2.安装Spark与Python练习
一、安装Spark
1、检查基础环境hadoop,jdk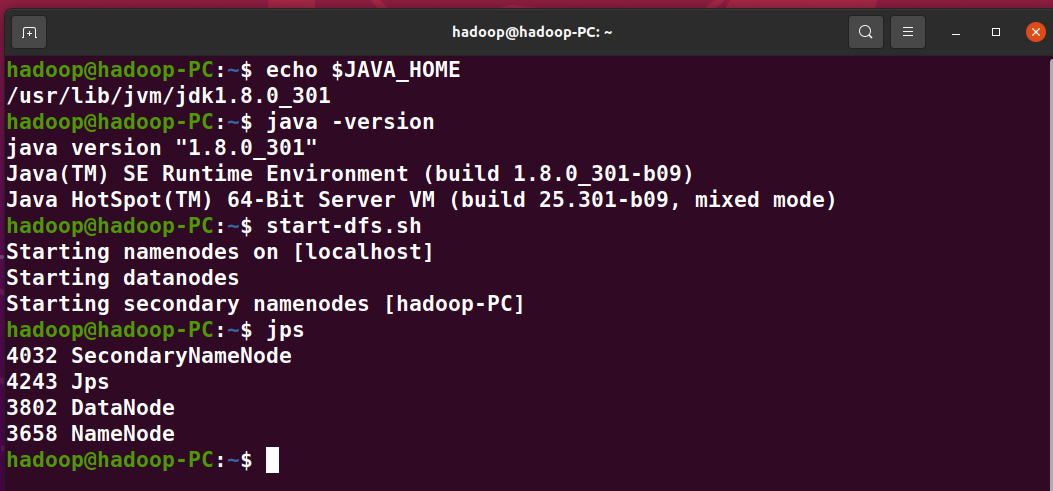
2、下载spark
(省略,原来已下好)
3、解压,文件夹重命名、权限
(省略,原来已下好)
4、配置文件

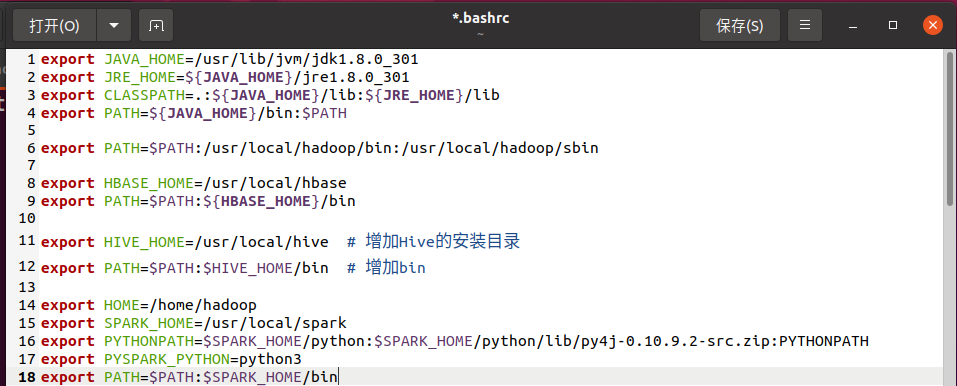
5、环境变量

6、试运行Python代码
试运行spaark
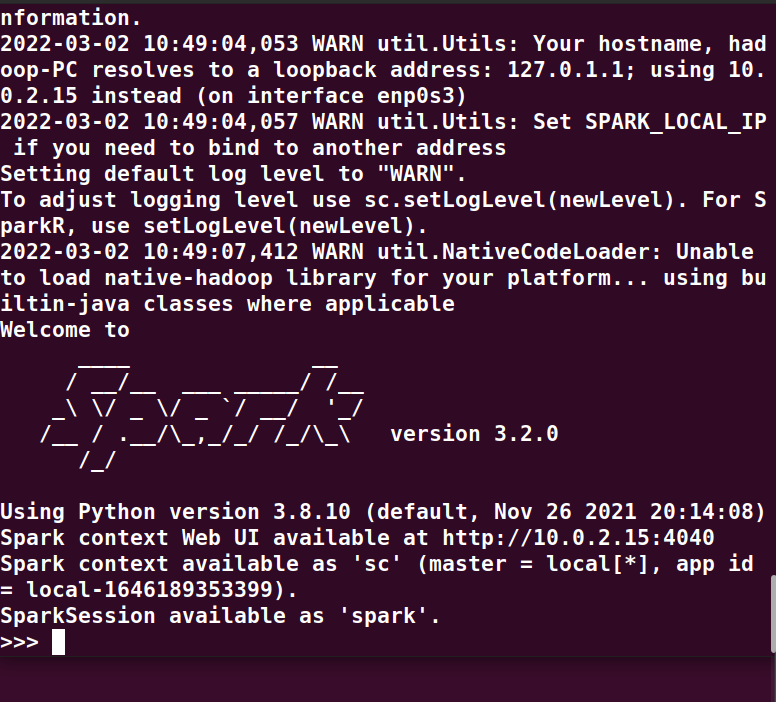
python命令测试

二、Python编程练习:英文文本的词频统计
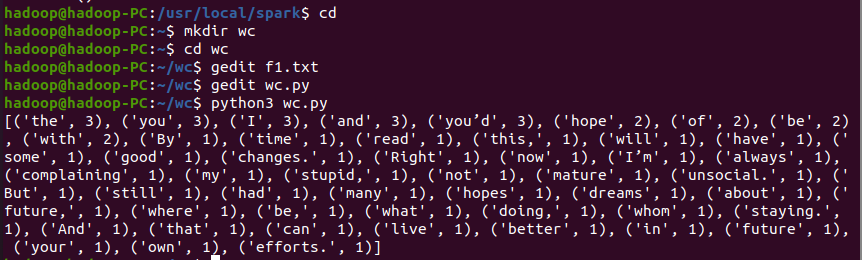
1、准备文本文件
2、读文件
3、预处理:大小写,标点符号,停用词
4、分词
5、统计每个单词出现的次数
6、按词频大小排序
7、结果写文件
代码:

path='/home/hadoop/wc/f1.txt' f=open(path) #读取文件 with open(path) as y: text=y.read() #预处理 words = text.split() #分词 wc={} for word in words: #统计单词出现的次数 wc[word]=wc.get(word,0)+1 wclist=list(wc.items()) wclist.sort(key=lambda x:x[1],reverse=True) #按照词频大小排序 print(wclist)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构