

XGBoost、LightGBM、Catboost总结

sklearn集成方法
bagging
常见变体(按照样本采样方式的不同划分)
- Pasting:直接从样本集里随机抽取的到训练样本子集
- Bagging:自助采样(有放回的抽样)得到训练子集
- Random Subspaces:列采样,按照特征进行样本子集的切分
- Random Patches:同时进行行采样、列采样得到样本子集
sklearn-bagging
学习器
- BaggingClassifier
- BaggingRegressor
参数
- 可自定义基学习器
- max_samples,max_features控制样本子集的大小
- bootstrap,bootstrap_features控制是否使用自助采样法
- 当使用自助采样法时,可以设置参数
oob_score=True来通过包外估计来估计模型的泛化误差(也就不需要进行交叉验证了)
- 当使用自助采样法时,可以设置参数
Note:方差的产生主要是不同的样本训练得到的学习器对于同一组测试集做出分类、预测结果的波动性,究其原因是基学习器可能学到了所供学习的训练样本中的局部特征或者说是拟合了部分噪声数据,这样综合不同的学习器的结果,采取多数表决(分类)或者平均(回归)的方法可以有效改善这一状况
sklearn-forests of randomized trees
学习器
- RandomForest: 采取自主采样法构造多个基学习器,并且在学习基学习器时,不是使用全部的特征来选择最优切分点,而是先随机选取一个特征子集随后在特征子集里挑选最优特征进行切分;这种做法会使得各个基学习器的偏差略微提升,但在整体上降低了集成模型的方差,所以会得到整体上不错的模型
- RandomForestClassifier
- RandomForestRegressor
Notes:
- 不同于原始的模型实现(让各个基学习器对样本的分类进行投票),sklearn里随机森林的实现是通过将各个基学习器的预测概率值取平均来得到最终分类
-
随机森林的行采样(bagging)和列采样(feature bagging)都是为了减小模型之间的相关性使基学习器变得不同从而减小集成模型的方差
-
Extra-Trees(extremely randomized trees):相较于rf进一步增强了随机性,rf是对各个基学习器随机挑选了部分特征来做维特征子集从中挑选最佳的特征切分,而Extra-Trees更进一步,在特征子集里挑选最佳特征时不是选择最有区分度的特征值,而是随机选择这一划分的阈值(该阈值在子特征集里的特征对应的采样后的样本取值范围里随机选取),而不同的随机阈值下的特征中表现最佳的作为划分特征,这样其实增强了随机性,更进一步整大了基学习器的偏差但降低了整体的方差
- ExtraTreesClassifier
- ExtraTreesRegressor
调参
- 最重要的两个参数
- n_estimators:森林中树的数量,初始越多越好,但是会增加训练时间,到达一定数量后模型的表现不会再有显著的提升
- max_features:各个基学习器进行切分时随机挑选的特征子集中的特征数目,数目越小模型整体的方差会越小,但是单模型的偏差也会上升,经验性的设置回归问题的max_features为整体特征数目,而分类问题则设为整体特征数目开方的结果
- 其他参数
- max_depth:树的最大深度,经验性的设置为None(即不设限,完全生长)
- min_samples_split,节点最小分割的样本数,表示当前树节点还可以被进一步切割的含有的最少样本数;经验性的设置为1,原因同上
- bootstrap,rf里默认是True也就是采取自助采样,而Extra-Trees则是默认关闭的,是用整个数据集的样本,当bootstrap开启时,同样可以设置oob_score为True进行包外估计测试模型的泛化能力
- n_jobs,并行化,可以在机器的多个核上并行的构造树以及计算预测值,不过受限于通信成本,可能效率并不会说分为k个线程就得到k倍的提升,不过整体而言相对需要构造大量的树或者构建一棵复杂的树而言还是高效的
- criterion:切分策略:gini或者entropy,默认是gini,与树相关
- min_impurity_split–>min_impurity_decrease:用来进行早停止的参数,判断树是否进一步分支,原先是比较不纯度是否仍高于某一阈值,0.19后是判断不纯度的降低是否超过某一阈值
- warm_start:若设为True则可以再次使用训练好的模型并向其中添加更多的基学习器
- class_weight:设置数据集中不同类别样本的权重,默认为None,也就是所有类别的样本权重均为1,数据类型为字典或者字典列表(多类别)
- balanced:根据数据集中的类别的占比来按照比例进行权重设置n_samples/(n_classes*np.bincount(y))
- balanced_subsamples:类似balanced,不过权重是根据自助采样后的样本来计算
方法
- predict(X):返回输入样本的预测类别,返回类别为各个树预测概率均值的最大值
- predict_log_proba(X):
- predict_proba(X):返回输入样本X属于某一类别的概率,通过计算随机森林中各树对于输入样本的平均预测概率得到,每棵树输出的概率由叶节点中类别的占比得到
- score(X,y):返回预测的平均准确率
特征选择
特征重要性评估:一棵树中的特征的排序(比如深度)可以用来作为特征相对重要性的一个评估,居于树顶端的特征相对而言对于最终样本的划分贡献最大(经过该特征划分所涉及的样本比重最大),这样可以通过对比各个特征所划分的样本比重的一个期望值来评估特征的相对重要性,而在随机森林中,通过对于不同树的特征的期望取一个平均可以减小评估结果的方差,以供特征选择;在sklearn中这些评估最后被保存在训练好的模型的参数featureimportances里,是各个特征的重要性值经过归一化的结果,越高代表特征越匹配预测函数
Notes:
- 此外sklearn还有一种RandomTreesEmbedding的实现,不是很清楚有何特殊用途
随机森林与KNN
- 相似之处:均属于所谓的权重近邻策略(weighted neighborhoods schemes):指的是,模型通过训练集来通过输入样本的近邻样本点对输入样本作出预测,通过一个带权重的函数关系
boosting
sklearn-AdaBoost
- AdaBoost可用于分类和回归
- AdaBoostClassifier
- AdaBoostRegressor
- 参数
- n_estimators:基学习器数目
- learning_rate:学习率,对应在最终的继承模型中各个基学习器的权重
- base_estimator:基学习器默认是使用决策树桩
_Notes:调参的关键参数是基学习器的数量n_estimators以及基学习器本身的复杂性比如深度max_depth或者叶节点所需的最少样本数min_samples_leaf_
sklearn-GBRT
概述
Gradient Tree Boosting或者说GBRT是boosting的一种推广,是的可以应用一般的损失函数,可以处理分类问题和回归问题,应用广泛,常见应用场景比如网页搜索排序和社会生态学
优缺点
- 优点:
- 能够直接处理混合类型的特征
- 对输出空间的异常值的鲁棒性(通过鲁棒的损失函数)
- 缺点:
- 难以并行,因为本身boosting的思想是一个接一个的训练基学习器
学习器
-
GradientBoostingClassifier
- 支持二分类和多分类
- 参数控制:
- 基学习器的数量
n_estimators - 每棵树的大小可以通过树深
max_depth或者叶节点数目max_leaf_nodes来控制(注意两种树的生长方式不同,max_leaf_nodes是针对叶节点优先挑选不纯度下降最多的叶节点,这里有点LightGBM的’leaf-wise’的意味,而按树深分裂则更类似于原始的以及XGBoost的分裂方式) - 学习率
learning_rate对应取值范围在(0,1]之间的超参数对应GBRT里的shrinkage来避免过拟合(是sklearn里的GBDT用来进行正则化的一种策略); - 对于需要多分类的问题需要设置参数
n_classes对应每轮迭代的回归树,这样总体树的数目是n_classes*n_estimators criterion用来设置回归树的切分策略friedman_mse,对应的最小平方误差的近似,加入了Friedman的一些改进mse对应最小平方误差mae对应平均绝对值误差
subsample:行采样,对样本采样,即训练每个基学习器时不再使用原始的全部数据集,而是使用一部分,并且使用随机梯度上升法来做集成模型的训练- 列采样:
max_features在训练基学习器时使用一个特征子集来训练,类似随机森林的做法 - early stopping:通过参数
min_impurity_split(原始)以及min_impurity_decrease来实现,前者的是根据节点的不纯度是否高于阈值,若不是则停止增长树,作为叶节点;后者则根据分裂不纯度下降值是否超过某一阈值来决定是否分裂(此外这里的early stopping似乎与XGBoost里显示设置的early stopping不同,这里是控制树的切分生长,而XGBoost则是控制基学习器的数目)
另外一点,有说这里的early_stopping起到了一种正则化的效果,因为控制了叶节点的切分阈值从而控制了模型的复杂度(可参考李航《统计学习方法》P213底部提升方法没有显式的正则化项,通常通过早停止的方法达到正则化的效果) - 基学习器的初始化:
init,用来计算初始基学习器的预测,需要具备fit和predict方法,若未设置则默认为loss.init_estimator - 模型的重复使用(热启动):
warm_start,若设置为True则可以使用已经训练好的学习器,并且在其上添加更多的基学习器 - 预排序:
presort,默认设置为自动,对样本按特征值进行预排序从而提高寻找最优切分点的效率,自动模式下对稠密数据会使用预排序,而对稀疏数据则不会 - 损失函数(
loss)- 二分类的对数损失函数(Binomial deviance,’deviance’),提供概率估计,模型初值设为对数几率
- 多分类的对数损失(Multinomial deviance,’deviance’),针对
n_classes互斥的多分类,提供概率估计,初始模型值设为各类别的先验概率,每一轮迭代需要构建n类回归树可能会使得模型对于多类别的大数据集不太高效 - 指数损失函数(Exponential loss),与AdaBoostClassifier的损失函数一致,相对对数损失来说对错误标签的样本不够鲁棒,只能够被用来作二分类
- 基学习器的数量
- 常用方法
- 特征重要性(
feature_importances_):进行特征重要性的评估 - 包外估计(
oob_improvement_),使用包外样本来计算每一轮训练后模型的表现提升 - 训练误差(
train_score_) - 训练好的基学习器集合(
estimators_) fit方法里可以设置样本权重sample_weight,monitor可以用来回调一些方法比如包外估计、早停止等
- 特征重要性(
-
GradientBoostingRegressor
- 支持不同的损失函数,通过参数loss设置,默认的损失函数是最小均方误差
ls - 通过属性
train_score_可获得每轮训练的训练误差,通过方法staged_predict可以获得每一阶段的测试误差,通过属性feature_importances_可以输出模型判断的特征相对重要性 - 损失函数:
- 最小均方误差(Least squares,’ls’),计算方便,一般初始模型为目标均值
- 最小绝对值误差(Least absolute deviation,’lad’),初始模型为目标中位值
- Huber,一种结合了最小均方误差和最小绝对值误差的方法,使用参数alpha来控制对异常点的敏感情况
- 支持不同的损失函数,通过参数loss设置,默认的损失函数是最小均方误差
正则化
- Shrinkage,对应参数
learning rate一种简单的正则化的策略,通过控制每一个基学习器的贡献,会影响到基学习器的数目即n_estimators,经验性的设置为一个较小的值,比如不超过0.1的常数值,然后使用early stopping来控制基学习器的数目 - 行采样,使用随机梯度上升,将gradient boosting与bagging相结合,每一次迭代通过采样的样本子集来训练基学习器(对应参数
