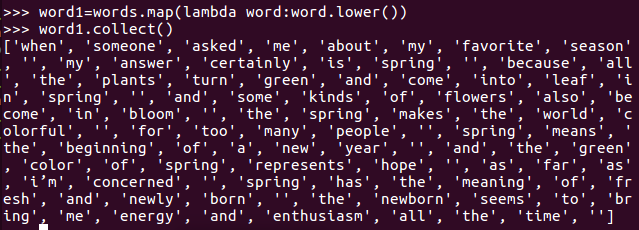
排除大小写lower(),map()
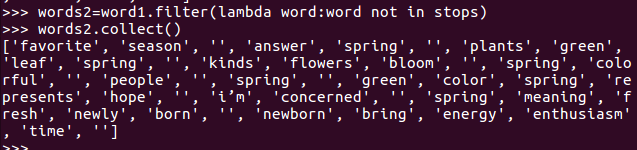
停用词,可网盘下载stopwords.txt,filter()

长度小于2的词filter()

5、统计词频

6、按词频排序
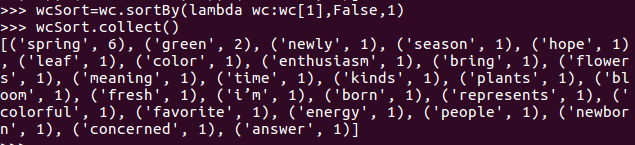
7、输出到文件

8、查看结果

B. 一句话实现:文件入文件出


C.和作业2的“二、Python编程练习:英文文本的词频统计 ”进行比较,理解Spark编程的特点。
在spark中读取数据后数据是一条字符串/一行字符串可叫做一个rdd对象(每个转换算子的操作都会形成新的rdd对象),spark中词频统计需要先用flatMap进行切分并压平,然后处理切分的字符串后形成新的键值对,再对形成的键值对进行词频的统计,然后再排序输出。而在python中,则没有压平等这类操作。而spark中有个特点就是在spark中有着区块数的概念,是多个任务同时进行,而python是按顺序进行的,所以spark主要是对分布式的数据进行处理,而python是对单数据进行处理。
二、求Top值
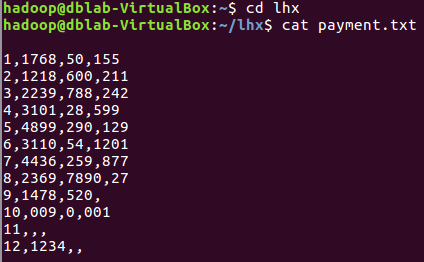
网盘下载payment.txt文件,通过RDD操作实现选出最大支付额的用户。
1、丢弃不合规范的行
读取文件,进行分词操作
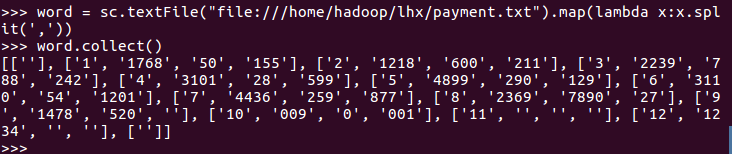
清洗数据,删除空数据行和缺失数据行

2、支付金额转换为数值型,按支付金额排序

3、取出Top3



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构