

【深度学习】卷积神经网络中Dropout、BatchNorm的位置选择
前言
卷积神经网络的设计自然要考虑到各层之间的顺序。这种“考虑”既有原理性的解释也有经验方面的原因。本文主要介绍一些层常见的位置选择,并对其原因进行分析,从中提取共性有利于其他模型的设计。
Dropout层的位置
Dropout一般放在全连接层防止过拟合,提高模型返回能力,由于卷积层参数较少,很少有放在卷积层后面的情况,卷积层一般使用batch norm。
全连接层中一般放在激活函数层之后,有的帖子说一定放在激活函数后,个人推测是因为对于部分激活函数输入为0输出不一定为0,可能会起不到效果,不过对于relu输入0输出也是0就无所谓了。
BatchNorm
BatchNorm归一化放在激活层前后好像都有,最初LeNet有一种归一化放在了激活层池化层后面,而现在普遍放在激活层前。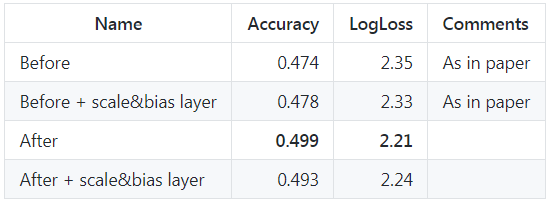
bn原文建议放在ReLU前,因为ReLU的激活函数输出非负,不能近似为高斯分布。但有人做了实验,发现影响不大,放在后面好像还好了一点,放在ReLU后相当于直接对每层的输入进行归一化,如下图所示,这与浅层模型的Standardization是一致的。
所以在激活层前还是后还是很难下定论的,只是现在习惯放在激活层前,区别不是很大,区别大的是是否使用bn。
这里做了很多实验,可以参考:https://github.com/ducha-aiki/caffenet-benchmark/blob/master/batchnorm.md


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2017-12-05 LibUsbDotNet使用方法