subsample),一般设置shrinkage比不设置要好,而加上行采样会进一步提升效果,而仅使用行采样可能效果反而不佳;而且进行行采样后可使用包外估计来计算模型每一轮训练的效果提升,保存在属性oob_improvement_里,可以用来做模型选择,但是包外预估的结果通常比较悲观,所以除非交叉验证太过耗时,否则建议结合交叉验证一起进行模型选择 - 列采样,类似随机森林的做法,通过设置参数
max_features来实现
可解释性
单一的决策树可以通过将树结构可视化来分析和解释,而梯度上升模型因为由上百课回归树组成因此他们很难像单独的决策树一样被可视化,不过也有一些技术来辅助解释模型
- 特征重要性(featureimportances属性),决策树在选择最佳分割点时间接地进行了特征的选择,而这一信息可以用来评估每一个特征的重要性,基本思想是一个特征越经常地被用来作为树的切分特征(更加说明使用的是CART树或其变体,因为ID3,C4.5都是特征用过一次后就不再用了),那么这个特征就越重要,而对于基于树的集成模型而言可以通过对各个树判断的特征重要性做一个平均来表示特征的重要性
- PDP(Partial dependence plots),可以用来绘制目标响应与目标特征集的依赖关系(控制其他的特征的值),受限于人类的感知,目标特征集合一般设置为1或2才能绘制对应的图形(plot_partial_dependence),也可以通过函数partial_dependence来输出原始的值
Notes:
- GradientBoostingClassifier和GradientBoostingRegressor均支持对训练好的学习器的复用,通过设置warm_start=True可以在已经训练好的模型上添加更多的基学习器
VotingClassifier
Voting的基本思想是将不同学习器的结果进行硬投票(多数表决)或者软投票(对预测概率加权平均)来对样本类别做出预估,其目的是用来平衡一些表现相当且都还不错的学习器的表现,以消除它们各自的缺陷
- 硬投票(
voting=’hard’):按照多数表决原则,根据分类结果中多数预测结果作为输入样本的预测类别,如果出现类别数目相同的情况,会按照预测类别的升序排序取前一个预测类别(比如模型一预测为类别‘2’,模型二预测为类别‘1’则样本会被判为类别1) - 软投票:对不同基学习器的预测概率进行加权平均(因此使用软投票的基学习器需要能够预测概率),需设置参数
wights为一个列表表示各个基学习器的权重值
XGBoost
过拟合
XGBoost里可以使用两种方式防止过拟合
- 直接控制模型复杂度
max_depth,基学习器的深度,增加该值会使基学习器变得更加复杂,荣易过拟合,设为0表示不设限制,对于depth-wise的基学习器学习方法需要控制深度min_child_weight,子节点所需的样本权重和(hessian)的最小阈值,若是基学习器切分后得到的叶节点中样本权重和低于该阈值则不会进一步切分,在线性模型中该值就对应每个节点的最小样本数,该值越大模型的学习约保守,同样用于防止模型过拟合gamma,叶节点进一步切分的最小损失下降的阈值(超过该值才进一步切分),越大则模型学习越保守,用来控制基学习器的复杂度(有点LightGBM里的leaf-wise切分的意味)
- 给模型训练增加随机性使其对噪声数据更加鲁棒
- 行采样:
subsample - 列采样:
colsample_bytree - 步长:
eta即shrinkage
- 行采样:
数据类别分布不均
对于XGBoost来说同样是两种方式
- 若只关注预测的排序表现(auc)
- 调整正负样本的权重,使用
scale_pos_weight - 使用auc作为评价指标
- 调整正负样本的权重,使用
- 若关注预测出正确的概率值,这种情况下不能调整数据集的权重,可以通过设置参数
max_delta_step为一个有限值比如1来加速模型训练的收敛
调参
一般参数
主要用于设置基学习器的类型
- 设置基学习器
booster- 基于树的模型
- gbtree
- dart
- 线性模型
- gblinear
- 基于树的模型
- 线程数
nthread,设置并行的线程数,默认是最大线程数
基学习器参数
在基学习器确定后,根据基学习器来设置的一些个性化的参数
eta,步长、学习率,每一轮boosting训练后可以得到新特征的权重,可以通过eta来适量缩小权重,使模型的学习过程更加保守一点,以防止过拟合gamma,叶节点进一步切分的最小损失下降的阈值(超过该值才进一步切分),越大则模型学习越保守,用来控制基学习器的复杂度(有点LightGBM里的leaf-wise切分的意味)max_depth,基学习器的深度,增加该值会使基学习器变得更加复杂,荣易过拟合,设为0表示不设限制,对于depth-wise的基学习器学习方法需要控制深度min_child_weight,子节点所需的样本权重和(hessian)的最小阈值,若是基学习器切分后得到的叶节点中样本权重和低于该阈值则不会进一步切分,在线性模型中该值就对应每个节点的最小样本数,该值越大模型的学习约保守,同样用于防止模型过拟合max_delta_step,树的权重的最大估计值,设为0则表示不设限,设为整数会是模型学习相对保守,一般该参数不必设置,但是对于基学习器是LR时,在针对样本分布极为不均的情况控制其值在1~10之间可以控制模型的更新- 行采样:
subsample,基学习器使用样本的比重 - 列采样:
colsample_bytree,用于每棵树划分的特征比重colsample_bylevel,用于每层划分的特征比重
- 显式正则化,增加该值是模型学习更为保守
- L1:
alpha - L2:
lambda
- L1:
tree_method,树的构建方法,准确的说应该是切分点的选择算法,包括原始的贪心、近似贪心、直方图算法(可见LightGBM这里并不是一个区别)auto,启发式地选择分割方法,近似贪心或者贪心exact,原始的贪心算法,既针对每一个特征值切分一次approx,近似的贪心算法选取某些分位点进行切分,使用sketching和histogramhist,直方图优化的贪心算法,对应的参数有grow_policy,max_bingpu_exactgpu_hist
scale_pos_weight,针对数据集类别分布不均,典型的值可设置为sum(negativecases)sum(positivecases)sum(negativecases)sum(positivecases)
grow_policy,控制树的生长方式,目前只有当树的构建方法tree_method设置为hist时才可以使用所谓的leaf-wise生长方式depthwise,按照离根节点最近的节点进行分裂lossguide,优先分裂损失变化大的节点,对应的一个参数还有max_leaves,表示可增加的最大的节点数
max_bin,同样针对直方图算法tree_method设置为hist时用来控制将连续特征离散化为多个直方图的直方图数目predictor,选择使用GPU或者CPUcpu_predictorgpu_predictor
任务参数
根据任务、目的设置的参数,比如回归任务与排序任务的目的是不同的
- objective,训练目标,分类还是回归
reg:linear,线性回归reg:logistic,逻辑回归binary:logistic,使用LR二分类,输出概率binary:logitraw,使用LR二分类,但在进行logistic转换之前直接输出分类得分count:poisson,泊松回归multi:softmax,使用softmax进行多分类,需要设置类别数num_classmulti:softprobrank:pairwise,进行排序任务,最小化pairwise损失reg:gamma,gamma回归reg:tweedie,tweedie回归
- 评价指标
eval_metric,默认根据目标函数设置,针对验证集,默认情况下,最小均方误差用于回归,错分用于分类,平均精确率用于排序等,可以同时使用多个评估指标,在python里使用列表来放置- 均方误差
rmse - 平均绝对值误差
mae - 对数损失
logloss,负的对数似然 - 错误率
error,根据0.5作为阈值判断的错分率 - 自定义阈值错分率
error@t - 多分类错分率
merror - 多分类对数损失
mlogloss auc主要用来排序ndcg,normalized discounted cumulative gain及其他的一些针对泊松回归等问题的评价指标
- 均方误差
命令行参数
num_round迭代次数,也对应基学习器数目task当前对模型的任务,包括- 训练
train - 预测
pred - 评估/验证
eval - 导出模型
dump
- 训练
- 导入导出模型的路径
model_in和model_out fmap,feature map用来导出模型
LightGBM
特点
效率和内存上的提升
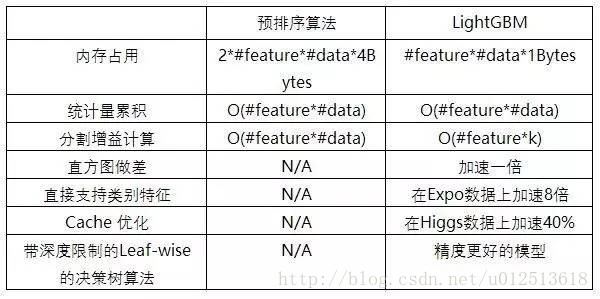
直方图算法,LightGBM提供一种数据类型的封装相对Numpy,Pandas,Array等数据对象而言节省了内存的使用,原因在于他只需要保存离散的直方图,LightGBM里默认的训练决策树时使用直方图算法,XGBoost里现在也提供了这一选项,不过默认的方法是对特征预排序,直方图算法是一种牺牲了一定的切分准确性而换取训练速度以及节省内存空间消耗的算法
- 在训练决策树计算切分点的增益时,预排序需要对每个样本的切分位置计算,所以时间复杂度是O(#data)而LightGBM则是计算将样本离散化为直方图后的直方图切割位置的增益即可,时间复杂度为O(#bins),时间效率上大大提高了(初始构造直方图是需要一次O(#data)的时间复杂度,不过这里只涉及到加和操作)
- 直方图做差进一步提高效率,计算某一节点的叶节点的直方图可以通过将该节点的直方图与另一子节点的直方图做差得到,所以每次分裂只需计算分裂后样本数较少的子节点的直方图然后通过做差的方式获得另一个子节点的直方图,进一步提高效率
- 节省内存
- 将连续数据离散化为直方图的形式,对于数据量较小的情形可以使用小型的数据类型来保存训练数据
- 不必像预排序一样保留额外的对特征值进行预排序的信息
- 减少了并行训练的通信代价
稀疏特征优化
对稀疏特征构建直方图时的时间复杂度为O(2*#非零数据)
准确率上的优化
LEAF-WISE(BEST-FIRST)树生长策略
相对于level-wise的生长策略而言,这种策略每次都是选取当前损失下降最多的叶节点进行分割使得整体模型的损失下降得更多,但是容易过拟合(特别当数据量较小的时候),可以通过设置参数max_depth来控制树身防止出现过拟合
Notes:XGBoost现在两种方式都是支持的
直接支持类别特征
对于类别类型特征我们原始的做法是进行独热编码,但是这种做法对于基于树的模型而言不是很好,对于基数较大的类别特征,可能会生成非常不平衡的树并且需要一颗很深的树才能达到较好的准确率;比较好的做法是将类别特征划分为两个子集,直接划分方法众多(2^(k-1)-1),对于回归树而言有一种较高效的方法只需要O(klogk)的时间复杂度,基本思想是对类别按照与目标标签的相关性进行重排序,具体一点是对于保存了类别特征的直方图根据其累计值(sum_gradient/sum_hessian)重排序,在排序好的直方图上选取最佳切分位置
网络通信优化
使用collective communication算法替代了point-to-point communication算法提升了效率
并行学习优化
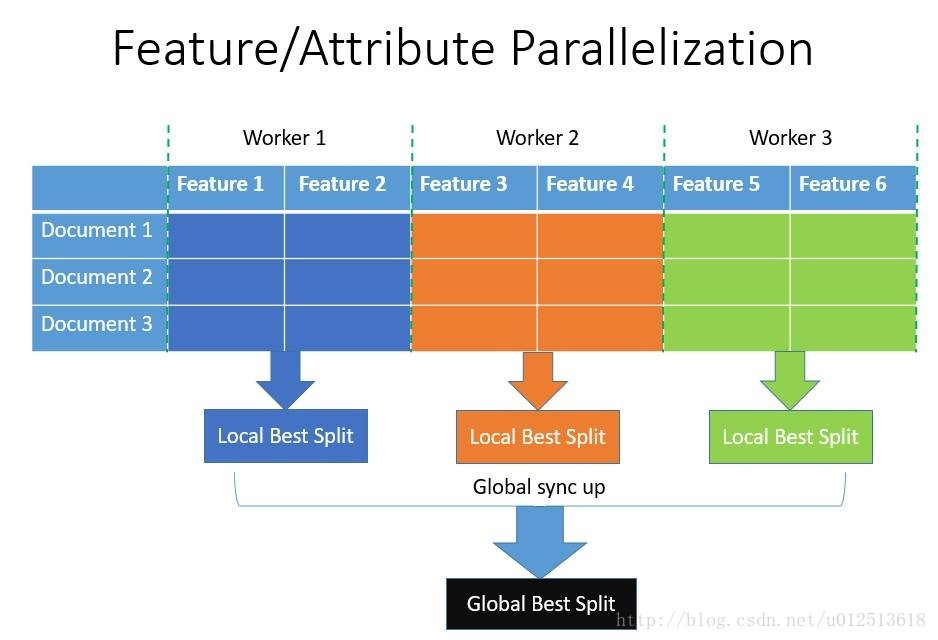
特征并行
特征并行是为了将寻找决策树的最佳切分点这一过程并行化
- 传统做法
- 对数据列采样,即不同的机器上保留不同的特征子集
- 各个机器上的worker根据所分配的特征子集寻找到局部的最优切分点(特征、阈值)
- 互相通信来从局部最佳切分点里得到最佳切分点
- 拥有最佳切分点的worker执行切分操作,然后将切分结果传送给其他的worker
- 其他的worker根据接收到的数据来切分数据
- 传统做法的缺点
- 计算量太大,并没有提升切分的效率,时间复杂度为O(#data)(因为每个worker持有所有行,需要处理全部的记录),当数据量较大时特征并行并不能提升速度
- 切分结果的通信代价,大约为O(#data/8)(若一个数据样本为1bit)
- LightGBM的做法
