

embeding 是什么
要搞清楚embeding先要弄明白他和one hot encoding的区别,以及他解决了什么one hot encoding不能解决的问题,带着这两个问题去思考,在看一个简单的计算例子
以下引用 YJango的Word Embedding–介绍
https://zhuanlan.zhihu.com/p/27830489
One hot representation
程序中编码单词的一个方法是one hot encoding。
实例:有1000个词汇量。排在第一个位置的代表英语中的冠词"a",那么这个"a"是用[1,0,0,0,0,…],只有第一个位置是1,其余位置都是0的1000维度的向量表示,如下图中的第一列所示。
也就是说,
在one hot representation编码的每个单词都是一个维度,彼此independent。
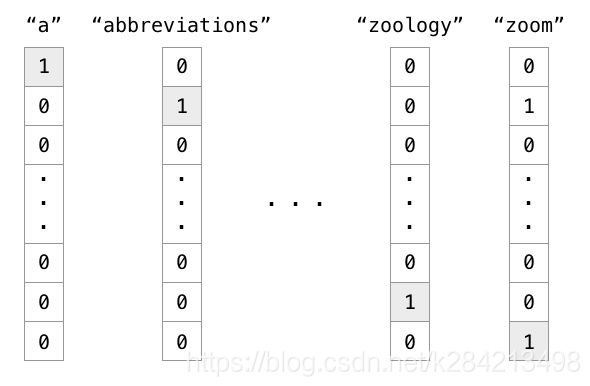
这里我们可以看到One hot方式处理的数据
1、会产生大量冗余的稀疏矩阵
2、维度(单词)间的关系,没有得到体现
继续引用
神经网络分析
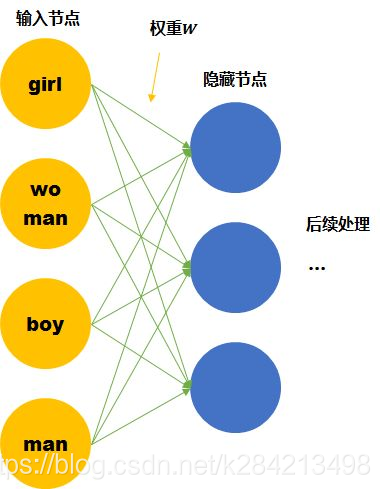
假设我们的词汇只有4个,girl, woman, boy, man,下面就思考用两种不同的表达方式会有什么区别。
One hot representation
尽管我们知道他们彼此的关系,但是计算机并不知道。在神经网络的输入层中,每个单词都会被看作一个节点。 而我们知道训练神经网络就是要学习每个连接线的权重。如果只看第一层的权重,下面的情况需要确定43个连接线的关系,因为每个维度都彼此独立,girl的数据不会对其他单词的训练产生任何帮助,训练所需要的数据量,基本就固定在那里了。
Distributed representation
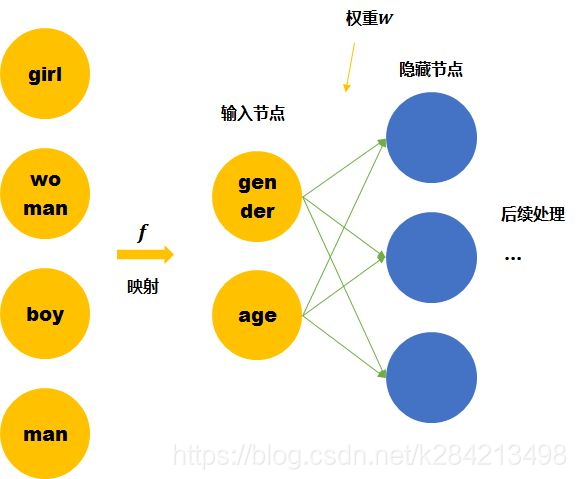
我们这里手动的寻找这四个单词之间的关系 f 。可以用两个节点去表示四个单词。每个节点取不同值时的意义如下表。 那么girl就可以被编码成向量[0,1],man可以被编码成[1,1](第一个维度是gender,第二个维度是age)。
那么这时再来看神经网络需要学习的连接线的权重就缩小到了23。同时,当送入girl为输入的训练数据时,因为它是由两个节点编码的。那么与girl共享相同连接的其他输入例子也可以被训练到(如可以帮助到与其共享female的woman,和child的boy的训练)。
Word embedding也就是要达到第二个神经网络所表示的结果,降低训练所需要的数据量。
Word embedding就是要从数据中自动学习到输入空间到Distributed representation空间的 映射f 。

以上的计算都没有涉及到label,所以训练过程是无监督的
看一个实际代码计算的例子
假设有一个维度为7的稀疏向量[0,1,0,1,1,0,0]。你可以把它变成一个非稀疏的2d向量,如下所示:
model = Sequential()
model.add(Embedding(2, 2, input_length=7))#输入维,输出维
model.compile('rmsprop', 'mse')
model.predict(np.array([[0,1,0,1,1,0,0]]))array([[[ 0.03005414, -0.02224021],
[ 0.03396987, -0.00576888],
[ 0.03005414, -0.02224021],
[ 0.03396987, -0.00576888],
[ 0.03396987, -0.00576888],
[ 0.03005414, -0.02224021],
[ 0.03005414, -0.02224021]]], dtype=float32)这个转换实际上是把[0,1,0,1,1,0,0]增加一个纵向展开的维度
model.layers[0].W.get_value()array([[ 0.03005414, -0.02224021],
[ 0.03396987, -0.00576888]], dtype=float32)通过比较两个数组可以看出0值映射到第一个索引,1值映射到第二个索引。嵌入构造函数的第一个值是输入中的值范围。在示例中它是2,因为我们给出了二进制向量作为输入。第二个值是目标维度。第三个是我们给出的向量的长度。
所以,这里没有什么神奇之处,只是从整数到浮点数的映射。
计算例子的model.layers[0].W.get_value(),就是上面引用图示中的映射f