让每个机器保留整个完整的数据集(并不是经过列采样的数据),这样就不必在切分后传输切分结果数据,因为每个机器已经持有完整的数据集- 各个机器上的worker根据所分配的特征子集寻找到局部的最优切分点(特征、阈值)
- 互相通信来从局部最佳切分点里得到最佳切分点
- 执行最优切分操作
Notes:典型的空间换时间,差别就是减少了传输切分结果的步骤,节省了这里的通信消耗
数据并行
上述特征并行的方法并没有根本解决寻找切分点的计算效率问题,当记录数过大时需要考虑数据并行的方法
- 传统做法
- 行采样,对数据进行横向切分
- worker使用分配到的局部数据构建局部的直方图
- 合并局部直方图得到全局的直方图
- 对全局直方图寻找最优切分点,然后进行切分
- 缺点:通信代价过高,若使用point-to-point的通信算法,每个机器的通信代价时间复杂度为O(#machine*#feature*#bin),若使用collective通信算法则通信代价为O(2*#feature*#bin)
- LightGBM的做法(依然是降低通信代价)
- 不同于合并所有的局部直方图获得全局的直方图,LightGBM通过Reduce Scatter方法来合并不同worker的无交叉的不同特征的直方图,这样找到该直方图的局部最优切分点,最后同步到全局最优切分点
- 基于直方图做差的方法,在通信的过程中可以只传输某一叶节点的直方图,而对于其邻居可通过做差的方式得到
- 通信的时间复杂度为O(0.5*#feature*#bin)
并行投票
进一步减小了数据并行中的通信代价,通过两轮的投票来减小特征直方图中的通信消耗
其他特点
直接支持类别(标称)特征
LightGBM可以直接用类别特征进行训练,不必预先进行独热编码,速度会提升不少,参数设置categorical_feature来指定数据中的类别特征列
早停止
sklearn-GBDT,XGBoost,LightGBM都支持早停止,不过在细节上略有不同
- sklearn-GBDT中的early stopping是用来控制基学习器的生长的:通过参数
min_impurity_split(原始)以及min_impurity_decrease来实现,前者的是根据节点的不纯度是否高于阈值,若不是则停止增长树,作为叶节点;后者则根据分裂不纯度下降值是否超过某一阈值来决定是否分裂(此外这里的early stopping似乎与XGBoost里显示设置的early stopping不同,这里是控制树的切分生长,而XGBoost则是控制基学习器的数目) - XGBoost和LightGBM里的early_stopping则都是用来控制基学习器的数目的
- 两者都可以使用多组评价指标,但是不同之处在于XGBoost会根据指标列表中的最后一项指标控制模型的早停止,而LightGBM则会受到所有的评估指标的影响
- 在使用early stopping控制迭代次数后,模型直接返回的是最后一轮迭代的学习器不一定是最佳学习器,而在做出预测时可以设置参数选择某一轮的学习器作出预测
- XGBoost里保存了三种状态的学习器,分别是
bst.best_score, bst.best_iteration, bst.best_ntree_limit,官方的建议是在做预测时设置为bst.best_ntree_limit,实际使用时感觉bst.best_iteration和bst.best_ntree_limit的表现上区别不大 - LightGBM则仅提供了
bst.best_iteration这一种方式
- XGBoost里保存了三种状态的学习器,分别是
实践上
- 内置cv
- 支持带权重的数据输入
- 可以保留模型
- DART
- L1/L2回归
- 保存模型进行进一步训练
- 多组验证集
支持的任务
- 回归任务
- 分类(二分类、多分类)
- 排序
支持的评价指标METRIC
- 绝对值误差
l1 - 平方误差
l2 - 均方误差
l2_root - 对数损失
binary_logloss,multi_logloss - 分类误差率
binary_error,multi_error - auc
- ndcg
- 多分类对数损失
- 多分类分类误差率
调参
核心参数
- 叶节点数
num_leaves,与模型复杂度直接相关(leaf-wise) - 任务目标
- 回归
regression,对应的损失函数如下regression_l1,加了l1正则的回归,等同于绝对值误差regression_l2,等同于均方误差huber,Huber Lossfair,Fair Losspoisson,泊松回归
- 分类
binary,二分类multiclass,多分类
- 排序
lambdarank
- 回归
- 模型
boostinggbdt,传统的梯度提升决策树rf,随机森林dart,Dropouts meet Multiple Additive Regression Treesgoss,Gradient-based One-Side Sampling
- 迭代次数
num_iterations,对于多分类问题,LightGBM会构建num_class*num_iterations的树 - 学习率/步长
learning_rate,即shrinkage - 树的训练方式
tree_learner,主要用来控制树是否并行化训练serial,单机的树学习器feature,特征并行的树学习器data,数据并行的树学习器
- 线程数
num_threads - 设备
device,使用cpu还是gpucpugpu
训练控制参数
防止过拟合
- 树的最大深度
max_depth,主要用来避免模型的过拟合,设为负数值则表明不限制 - 叶节点的最少样本数
min_data_in_leaf - 叶节点的最小海森值之和
min_sum_hessian_in_leaf - 列采样
feature_fraction,每棵树的特征子集占比,设置在0~1之间,可以加快训练速度,避免过拟合 - 行采样
bagging_fraction,不进行重采样的随机选取部分样本数据,此外需要设置参数bagging_freq来作为采样的频率,即多少轮迭代做一次bagging; - 早停止
early_stopping_roung,在某一验证数据的某一验证指标当前最后一轮迭代没有提升时停止迭代 - 正则化
lambda_l1lambda_l2
- 切分的最小收益
min_gain_to_split
IO参数
直方图相关
- 最大直方图数
max_bin,特征值装载的最大直方图数目,一般较小的直方图数目会降低训练的准确性但会提升整体的表现,处理过拟合 - 直方图中最少样本数
min_data_in_bin,设置每个直方图中样本数的最小值,同样防止过拟合
特征相关
- 是否预排序
is_pre_partition - 是否稀疏
is_sparse - 类别特征列
categorical_feature,声明类别特征对应的列(通过索引标记),仅支持int类型 - 声明权重列
weight,指定一列作为权重列
内存相关
- 分阶段加载数据
two_round,一般LightGBM将数据载入内存进行处理,这样会提升数据的加载速度,但是对于数据量较大时会造成内存溢出,所以此时需要分阶段载入 - 保存数据为二进制
save_binary,将数据文件导出为二进制文件,下次加载数据时就会更快一些
缺失值
- 是否处理缺失值
use_missing - 是否将0值作为缺失值
zeros_as_missing
目标参数
sigmoid,sigmoid函数中的参数,用于二分类和排序任务scale_pos_weight,设置正例在二分类任务中的样本占比- 初始化为均值
boost_from_average,调整初始的分数为标签的均值,加速模型训练的收敛速度,仅用于回归任务 - 样本类别是否不平衡
is_unbalance num_class,用于多分类
调参小结
LEAF-WISE
num_leaves,对于leaf-wise的模型而言该参数是用来控制模型复杂度的主要参数,理论上可以通过设置num_leaves=2^(max_depth)来设置该参数值,实际是不可取的,因为在节点数目相同的前提下,对于leaf-wise的模型会倾向于生成深度更深的模型,如果生硬的设置为2^(max_depth)可能会造成模型的过拟合,一般设置的值小于2^(max_depth),min_data_in_leaf,在设置了叶节点数后,该值会对模型复杂度造成影响,若设的较大则树不会生长的很深,但可能造成模型的欠拟合max_depth
效率
bagging_fraction和bagging_freq,使用bagging进行行采样提升训练速度(减小了数据集)feature_fraction,列采样- 设置较少的直方图数目,
max_bin - 保存数据为二进制文件以便于未来训练时能快速加载,
save_binary - 通过并行训练来提速
准确率
- 设置较大的直方图数目
max_bin,当然这样会牺牲训练速度 - 使用较小的学习率
learning_rate,这样会增加迭代次数 - 设置较大的叶节点数
num_leaves,可能造成模型过拟合 - 使用较大的训练数据
- 尝试
dart模型
过拟合
- 设置较少的直方图数目,
max_bin - 设置较小的叶节点数
num_leaves - 设置参数
min_data_in_leaf和min_sum__hessian_in_leaf - 使用bagging进行行采样
bagging_fraction和bagging_freq feature_fraction,列采样- 使用较大的训练数据
- 正则化
lambda_l1lambda_l2- 切分的最小收益
min_gain_to_split
- 控制树深
max_depth
总结
GBDT vs. XGBoost vs. LightGBM(论文层面)
GBDT vs. XGBoost
- GBDT是机器学习算法,XGBoost是该算法的工程实现
- GBDT无显式正则化;在使用CART作为基分类器时,XGBoost显式地加入了正则项来控制模型的复杂度,有利于防止过拟合,提高模型的泛化性能。
- GBDT仅使用了目标函数一阶泰勒展开,而XGBoost使用了二阶的泰勒展开值
- 一说加快收敛速度
- 另外有说本身模型训练的学习率shrinkage可以通过二阶导数做一个逼近,而原始的GBDT没有计算这个,所以一般是通过预设的超参数eta人为指定
- GBDT采用CART作为基分类器,XGBoost支持多种类型的基分类器,比如线性分类器
- GBDT在每轮迭代中使用全部数据,XGBoost采用了与随机森林相似的策略,支持对数据进行采样
- GBDT没有设计对缺失值进行处理,XGBoost能自动学习出缺失值的处理策略
- XGBoost通过预排序的方法来实现特征并行,提高模型训练效率
- XGBoost支持分布式计算
XGBoost vs. LightGBM
- 树的切分策略不同
- XGBoost是level-wise而LightGBM是leaf-wise
- 实现并行的方式不同
- XGBoost是通过预排序的方式
- LightGBM则是通过直方图算法
- LightGBM直接支持类别特征,对类别特征不必进行独热编码处理
sklearn GBDT vs. XGBoost vs. LightGBM(实现层面)
实际在库的实现层面原始论文里的很多区别是不存在的,差异更多在一些工程上的性能优化
sklearn GBDT vs. XGBoost
- 正则化方式不同
- sklearn GBDT中仅仅通过学习率来做一个正则化(影响到基学习器的数目),此外gbdt里的early stopping也达到了一个正则化的效果,对应的主要参数是
min_impurity_split即控制了判断叶节点是否进一步切分的不纯度的阈值,若超过该阈值则可以进一步切分,否则不行,故而控制了树的深度即控制了基学习器的复杂度 - XGBoost除了学习率以外还有显示的设置正则化项l1,l2以及对应论文里的叶节点数(对应参数gamma)以及节点权重和(参数min_child_weight)来控制模型复杂度
- sklearn GBDT中仅仅通过学习率来做一个正则化(影响到基学习器的数目),此外gbdt里的early stopping也达到了一个正则化的效果,对应的主要参数是
- GBDT仅使用了目标函数一阶泰勒展开,而XGBoost使用了二阶的泰勒展开值
- XGBoost自有一套对缺失值的处理方法
- early-stopping意义不同
- sklearn GBDT中控制基学习器进一步切分、生长
- XGBoost控制基学习器的数目
- 特征重要性的判断标准
- sklearn GBDT是根据树的节点特征对应的深度来判断
- XGBoost则有三种方法(get_score)
- weight:特征用来作为切分特征的次数
- gain:使用特征进行切分的平均增益
- cover:各个树中该特征平均覆盖情况(根据样本?)
- 树的切分算法
- XGBoost存在三种切分方法,
- 原始的贪心算法(每个特征值切分)
- 近似贪心(分位点切分)(使得对于大量的特征取值尤其是连续变量时XGBoost会比sklearn-gbdt快很多)
- 直方图算法
- XGBoost存在三种切分方法,
- XGBoost支持level-wise和leaf-wise两种树的生长方式
- XGBoost支持GPU
- XGBoost支持多种评价标准、支持多种任务(回归、分类、排序)
XGBoost vs. LightGBM
XGBoost目前已经实现了LightGBM之前不同的一些方法比如直方图算法,两者的区别更多的在与LightGBM优化通信的的一些处理上
- LightGBM直接支持类别特征,可以不必预先进行独热编码,提高效率(categorical_feature)
- 优化通信代价
- 特征并行
- 数据并行
- point to point communication–>collective communication
- 使用多项评价指标同时评价时两者的早停止策略不同,XGBoost是根据评价指标列表中的最后一项来作为停止标准,而LightGBM则受到所有评价指标的影响
lightGBM与XGBoost的区别:
(1)xgboost采用的是level-wise的分裂策略,而lightGBM采用了leaf-wise的策略,区别是xgboost对每一层所有节点做无差别分裂,可能有些节点的增益非常小,对结果影响不大,但是xgboost也进行了分裂,带来了务必要的开销。 leaft-wise的做法是在当前所有叶子节点中选择分裂收益最大的节点进行分裂,如此递归进行,很明显leaf-wise这种做法容易过拟合,因为容易陷入比较高的深度中,因此需要对最大深度做限制,从而避免过拟合。
(2)lightgbm使用了基于histogram的决策树算法,这一点不同与xgboost中的 exact 算法,histogram算法在内存和计算代价上都有不小优势。
-. 内存上优势:很明显,直方图算法的内存消耗为(#data* #features * 1Bytes)(因为对特征分桶后只需保存特征离散化之后的值),而xgboost的exact算法内存消耗为:(2 * #data * #features* 4Bytes),因为xgboost既要保存原始feature的值,也要保存这个值的顺序索引,这些值需要32位的浮点数来保存。
-. 计算上的优势,预排序算法在选择好分裂特征计算分裂收益时需要遍历所有样本的特征值,时间为(#data),而直方图算法只需要遍历桶就行了,时间为(#bin)
(3)直方图做差加速
-. 一个子节点的直方图可以通过父节点的直方图减去兄弟节点的直方图得到,从而加速计算。
(4)lightgbm支持直接输入categorical 的feature
-. 在对离散特征分裂时,每个取值都当作一个桶,分裂时的增益算的是”是否属于某个category“的gain。类似于one-hot编码。
(5)但实际上xgboost的近似直方图算法也类似于lightgbm这里的直方图算法,为什么xgboost的近似算法比lightgbm还是慢很多呢?
-. xgboost在每一层都动态构建直方图, 因为xgboost的直方图算法不是针对某个特定的feature,而是所有feature共享一个直方图(每个样本的权重是二阶导),所以每一层都要重新构建直方图,而lightgbm中对每个特征都有一个直方图,所以构建一次直方图就够了。
-. lightgbm做了cache优化?
(6)lightgbm哪些方面做了并行?
-. feature parallel
一般的feature parallel就是对数据做垂直分割(partiion data vertically,就是对属性分割),然后将分割后的数据分散到各个workder上,各个workers计算其拥有的数据的best splits point, 之后再汇总得到全局最优分割点。但是lightgbm说这种方法通讯开销比较大,lightgbm的做法是每个worker都拥有所有数据,再分割?(没懂,既然每个worker都有所有数据了,再汇总有什么意义?这个并行体现在哪里??)
-. data parallel
传统的data parallel是将对数据集进行划分,也叫 平行分割(partion data horizontally), 分散到各个workers上之后,workers对得到的数据做直方图,汇总各个workers的直方图得到全局的直方图。 lightgbm也claim这个操作的通讯开销较大,lightgbm的做法是使用”Reduce Scatter“机制,不汇总所有直方图,只汇总不同worker的不同feature的直方图(原理?),在这个汇总的直方图上做split,最后同步。
XGBoost
XGBoost(eXtreme Gradient Boosting)全名叫极端梯度提升
目录
1. 最优模型的构建方法
2. Boosting的回归思想
3. XGBoost的目标函数推导
4. XGBoost的回归树构建方法
5. XGBoost与GDBT的区别
最优模型的构建方法
构建最优模型的一般方法是最小化训练数据的损失函数,我们用字母 L表示,如下式:
式(1)称为经验风险最小化,训练得到的模型复杂度较高。当训练数据较小时,模型很容易出现过拟合问题。
因此,为了降低模型的复杂度,常采用下式:
其中J(f)为模型的复杂度,式(2)称为结构风险最小化,结构风险最小化的模型往往对训练数据以及未知的测试数据都有较好的预测 。
应用:决策树的生成和剪枝分别对应了经验风险最小化和结构风险最小化,XGBoost的决策树生成是结构风险最小化的结果
Boosting方法的回归思想
Boosting法是结合多个弱学习器给出最终的学习结果,不管任务是分类或回归,我们都用回归任务的思想来构建最优Boosting模型 。
回归思想:把每个弱学习器的输出结果当成连续值,这样做的目的是可以对每个弱学习器的结果进行累加处理,且能更好的利用损失函数来优化模型。
假设是第 t 轮弱学习器的输出结果,
是模型的输出结果,
是实际输出结果,表达式如下:
上面两式就是加法模型,都默认弱学习器的输出结果是连续值。因为回归任务的弱学习器本身是连续值,所以不做讨论,下面详细介绍分类任务的回归思想。
分类任务的回归思想:
根据2.1式的结果,得到最终的分类器:
分类的损失函数一般选择指数函数或对数函数,这里假设损失函数为对数函数,学习器的损失函数是
若实际输出结果yi=1,则:
求(2.5)式对的梯度,得:
负梯度方向是损失函数下降最快的方向,(2.6)式取反的值大于0,因此弱学习器是往增大的方向迭代的,图形表示为:
如上图,当样本的实际标记 yi 是 1 时,模型输出结果随着迭代次数的增加而增加(红线箭头),模型的损失函数相应的减小;当样本的实际标记 yi 是 -1时,模型输出结果
随着迭代次数的增加而减小(红线箭头),模型的损失函数相应的减小 。这就是加法模型的原理所在,通过多次的迭代达到减小损失函数的目的。
小结:Boosting方法把每个弱学习器的输出看成是连续值,使得损失函数是个连续值,因此可以通过弱学习器的迭代达到优化模型的目的,这也是集成学习法加法模型的原理所在 。
XGBoost算法的目标函数推导
目标函数,即损失函数,通过最小化损失函数来构建最优模型,由第一节可知, 损失函数应加上表示模型复杂度的正则项,且XGBoost对应的模型包含了多个CART树,因此,模型的目标函数为:
(3.1)式是正则化的损失函数,等式右边第一部分是模型的训练误差,第二部分是正则化项,这里的正则化项是K棵树的正则化项相加而来的。
CART树的介绍:
上图为第K棵CART树,确定一棵CART树需要确定两部分,第一部分就是树的结构,这个结构将输入样本映射到一个确定的叶子节点上,记为![]() 。第二部分就是各个叶子节点的值,q(x)表示输出的叶子节点序号,
。第二部分就是各个叶子节点的值,q(x)表示输出的叶子节点序号,![]() 表示对应叶子节点序号的值。由定义得:
表示对应叶子节点序号的值。由定义得:![]()
树的复杂度定义
XGBoost法对应的模型包含了多棵cart树,定义每棵树的复杂度:
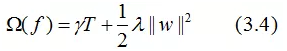
其中T为叶子节点的个数,||w||为叶子节点向量的模 。γ表示节点切分的难度,λ表示L2正则化系数。
如下例树的复杂度表示:
目标函数推导
根据(3.1)式,共进行t次迭代的学习模型的目标函数为:
泰勒公式的二阶导近似表示:
令为Δx,则(3.5)式的二阶近似展开:
其中:
表示前t-1棵树组成的学习模型的预测误差,gi和hi分别表示预测误差对当前模型的一阶导和二阶导 ,当前模型往预测误差减小的方向进行迭代。
忽略(3.8)式常数项,并结合(3.4)式,得:
通过(3.2)式简化(3.9)式:
(3.10)式第一部分是对所有训练样本集进行累加,因为所有样本都是映射为树的叶子节点,我们换种思维,从叶子节点出发,对所有的叶子节点进行累加,得:
令
Gj 表示映射为叶子节点 j 的所有输入样本的一阶导之和,同理,Hj表示二阶导之和。
得:
对于第 t 棵CART树的某一个确定结构(可用q(x)表示),其叶子节点是相互独立的,Gj和Hj是确定量,因此,(3.12)可以看成是关于叶子节点的一元二次函数 。最小化(3.12)式,得:
得到最终的目标函数:
(3.14)也称为打分函数(scoring function),它是衡量树结构好坏的标准,值越小,代表这样的结构越好 。我们用打分函数选择最佳切分点,从而构建CART树。
CART回归树的构建方法
上节推导得到的打分函数是衡量树结构好坏的标准,因此,可用打分函数来选择最佳切分点。首先确定样本特征的所有切分点,对每一个确定的切分点进行切分,切分好坏的标准如下:
Gain表示单节点obj*与切分后的两个节点的树obj*之差,遍历所有特征的切分点,找到最大Gain的切分点即是最佳分裂点,根据这种方法继续切分节点,得到CART树。若 γ 值设置的过大,则Gain为负,表示不切分该节点,因为切分后的树结构变差了。γ值越大,表示对切分后obj下降幅度要求越严,这个值可以在XGBoost中设定。
XGBoost与GDBT的区别
1. XGBoost生成CART树考虑了树的复杂度,GDBT未考虑,GDBT在树的剪枝步骤中考虑了树的复杂度。
2. XGBoost是拟合上一轮损失函数的二阶导展开,GDBT是拟合上一轮损失函数的一阶导展开,因此,XGBoost的准确性更高,且满足相同的训练效果,需要的迭代次数更少。
3. XGBoost与GDBT都是逐次迭代来提高模型性能,但是XGBoost在选取最佳切分点时可以开启多线程进行,大大提高了运行速度。
XGBoost之切分点算法
上文介绍了XGBoost的算法原理并引出了衡量树结构好坏的打分函数(目标函数),根据特征切分点前后的打分函数选择最佳切分点,但并未对节点的切分算法作详细的介绍。本文详细的介绍了XGBoost的切分点算法
目录
-
并行原理
-
切分点算法之贪婪算法
-
切分点算法之分位点算法
-
切分点算法之权重分位点算法
-
稀疏数据的切分算法
-
总结
1. 并行原理
XGBoost是串行生成CART树,但是XGBoost在处理特征时可以做到并行处理,XGBoost并行原理体现在最优切分点的选择,假设样本数据共M个特征,对于某一轮CART树的构建过程中,选择最佳切分点算法如下图:
1. 红色框表示根据每个特征大小对训练数据进行排序,保存为block结构,block个数与特征数量相等。
2. 绿色宽表示对每个block结构选择最佳特征切分点 ,节点切分标准是目标函数下降的程。
3. 黑色框表示比较每个block结构的最佳特征切分点的目标函数下降的增益,选择最佳切分点。
2. 切分点算法之贪婪算法
每一个block结构的切分点算法思路是相同的,因此,我重点介绍某一块block结构的切分点算法。
XGBoost分位点算法:根据特征对样本数据进行排序,然后特征从小到大进行切分,比较每次切分后的目标函数大小,选择下降最大的节点作为该特征的最优切分点。最后比较不同block块结构最优切分点的目标函数下降值,选择下降最大的特征作为最优切分点。
流程图如下:
【例】下表表示样本的某一列特征数值
根据特征大小对样本重新排序:
贪婪算法切分节点:
红箭头表示每一次的切分节点,选择目标函数下降最大的点作为切分节点。
3. 切分点算法之分位点算法
若特征是连续值,按照上述的贪婪算法,运算量极大 。当样本量足够大的时候,使用特征分位点来切分特征。流程图如下:

【例】下表表示样本的某一列特征数值,用三分位作为切分节点 。

根据特征大小进行样本排序:

用特征的三分位点作切分节点:
红箭头表示每一次的切分节点,选择目标函数下降最大的点作为切分节点。
4. 切分点算法之权重分位点算法
上节假设样本权重相等,根据样本的分位点来均分损失函数存在偏差,本节用样本权重来均分损失函数。
损失函数如下:
对其变形得到:
xi损失函数可以看做是以以−gi/hi作为label的均方误差,乘以大小hi的权重,换句话说,xi对loss的贡献权重为hi ,构建样本权重的分位点等于误差的均分。
上节假设样本权重相等,特征值的分位点作为切分点,本节假设样本权重是hi,构建样本权重的均分点步骤:
(1)根据特征大小对样本进行排序
(2)定义排序函数:
其中x,z表示特征
(3)设置排序函数的分位点为切分点
【例】如下图
特征与对应的排序函数值的关系,如下表:
红色箭头表示以三分位点作为切分点。
最后,选择最优切分点。
5. 稀疏数据的切分算法
稀疏数据在实际项目是非常常见,造成稀疏数据的原因主要有:1. 数据缺失;2. 统计上的 0;3. one-hot编码的特征表示。
稀疏数据的切分点算法:
当出现特征值缺失时,包含缺失特征值的样本被映射到默认的方向分支,然后计算该节点的最优切分点,最优切分点对应的默认切分方向就是特征值缺失时默认的方向。
XGBoost参数调优小结
目录
-
XGBoost算法原理简单回顾
-
XGBoost的优点
-
XGBoost的参数解释
-
参数调优实例
-
小结
1. XGBoost算法原理简单回顾
XGBoost算法的每颗树都是对前一个模型损失函数的二阶导展开式拟合,然后结合多棵树给出分类或回归结果。因此我们只要知道每棵树的构建过程,就能很好的理解XGBoost的算法原理。
假设对于前t-1棵树的预测结果为,真实结果为y,用L表示损失函数,那么当前模型的损失函数为:
XGBoost法构建树的同时考虑了正则化,定义每棵树的复杂度为:
因此,包含正则化项的损失函数为:
最小化(1.3)式得到最终的目标函数:
目标函数也称为打分函数,它是衡量树结构好坏的标准,值越小代表树的结构越好。因此树的节点切分规则是选择树目标函数值下降最大的点作为切分点 。
如下图,对于某一节点切分前后的目标函数之差记为Gain。
选择Gain下降最大的切分点对树分裂,以此类推,得到完整的树 。
因此,只要知道(1.5)式的参数值就能基本确定树模型,其中表示左子节点损失函数的二阶导之和,
表示右子节点损失函数的二阶导之和,
表示左子节点损失函数的一阶导之和,
表示右子节点损失函数的一阶导之和 。
表示正则化系数,
表示切分节点难度,
和
定义了树的复杂度。再简单一点,我们只要设置了损失函数L,正则化系数
和切分节点难度
,就基本确定了树模型 。XGBoost参数择要重点考虑这三个参数 。
2. XGBoost的优点
1. 正则化
XGBoost切分节点时考虑了正则化项(如图1.3),减少了过拟合。实际上,XGBoost也称为“正则化提升”技术。
2. 并行处理
虽然XGBoost是串行迭代生成各决策树,但是我们在切分节点时可以做到并行处理 ,因此XGBoost支持Hadoop实现 。
3. 高度灵活性
XGBoost支持自定义目标函数和评价函数,评价函数是衡量模型好坏的标准,目标函数是损失函数,如上节讨论,只要知道了损失函数,然后求其一阶导和二阶导,就能确定节点的切分规则。
4. 缺失值处理
XGBoost内置了处理缺失值的节点切分规则 。用户需要提供一个和其他样本不一样的值(如-999), 然后把该值作为参数的缺失值 。
5. 内置交叉验证
XGBoost允许每一轮迭代中使用交叉验证,因此,可以很方便的获得交叉验证率,得到最优boosting迭代次数 ,并不需要传统的网格搜索法来获取最优迭代次数 。
6. 在已有的模型基础上继续
XGBoost可以从上一轮的结果上继续训练,从而节省了运行时间,通过设置模型参数“process_type”= update来实现 。
3. XGBoost参数解释
XGBoost参数把所有的参数分为三类:
1. 通用参数:控制了模型的宏观功能 。
2. Booster参数:控制每一轮迭代的树生成。
3. 学习目标参数:决定了学习场景,如损失函数和评价函数 。
3.1 通用参数
-
booster [default = gbtree]
供选择的模型有gbtree和gblinear,gbtree使用基于树的模型进行提升,gblinear使用线性模型进行提升,默认是gbtree 。这里只介绍tree booster,因为它的表现远远胜过linear booster
-
silent [default = 0]
取0时表示打印运行信息,取1时表示不打印运行信息。
-
nthread
XGBoost运行时的线程数,默认是当前系统可运行的最大线程数。
-
num_pbuffer
预测数据的缓冲区大小,一般设置成训练样本个数的大小 。缓冲区保留最后一次迭代后的预测结果,系统自动设置。
-
num_feature
设置特征维数来构建树模型,系统自动设置 。
3.2 booster参数
-
eta [default = 0.3]
控制树模型的权重,与AdaBoost算法的学习率(learning rate)含义类似,缩小权重以避免模型处于过拟合,在对eta进行参数择优时,需要与迭代次数(num_boosting_rounding)结合在一起考虑 ,如减小学习率,那么增加最大迭代次数;反之,则减小最大迭代次数 。
范围:[0,1]
模型迭代公式:
其中表示前t棵树结合模型的输出结果,
表示第t棵树模型,α表示学习率,控制模型更新的权重 。
-
gamma [default = 0]
控制模型切分节点的最小损失函数值,对应(1.5)式的γ,若γ设置的过大(1.5)式小于零,则不进行节点切分,因此降低了模型的复杂度。
-
lambda [default = 1]
表示L2正则化参数,对应(1.5)式中的λ,增大λ的值使模型更保守,避免过拟合 。
-
alpha [default = 0]
表示L1正则化参数,L1正则化的意义在于可以降维,增大alpha值使模型更保守,避免过拟合
范围:[0,∞]
-
max_depth [default=6]
表示树的最大深度,增加树的深度提高了树的复杂度,很有可能会导致过拟合,0表示对树的最大深度无限制 。
范围:[0,∞]
-
min_child_weight [default=1]
表示最小叶子节点的样本权重和,和之前介绍的min_child_leaf参数有差别,min_child_weight表示样本权重的和,min_child_leaf表示样本总数和。
范围:[0,∞]
-
subsample [default=1]
表示随机采样一定比例的样本来构建每棵树,减小比例参数subsample值,算法会更加保守,避免过拟合
范围:[0,1]
-
colsample_bytree,colsample_bylevel,colsample_bynode
这个三个参数表示对特征进行随机抽样,且具有累积效应 。
colsample_bytree,表示每棵树划分的特征比重
colsample_bylevel,表示树的每层划分的特征比重
colsample_bynode,表示树的每个节点划分的特征比重 。
比如,样本共有64个特征,设置{'colsample_bytree' : 0.5 , 'colsample_bylevel' : 0.5 , 'colsample_bynode' : 0.5 },那么随机采样4个特征应用于树的每一个节点切分 。
范围:[0,1]
-
tree_method string [default = auto ]
表示树的构建方法,确切来说是切分点的选择算法,包括贪心算法,近似贪心算法,直方图算法
exact:贪心算法
aprrox:近似贪心算法,选择特征的分位点进行切分
hist:直方图切分算法,LightGBM算法也采用该切分算法 。
-
scale_pos_weight [default = 1]
当正负样本不平衡时,设置该参数为正值 ,可以使算法更快收敛 。
典型的值可设置为:(负样本个数)/(正样本个数)
-
process_type [default = default]
default:正常的构建提升树过程
update: 从已有的模型构建提升树
3.3 学习任务参数
根据任务和目的设置参数
objective,训练目标,分类还是回归
reg : linear,线性回归
reg : logistic,逻辑回归
binary : logistic,使用LR二分类,输出概率
binary : logitraw,使用LR二分类,输出Logistic转换之前的分类得分 。
eval_metric,评价验证集的指标,默认根据目标函数设置,默认情况下,最小均方差用于回归,错误率用于分类,平均精确率用于排序 。
rmse:均方差
mae:平均绝对值误差
error :错误率
logloss:负的对数损失
auc : roc曲线下的面积
seed [default=0]
随机数种子,设置它可以复现随机数据结果 。
4. 参数调优实例
原始数据集和经过特征工程处理后的数据集在开头的链接部分进行下载,算法在jupter-notebook交互界面开发 。
定义模型评价函数,并根据一定的学习率得到最优迭代次数 ,函数定义如下:
Step1:
根据经验设置默认的参数,调用modelfit函数得到最优迭代次数是198 。
Step2: 树最大深度和最小叶子节点权重调优
根据第一步得到的最优迭代次数更新模型参数n_estimators,然后调用model_selection类的GridSearchCV设置交叉验证模型,最后调用XGBClassifier类的fit函数得到最优树的最大深度和最小叶子节点权重 。
a) 设置树最大深度和最小叶子节点权重范围:
b) GridSearchCV设置交叉验证模型:
c) XGBClassfier类的fit函数更新参数:
Step3: gamma参数调优
Step4: subsample and colsample_bytree参数调优
Step5: 正则化参数调优
Step3,Step4和Step5参数调优思想Step2一致,这里不再展开,可参考代码去理解 。
Step6: 减小学习率,增大对应的最大迭代次数 。参数调优思想与Step1一致,得到最优的迭代次数 ,并输出交叉验证率结果。
迭代次数为2346时,得到最优分类结果(如下图)。
5. XGBoost参数调优小结
XGBoost是一个高性能的学习模型算法,当你不知道怎么对模型进行参数调优时,可参考上一节的步骤去进行参数调优 。本节根据上节的内容,以及自己的项目经验阐述一下本人对XGBoost算法参数调优的一些理解,若有错误之处,还忘指正 。
(1)模型初始化 。在初始化模型参数时,我们尽量让模型的复杂度较高,然后一步一步的通过参数调优来降低模型复杂度 。如上节初始化参数:叶子节点最小权重为0,最大树深度为5,最小损失函数下降值为0,这些参数初始化都是复杂化模型 。
(2) 学习率和最大迭代次数 。这两个参数的调优一定是联系在一起的,学习率越大,达到相同性能的模型所需要的最大迭代次数越小;学习率越小,达到相同性能的模型所需要的最大迭代次数越大 。XGBoost每个参数的更新都需要进行多次迭代,因此,学习率和最大迭代次数是首先需要考虑的参数 ,且学习率和最大迭代参数的重点不是提高模型的分类准确率,而是提高模型的泛化能力,因此,当模型的分类准确率很高时,我们最后一步应减小学习率的大小,以提高模型的泛化能力 。
(3) 逐步降低模型复杂度 。树的最大深度,叶子节点最小权重等参数都是影响模型复杂度的因素,这个看自己经验,第四节的调参顺序是:树的最大深度和叶子节点最小权重->最小损失函数下降值->行采样和列采样->正则化参数 。实际项目中,我一般按照这个顺序去调参 ,若有不同的理解,欢迎交流。
(4) 特征工程:若模型的准确率在很低的范围,那么我建议先不用去调参了,去重点关注特征和训练数据。特征和数据决定模型上限,模型只是逼近这个上限 。
LightGBM
提升树是利用加法模型和前向分布算法实现学习的优化过程,它有一些高效的实现,如GBDT,XGBoost和pGBRT,其中GBDT是通过损失函数的负梯度拟合残差,XGBoost则是利用损失函数的二阶导展开式拟合残差。但是,当面对大量数据集和高维特征时,其扩展性和效率很难令人满意,最主要的原因是对于每一个特征,它们需要扫描所有的样本数据来获得最优切分点,这个过程是非常耗时的 。而基于GBDT的另一种形式LightGBM基于直方图的切分点算法,其很好的解决了这些问题
目录
- 基于直方图的切分点算法
- 直方图算法改进
- 直方图做差优化
- 树的生长策略
- 支持类别特征
- 支持高效并行
- 与XGBoost的对比
1. 基于直方图的切分点算法
算法流程图如下:

流程解释:LightGBM通过直方图算法把连续的特征值离散化成对应的bin(可以理解成桶),然后累加每个bin对应特征的梯度值并计数,最后遍历所有特征和数据,寻找最优切分点 。下面详细解释这一过程 。
1) 直方图算法:
直方图通过分段函数把连续值离散化成对应的bin。
如分段函数为:

那么,对于连续值≥0的特征分成四个桶,特征的所有可能切分点个数降为4,即bin的个数 ,因此大大加快了训练速度。
直方图每个bin包含了两类信息,分别是每个bin样本中的梯度之和与每个bin中的样本数量,对应于流程图的表达式:

每个bin累加的梯度包含了 一阶梯度与二阶梯度
2)切分点算法:
LightGBM和XGBoost的切分点算法思想是一样的,比较切分后的增益与设定的最小增益的大小,若大于,则切分;反之,则不切分该节点。下面详细叙述这一过程(该节代码实现均在LightGBM/src/treelearner/feature_histogram.hpp):
(1)计算每个叶子节点的输出wj;
根据上面两图的代码,可知lightGBM的叶子节点输出与XGBoost类似,即:

其中,Gj为叶子节点包含所有样本的一阶梯度之和,Hj为二阶梯度之和 。
(2)计算节点切分后的分数
叶子节点分数为GetLeafSplitGainGivenOutput函数:
其中output代表叶子节点输出Wj 。考虑一般情况,假如叶子节点的样本一阶梯度和大于l1,那么,叶子节点分数的表达式为:
![]()
节点切分前的分数:
因此,计算节点切分增益:
节点切分增益= 节点分数 - (左叶子节点分数 + 右叶子节点分数)
比较切分增益与设置的最小增益大小,记为Gain:
Gain = 节点切分增益 — 最小切分增益
最后得到与XGBoost类似的形式,XGBoost为如下形式:

LightGBM的最小切分增益对应于XGBoost的γ 。
2.直方图算法改进
直方图算法通过分段函数把连续值离散化成对应的bin的复杂度为O(#feature×#data),若降低feature或data的大小,那么直方图算法的复杂度也相应的降低,微软开源的LightGBM提供了两个算法分别降低feature和data的大小:
1. GOSS(减少样本角度):保留梯度较大的样本数,减少梯度较小的样本个数 。样本训练误差小,表示该样本得到了很好的训练,对应的梯度亦越小 。一种直接的想法是抛弃这些梯度较小的样本,但是这种处理方法会改变样本集的分布,降低了训练模型的准确率(因为丢弃的都是损失误差较小的样本) 。因此,我们建议采用一种名为GOSS的方法,即GOSS保留具有大梯度的样本数,对梯度较小的样本进行随机采样,为了弥补数据集分布改变的影响,GOSS对小梯度的样本数增加了权重常数 。
GOSS伪代码如下:

参考GOSS的解释,伪代码应该比较容易理解吧!
伪代码中损失函数的梯度g代表的含义是一阶梯度和二阶梯度的乘积,见Github的实现( LightGBM/src/boosting/goss.hpp)。
2. EFB(从减少特征角度):捆绑(bundling)互斥特征,用一个特征代替多个互斥特征,达到减少特征个数的目的 。EFB算法需要解决两个问题,(1)捆绑互斥特征,(2)合并互斥特征 。这里就不详细介绍了。
3. 直方图做差优化
一个叶子节点的直方图可以由父亲节点的直方图与它兄弟的直方图做差得到 。利用这个方法,LightGBM可以用父亲节点的直方图减去数据量比较小的叶子节点直方图,得到数据量比较大的叶子节点直方图,因为该直方图是做差得到的,时间复杂度仅为O(#bins),比起不做差得到的兄弟节点的直方图,速度上可以提升一倍。
直方图做差示意图如下:

4. 树的生长策略
XGBoost是按层生长(level-wise)的方式展开节点,优点是不容易过拟合,缺点是它对每一层叶子节点不加区分的进行展开,实际上某些叶子节点的分裂增益较低,没必要进行搜索和分裂。如下图所示:

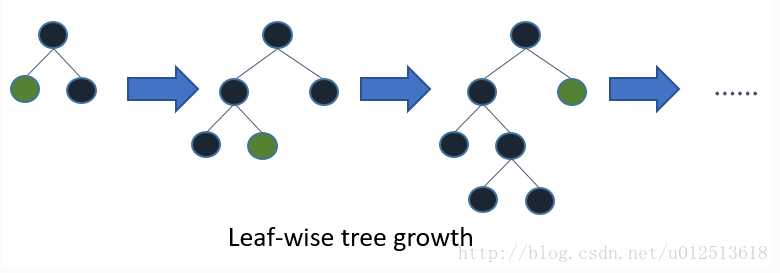
LightGBM是按最大增益的节点(叶子明智,Leaf-wise)进行展开,这样做的好处是找到分裂增益最大的叶子节点进行分裂,如此循环 。优点是效率高,在分裂次数相同的情况下,Leaf-wise可以得到更高的准确率 。缺点是可能会产生过拟合,通过设置树的最大生长深度避免 。如下图所示:

5. 支持类别特征
类别特征在实际项目中比较常见,XGBoost通过one-hot编码把类别特征转化为多维特征,降低了算法运行效率,LightGBM优化了类别特征的支持,不需要对类别特征进行one-hot编码 。
6. 支持高效并行
LightGBM支持特征并行和数据并行 。
特征并行:在不同机器选择局部不同特征对应的最优切分点,然后同步各机器结果,选择最优切分点 。如下图:

LightGBM对特征并行进行了优化,通过在本地保存全部数据避免对数据切分结果的通信 。
数据并行:不同机器在本地构造直方图,然后进行全局的合并,最后在合并的直方图上寻找最优分割点。如下图:

LightGBM有下面两种优化数据并行的方法:
(1)LightGBM通过"Reduce Scatter"将把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量 。
(2)LightGBM通过“PV-Tree”的算法进行投票并行(Voting Parallel),使通信开销变成常数级别,在数据量很大的时候,使用投票并行可以得到非常好的加速效果。如下图:

7. 与XGBoost的对比
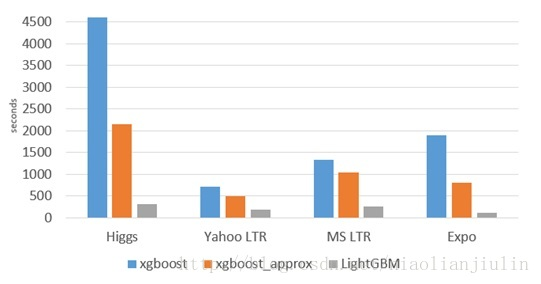
LightGBM相对于XGboost具有更快的训练效率和更低的内存使用,如下对比图:

LightGBM内存开销降低到原来的1/8倍 ,在Expo数据集上速度快了8倍和在Higg数据集上加速了40%,
LightGBM原理之论文详解
【Abstract】
Gradient Boosting Decision Tree (GBDT)非常流行却鲜有实现,只有像XGBoost和pGBRT。当特征维度较高和数据量巨大的时候,其实现中仍然存在效率和可扩展性的问题。一个主要原因就是对于每一个特征的每一个分裂点,都需要遍历全部数据计算信息增益,这一过程非常耗时。针对这一问题,本文提出两种新方法:Gradient-based One-Side Sampling (GOSS) 和Exclusive Feature Bundling (EFB)(基于梯度的one-side采样和互斥的特征捆绑)。在GOSS中,我们排除了重要的比例-具有小梯度的实例,只用剩下的来估计信息增益,我们证明,这些梯度大的实例在计算信息增益中扮演重要角色,GOSS可以用更小的数据量对信息增益进行相当准确的估计。对于EFB,我们捆绑互斥的特征(什么是互斥特征:例如特征间很少同时非零。),来降低特征的个数。我们证明完美地捆绑互斥特征是NP难的,但贪心算法能够实现相当好的逼近率,因此我们能够在不损害分割点准确率许多,有效减少特征的数量。(牺牲一点分割准确率降低特征数量),这一算法命名为LightGBM。在多个公共数据集实验证明,LightGBM加速了传统GBDT训练过程20倍以上,同时达到了几乎相同的精度 。
1. Introduction
GBDT因为其的有效性、准确性、可解释性,成为了广泛使用的机器学习算法。GBDT在许多机器学习任务上取得了最好的效果( state-of-the-art),例如多分类,点击预测,排序。但最近几年随着大数据的爆发(特征量和数据量),GBDT面临平衡准确率和效率的调整。
GBDT缺点:对于每一个特征的每一个分裂点,都需要遍历全部数据来计算信息增益。因此,其计算复杂度将受到特征数量和数据量双重影响,造成处理大数据时十分耗时。
解决这个问题的直接方法就是减少特征量和数据量而且不影响精确度,有部分工作根据数据权重采样来加速boosting的过程,但由于gbdt没有样本权重不能应用。而本文提出两种新方法实现此目标。
Gradient-based One-Side Sampling (GOSS):GBDT虽然没有数据权重,但每个数据实例有不同的梯度,根据计算信息增益的定义,梯度大的实例对信息增益有更大的影响,因此在下采样时,我们应该尽量保留梯度大的样本(预先设定阈值,或者最高百分位间),随机去掉梯度小的样本。我们证明此措施在相同的采样率下比随机采样获得更准确的结果,尤其是在信息增益范围较大时。
Exclusive Feature Bundling (EFB):通常在真实应用中,虽然特征量比较多,但是由于特征空间十分稀疏,是否可以设计一种无损的方法来减少有效特征呢?特别在稀疏特征空间上,许多特征几乎是互斥的(例如许多特征不会同时为非零值,像one-hot),我们可以捆绑互斥的特征。最后,我们将捆绑问题归约到图着色问题,通过贪心算法求得近似解。
2. Preliminaries
2.1 GBDT and Its Complexity Analysis
GBDT是一种集成模型的决策树,顺序训练决策树。每次迭代中,GBDT通过拟合负梯度(残差)来学到决策树。
学习决策树是GBDT主要的时间花销,而学习决策树中找到最优切分点最消耗时间。广泛采用的预排序算法来找到最优切分点,这种方法会列举预排序中所有可能的切分点。这种算法虽然能够找到最优的切分点,但对于训练速度和内存消耗上都效率低。另一种流行算法是直方图算法(histogram-based algorithm)。直方图算法并不通过特征排序找到最优的切分点,而是将连续的特征值抽象成离散的分箱,并使用这些分箱在训练过程中构建特征直方图,这种算法更加训练速度和内存消耗上都更加高效,lightGBM使用此种算法。
histogram-based算法通过直方图寻找最优切分点,其建直方图消耗O(#data * #feature),寻找最优切分点消耗O(#bin * # feature),而#bin的数量远小于#data,所以建直方图为主要时间消耗。如果能够减少数据量或特征量,那么还能够够加速GBDT的训练。
2.2 Related Work
GBDT有许多实现,如XGBoost,PGBRT,Scikit-learn,gbm in R。Scikit-learn和gbm in R实现都用了预排序,pGBRT使用了直方图算法,XGBoost支持预排序和直方图算法,由于XGBoost胜过其他算法,我们用它作为baseline。
为了减小训练数据集,通常做法是下采样。例如过滤掉权重小于阈值的数据。SGB每次迭代中用随机子集训练弱学习器。或者采样率基于训练过程动态调整。除了基于AdaBoost的SGB不能直接应用于GBDT,因为GBDT中没有原始的权重。虽然SGB也能间接应用于GBDT,但往往会影响精度。
同样,过滤掉弱特征(什么是弱特征)来减少特征量。通常用主成分分析或者投影法。当然,这些方法依赖于一个假设-特征包含高度的冗余,但实际中往往不是。(设计特征来自于其独特的贡献,移除任一维度都可以某种程度上影响精度)。
实际中大规模的数据集通常都是非常稀疏的,使用预排序算法的GBDT能够通过无视为0的特征来降低训练时间消耗。然后直方图算法没有优化稀疏的方案。因为直方图算法无论特征值是否为0,都需要为每个数据检索特征区间值。如果基于直方图的GBDT能够有效利用稀疏特征将是最优。
下图是两个算法的对比:
3. Gradient-based One-Side Sampling
GOSS是一种在减少数据量和保证精度上平衡的算法。
3.1 Algorithm Description
AdaBoost中,样本权重是数据实例重要性的指标。然而在GBDT中没有原始样本权重,不能应用权重采样。幸运的事,我们观察到GBDT中每个数据都有不同的梯度值,对采样十分有用,即实例的梯度小,实例训练误差也就较小,已经被学习得很好了,直接想法就是丢掉这部分梯度小的数据。然而这样做会改变数据的分布,将会影响训练的模型的精确度,为了避免此问题,我们提出了GOSS。
GOSS保留所有的梯度较大的实例,在梯度小的实例上使用随机采样。为了抵消对数据分布的影响,计算信息增益的时候,GOSS对小梯度的数据引入常量乘数。GOSS首先根据数据的梯度绝对值排序,选取top a个实例。然后在剩余的数据中随机采样b个实例。接着计算信息增益时为采样出的小梯度数据乘以(1-a)/b,这样算法就会更关注训练不足的实例,而不会过多改变原数据集的分布。
3.2 Theoretical Analysis
GBDT使用决策树,来学习获得一个将输入空间映射到梯度空间的函数。假设训练集有n个实例x1,...,xn,特征维度为s。每次梯度迭代时,模型数据变量的损失函数的负梯度方向为g1,...,gn,决策树通过最优切分点(最大信息增益点)将数据分到各个节点。GBDT通过分割后的方差衡量信息增益。
定义3.1:O表示某个固定节点的训练集,分割特征 j 的分割点d定义为:
其中,
遍历每个特征分裂点 j,找到
对应最大的分裂节点,并计算最大的信息增益。然后,将数据根据特征
的分裂点
将数据分到左右节点。
在GOSS中,
-
1. 首先根据数据的梯度将训练降序排序。
-
2. 保留top a个数据实例,作为数据子集A。
-
3. 对于剩下的数据的实例,随机采样获得大小为b的数据子集B。
-
4. 最后我们通过以下方程估计信息增益:
-
此处GOSS通过较小的数据集估计信息增益,将大大地减小计算量。更重要的是,我们接下来理论表明GOSS不会丢失许多训练精度,胜过(outperform)随机采样。理论的证明再附加材料。
Theorem 3.2 我们定义GOSS近似误差为:,且
,
概率至少是1−δ,有:
其中:
根据理论3.2,我们得出以下结论:
1. GOSS的渐进逼近比率是:
如果数据分割不是极不平衡,比如:
且
近似误差主要由第二项主导,当n趋于无穷(数据量很大)时,
![]() 趋于0。即数据量越大,误差越小,精度越高。
趋于0。即数据量越大,误差越小,精度越高。
2. 随机采样是GOSS在a=0的一种情况。多数情况下,GOSS性能优于随机采样,即以下情况:
即:
其中,
下面分析GOSS的泛化性。考虑GOSS泛化误差:
这是GOSS抽样的的实例计算出的方差增益与实际样本方差增益之间的差距。
变换为:
因此,在GOSS准确的情况下,GOSS泛化误差近似于全数据量的真实数据。另一方面,采样将增加基学习器的多样性(因为每次采样获得的数据可能会不同),这将提高泛化性。
4. Exclusive Feature Bundling
这一章介绍如何有效减少特征的数量
高维的数据通常是稀疏的,这种稀疏性启发我们设计一种无损地方法来减少特征的维度。特别的,稀疏特征空间中,许多特征是互斥的,例如他们从不同时为非零值。我们可以绑定互斥的特征为单一特征,通过仔细设计特征搜寻算法,我们从特征捆绑中构建了与单个特征相同的特征直方图。这种方式的间直方图时间复杂度从O(#data * #feature)降到O(#data * #bundle),由于#bundle << # feature,我们能够极大地加速GBDT的训练过程而且损失精度。
有两个问题:
-
1. 怎么判定那些特征应该绑在一起(build bundled)?
-
2. 怎么把特征绑为一个(merge feature)?
4.1 bundle(什么样的特征被绑定)?
**理论 4.1:**将特征分割为较小量的互斥特征群是NP难的。
证明:将图着色问题归约为此问题,而图着色是NP难的,所以此问题就是NP难的。
给定图着色实例G=(V, E)。以G的关联矩阵的每一行为特征,得到我们问题的一个实例有|V|个特征。 很容易看到,在我们的问题中,一个独特的特征包与一组具有相同颜色的顶点相对应,反之亦然。
理论4.1说明多项式时间中求解这个NP难问题不可行。为了寻找好的近似算法,我们将最优捆绑问题归结为图着色问题,如果两个特征之间不是相互排斥,那么我们用一个边将他们连接,然后用合理的贪婪算法(具有恒定的近似比)用于图着色来做特征捆绑。 此外,我们注意到通常有很多特征,尽管不是100%相互排斥的,也很少同时取非零值。 如果我们的算法可以允许一小部分的冲突,我们可以得到更少的特征包,进一步提高计算效率。经过简单的计算,随机污染小部分特征值将影响精度最多为:
γ是每个绑定中的最大冲突比率,当其相对较小时,能够完成精度和效率之间的平衡。
**算法3:**基于上面的讨论,我们设计了算法3,伪代码见下图,具体算法:
-
1.建立一个图,每个点代表特征,每个边有权重,其权重和特征之间总体冲突相关。
-
2. 按照降序排列图中的度数来排序特征。
-
3. 检查排序之后的每个特征,对他进行特征绑定或者建立新的绑定使得操作之后的总体冲突最小。
算法3的时间复杂度是O(#feature^2),训练之前只处理一次,其时间复杂度在特征不是特别多的情况下是可以接受的,但难以应对百万维的特征。为了继续提高效率,我们提出了一个更加高效的无图的排序策略:将特征按照非零值个数排序,这和使用图节点的度排序相似,因为更多的非零值通常会导致冲突,新算法在算法3基础上改变了排序策略。
4.2 merging features(特征合并)
如何合并同一个bundle的特征来降低训练时间复杂度。关键在于原始特征值可以从bundle中区分出来。鉴于直方图算法存储离散值而不是连续特征值,我们通过将互斥特征放在不同的箱中来构建bundle。这可以通过将偏移量添加到特征原始值中实现,例如,假设bundle中有两个特征,原始特征A取值[0, 10],B取值[0, 20]。我们添加偏移量10到B中,因此B取值[10, 30]。通过这种做法,就可以安全地将A、B特征合并,使用一个取值[0, 30]的特征取代AB。算法见算法4,
EFB算法能够将许多互斥的特征变为低维稠密的特征,就能够有效的避免不必要0值特征的计算。实际,通过用表记录数据中的非零值,来忽略零值特征,达到优化基础的直方图算法。通过扫描表中的数据,建直方图的时间复杂度将从O(#data)降到O(#non_zero_data)。当然,这种方法在构建树过程中需要而额外的内存和计算开销来维持预特征表。我们在lightGBM中将此优化作为基本函数,因为当bundles是稀疏的时候,这个优化与EFB不冲突(可以用于EFB)。
5. Experiments
这部分主要写了lightGBM的实验结果,主要用了五个公开数据集,如下
微软的排序数据集(LETOR)包括30K的网页搜索,数据集几乎都是稠密的数值特征。
Allstate是保险和航空延误数据都包含了大量的one-hot特征。
后两个是KDD CUP2010和KDD CPU2012数据集,使用了冠军解决方案中的特征,其中包含了稀疏和稠密的特征,并且这两个数据集特别大。
这些数据集都比较大,而且包含了稀疏和稠密的特征,涵盖了很多真实的业务,因此它们能够完全地测试lightGBM的性能。
5.1 Overall Comparison
XGBoost和lightGBM without GOSS 和EFB(lgb baseline),作为比较的基准。XGBoost使用了两个版本:xgb_exa(预排序)和xgb_his(直方图算法)。对于xgb_exa做了参数调整,使XGBoost长成和其他算法相似的树。并且调整参数在速度和准确率间平衡。对于Allstate、KDD10 和 KDD2012,设置a = 0.05 , b = 0.05 ,对于航空延误和LETOR,我们设置a = 0.1 , b = 0.1 ,数据集EFB我们设置γ = 0 。所有的算法有固定迭代次数。在一定迭代次数内,我们取最高的分数。
下表是训练时间对比(时间是每次迭代的平均时间)
下表是精确度对比,分类使用AUC评价,排序使用NDCG评价。
下图是飞行延时和LETOR的训练曲线。
5.2 Analysis on GOSS
**速度上:**GOSS具有加速训练的能力,表2中可以看出GOSS几乎加速了两倍。虽然GOSS用了10%-20%的数据训练,但是由于有一些额外的计算,所以加速并不和数据量成反比,但是GOSS仍然极大加速了训练。
**精度上:**从表4中可以看出,同样采样率,GOSS精度总比SGB好。
5.3 Analysis on EFB
表2表明,EFB在大数据集上能够极大加速训练。因为EFB合并大量的稀疏特征到低维稠密的特征,并且由于之前的孤立的特征被bundle到一起,能能够极大提高缓存的命中率,因此,它全部的效率提高是动态的。
综上这些分析,EFB是改进直方图算法稀疏性的非常高效的算法,能够极大地加速GBDT训练。
6. Conclusion
本文提出了新颖的GBDT算法–LightGBM,它包含了连个新颖的技术:Gradient-based One-Side Sampling (GOSS) 和Exclusive Feature Bundling (EFB)(基于梯度的one-side采样和互斥的特征捆绑)来处理大数据量和高维特征的场景。我们在理论分析和实验研究表明,GOSS和EFB使得LightGBM在计算速度和内存消耗上明显优于XGBoost和SGB。
未来,我们将研究优化如何在GOSS中选择a,b。继续提高EFB在高维特征上的性能,无论其是否是稀疏的。
LightGBM介绍及参数调优
1、LightGBM简介
LightGBM是一个梯度Boosting框架,使用基于决策树的学习算法。它可以说是分布式的,高效的,有以下优势:
1)更快的训练效率
2)低内存使用
3)更高的准确率
4)支持并行化学习
5)可以处理大规模数据
与常见的机器学习算法对比,速度是非常快的
2、XGboost的缺点
在讨论LightGBM时,不可避免的会提到XGboost,关于XGboost可以参考此博文
关于XGboost的不足之处主要有:
1)每轮迭代时,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
2)预排序方法的时间和空间的消耗都很大
3、LightGBM原理
1)直方图算法
直方图算法的基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
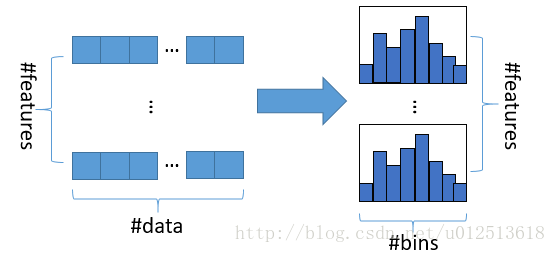
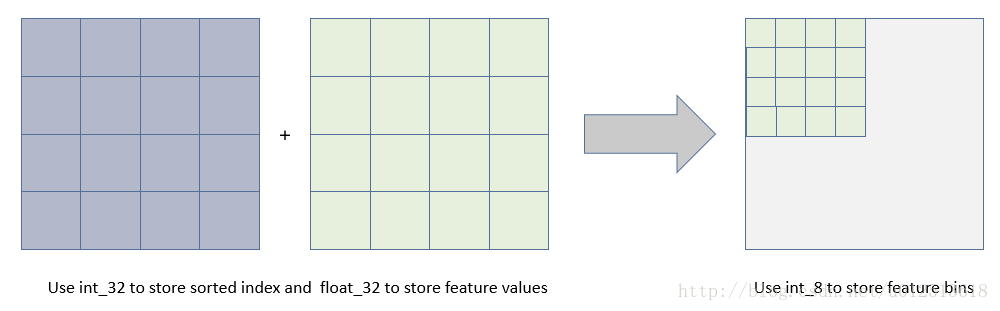
使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。
然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data * #feature) 优化到O(k* #features)。
当然,Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在不同的数据集上的结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。原因是决策树本来就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树的训练误差比精确分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下没有太大的影响。
2)LightGBM的直方图做差加速
一个容易观察到的现象:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。利用这个方法,LightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。

3)带深度限制的Leaf-wise的叶子生长策略
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
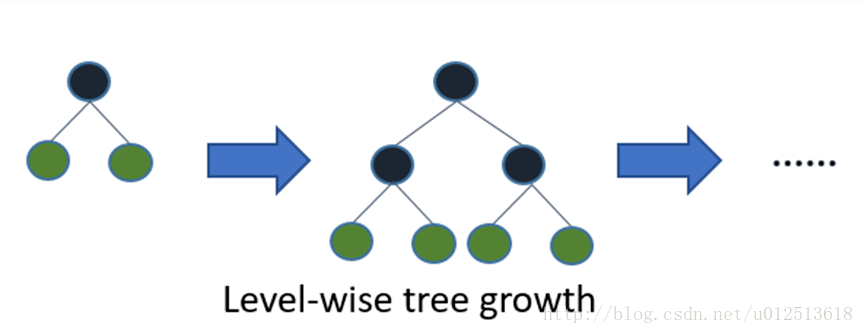
Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
4)直接支持类别特征(即不需要做one-hot编码)
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的one-hot编码特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的one-hot编码展开。并在决策树算法上增加了类别特征的决策规则。在Expo数据集上的实验,相比0/1展开的方法,训练速度可以加速8倍,并且精度一致。
5)直接支持高效并行
LightGBM还具有支持高效并行的优点。LightGBM原生支持并行学习,目前支持特征并行和数据并行的两种。
特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
LightGBM针对这两种并行方法都做了优化,在特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信;在数据并行中使用分散规约 (Reduce scatter) 把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。
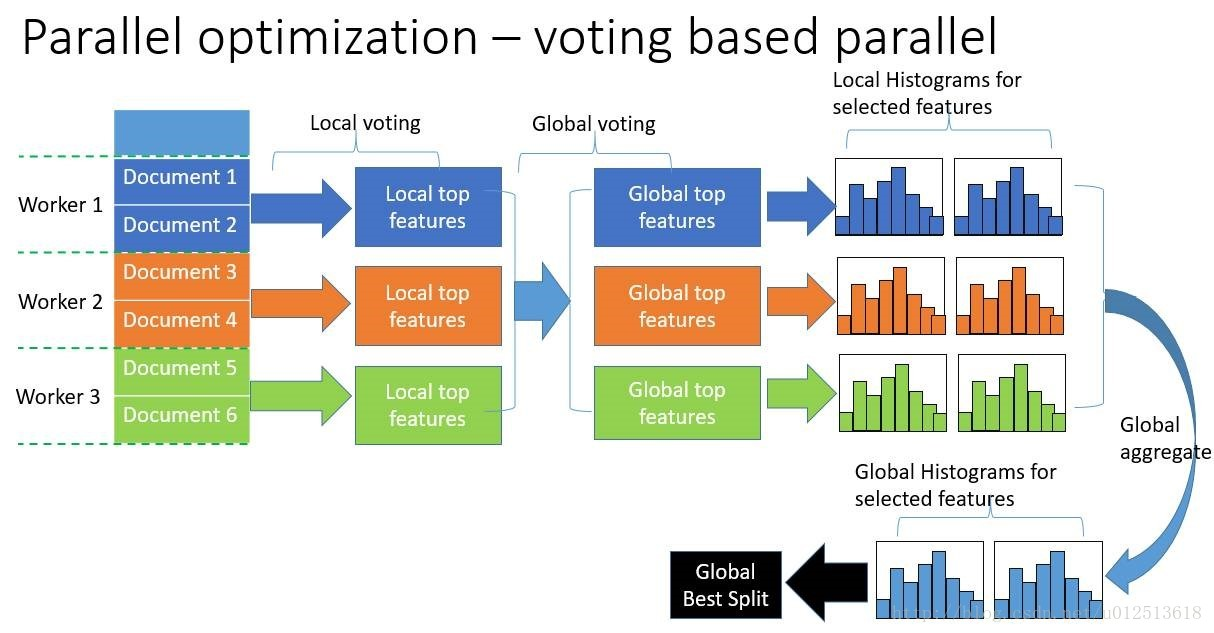
4、LightGBM参数调优
下面几张表为重要参数的含义和如何应用
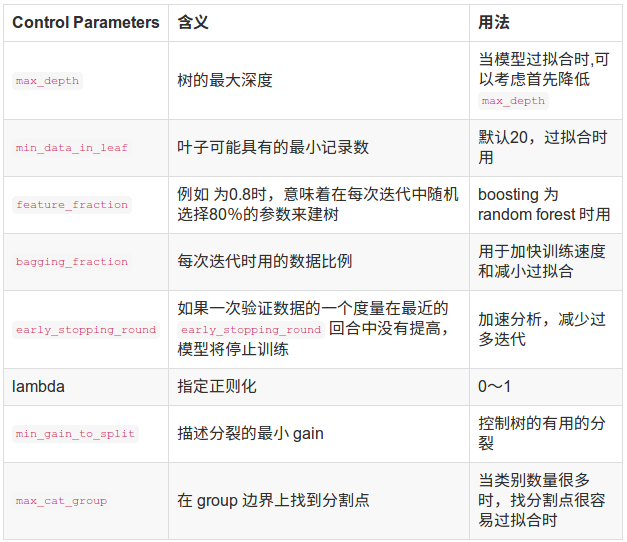


接下来是调参
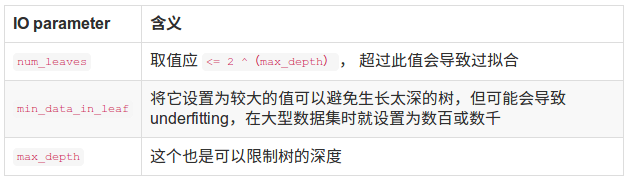
下表对应了Faster Spread,better accuracy,over-fitting三种目的时,可以调整的参数

CatBoost
CatBoost是俄罗斯的搜索巨头Yandex在2017年开源的机器学习库,是Gradient Boosting(梯度提升) + Categorical Features(类别型特征),也是基于梯度提升决策树的机器学习框架。
一、CatBoost技术介绍
1,类别型特征的处理
CatBoost采用了一种有效的策略,降低过拟合的同时也保证了全部数据集都可用于学习。也就是对数据集进行随机排列,计算相同类别值的样本的平均标签值时,只是将这个样本之前的样本的标签值纳入计算。
2,特征组合
为当前树构造新的分割点时,CatBoost会采用贪婪的策略考虑组合。对于树的第一次分割,不考虑任何组合。对于下一个分割,CatBoost将当前树的所有组合、类别型特征与数据集中的所有类别型特征相结合。组合被动态地转换为数字。CatBoost还通过以下方式生成数值型特征和类别型特征的组合:树选择的所有分割点都被视为具有两个值的类别型特征,并且组合方式和类别型特征一样。
3,克服梯度偏差
CatBoost,和所有标准梯度提升算法一样,都是通过构建新树来拟合当前模型的梯度。然而,所有经典的提升算法都存在由有偏的点态梯度估计引起的过拟合问题。许多利用GBDT技术的算法(例如,XGBoost、LightGBM),构建一棵树分为两个阶段:选择树结构和在树结构固定后计算叶子节点的值。为了选择最佳的树结构,算法通过枚举不同的分割,用这些分割构建树,对得到的叶子节点中计算值,然后对得到的树计算评分,最后选择最佳的分割。两个阶段叶子节点的值都是被当做梯度[8]或牛顿步长的近似值来计算。CatBoost第一阶段采用梯度步长的无偏估计,第二阶段使用传统的GBDT方案执行。
4,快速评分
CatBoost使用oblivious树作为基本预测器,这种树是平衡的,不太容易过拟合。oblivious树中,每个叶子节点的索引可以被编码为长度等于树深度的二进制向量。CatBoost首先将所有浮点特征、统计信息和独热编码特征进行二值化,然后使用二进制特征来计算模型预测值。
5基于GPU实现快速学习
5.1 密集的数值特征
任何GBDT算法,对于密集的数值特征数据集来说,搜索最佳分割是建立决策树时的主要计算负担。CatBoost利用oblivious决策树作为基础模型,并将特征离散化到固定数量的箱子中以减少内存使用。就GPU内存使用而言,CatBoost至少与LightGBM一样有效。主要改进之处就是利用了一种不依赖于原子操作的直方图计算方法。
5.2 类别型特征
CatBoost使用完美哈希来存储类别特征的值,以减少内存使用。由于GPU内存的限制,在CPU RAM中存储按位压缩的完美哈希,以及要求的数据流、重叠计算和内存等操作。通过哈希来分组观察。在每个组中,我们需要计算一些统计量的前缀和。该统计量的计算使用分段扫描GPU图元实现。
5.3 多GPU支持
CatBoost中的GPU实现可支持多个GPU。分布式树学习可以通过数据或特征进行并行化。CatBoost采用多个学习数据集排列的计算方案,在训练期间计算分类特征的统计数据。
二、CatBoost的优点
性能卓越:在性能方面可以匹敌任何先进的机器学习算法;
鲁棒性/强健性:它减少了对很多超参数调优的需求,并降低了过度拟合的机会,这也使得模型变得更加具有通用性;
易于使用:提供与scikit集成的Python接口,以及R和命令行界面;
实用:可以处理类别型、数值型特征;可扩展:支持自定义损失函数;
谁是数据竞赛王者?CatBoost vs. Light GBM vs. XGBoost
最近我参加了一个Kaggle比赛(斯坦福大学的WIDS Datathon),依靠各种boosting算法,我最后挤进了前十名。虽然成绩很好,但从那之后我就对模型集成学习的细节感到十分好奇:那些模型是怎么组合的?参数怎么调整?它们各自的优点和缺点又是什么?
考虑到自己曾经用过许多boosting算法,我决定写一篇文章来重点分析XGBoost、LGBM和CatBoost的综合表现。虽然最近神经网络很流行,但就我个人的观点来看,boosting算法在训练数据有限时更好用,训练时间更短,调参所需的专业知识也较少。
XGBoost是陈天奇于2014年提出的一种算法,被称为GBM Killer,因为介绍它的文章有很多,所以本文会在介绍CatBoost和LGBM上用更大的篇幅。以下是我们将要讨论的几个主题:
-
结构差异
-
处理分类变量
-
参数简介
-
数据集实现
-
算法性能
LightGBM和XGBoost的结构差异
虽然LightGBM和XGBoost都是基于决策树的boosting算法,但它们之间存在非常显著的结构差异。
LGBM采用leaf-wise生长策略,也就是基于梯度的单侧采样(GOSS)来找出用于分裂的数据实例,当增长到相同的叶子节点时,LGBM会直接找出分裂增益最大的叶子(通常是数据最大坨的那个),只分裂一个。

LightGBM
而XGBoost采用的则是level(depth)-wise生长策略,它用预排序算法+直方图算法为每一层的叶子找出最佳分裂,简而言之,就是它是不加区分地分裂同一层所有叶子。
XGBoost
我们先来看看预排序算法(pre-sorted)的工作方式:
-
对每个叶子(分割点)遍历所有特征;
-
对每个特征,按特征值对数据点进行排序;
-
确定当前特征的基本分裂增益,用线性扫描决定最佳分裂方法;
-
基于所有特征采取最佳分裂方法。
而直方图算法的工作方式则是根据当前特征把所有数据点分割称离散区域,然后利用这些区域查找直方图的分割值。虽然比起预排序算法那种在排序好的特征值上枚举所有可能的分割点的做法,直方图算法的效率更高,但它在速度上还是落后于GOSS。
那么为什么GOSS这么高效呢?
这里我们需要提到经典的AdaBoost。在AdaBoost中,数据点的权重是数据点重要与否的一个直观指标,但梯度提升决策树(GBDT)不自带这种权重,因此也就无法沿用AdaBoost的采样方法。
基于梯度的采样:梯度指的是损失函数切线的斜率,所以从逻辑上说,如果一些数据点的梯度很大,那它们对于找到最佳分裂方法来说就很重要,因为它们具有较高的误差。
GOSS保留了所有具有大梯度的数据点,并对梯度小的数据点进行随机采样。例如,假设我有50万行数据,其中1万行梯度高,剩下的49万行梯度低,那我的算法就会选择1万行+49万行×x%(随机)。设x=10,最终算法选出的就是50万行数据中的5.9万行。
这里存在一个基本假设,即梯度较小的数据点具有更低的误差,而且已经训练好了
为了保持相同的数据分布,在计算分裂增益时,GOSS会为这些梯度小的数据点引入一个常数乘数。以上就是它能在减少数据点数量和保证决策树准确性之间取得平衡的方法。
处理分类变量
CatBoost
CatBoost在分类变量索引方面具有相当的灵活性,它可以用在各种统计上的分类特征和数值特征的组合将分类值编码成数字(one_hot_max_size:如果feature包含的不同值的数目超过了指定值,将feature转化为float)。
如果你没有在cat_features语句中传递任何内容,CatBoost会把所有列视为数值变量。
注:如果在
cat_features中未提供具有字符串值的列,CatBoost会报错。此外,具有默认int类型的列在默认情况下也会被视为数字,所以你要提前手动定义。
对于分类值大于one_hot_max_size的那些分类变量,CatBoost也有一种有效的方法。它和均值编码类似,但可以防止过拟合:
-
对输入样本重新排序,并生成多个随机排列;
-
将label值从浮点或类别转换为整型;
-
用以下公式把所有分类特征值转换为数值,其中CountInClass表示截至当前样本,label值=1的次数(相同样本总数);Prior表示平滑因子,它由起始参数确定;而TotalCount则代表截至当前样本,所有样本的总数。

如果转换为数学公式,它长这样:

LightGBM
和CatBoost类似,LightGBM也可以通过输入特征名称来处理分类特征。它无需进行独热编码(one-hot coding),而是使用一种特殊的算法直接查找分类特征的拆分值,最后不仅效果相似,而且速度更快。

注:在为LGBM构造数据集之前,应将分类特征转换为整型数据,即便你用了categorical_feature参数,算法也无法识别字符串值。
XGBoost
XGBoost无法单独处理分类特征,它是基于CART的,所以只接收数值。在把分类数据提供给算法前,我们先得执行各种编码,如标签编码、均值编码、独热编码等。
相似的超参数
这三种算法涉及的超参数有很多,这里我们只介绍几个重要的。下表是它们的对比:
数据集实现
我使用的是2015年航班延误的Kaggle数据集,因为它同时包含分类特征和数字特征,而且大约有500万行数据,无论是从训练速度上看还是从模型的准确率上看,它都可以作为一个很好的性能判断工具。
我从数据集中抽取10%(50万行)作为实验数据,以下是建模使用的特征:
-
MONTH,DAY,DAYOFWEEK:整型数据
-
AIRLINE和FLIGHT_NUMBER:整型数据
-
ORIGINAIRPORT和DESTINATIONAIRPORT:字符串
-
DEPARTURE_TIME:float
-
ARRIVAL_DELAY:预测目标,航班延迟是否超过10分钟?
-
DISTANCE和AIR_TIME:float
-
import pandas as pd, numpy as np, time
-
from sklearn.model_selection import train_test_split
-
data = pd.read_csv("flights.csv")
-
data = data.sample(frac = 0.1, random_state=10)
-
data = data[["MONTH","DAY","DAY_OF_WEEK","AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT",
-
"ORIGIN_AIRPORT","AIR_TIME", "DEPARTURE_TIME","DISTANCE","ARRIVAL_DELAY"]]
-
data.dropna(inplace=True)
-
data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"]>10)*1
-
cols = ["AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT","ORIGIN_AIRPORT"]
-
for item in cols:
-
data[item] = data[item].astype("category").cat.codes +1
-
train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"],
-
random_state=10, test_size=0.25)
XGBoost-
import xgboost as xgb
-
from sklearn import metrics
-
def auc(m, train, test):
-
return (metrics.roc_auc_score(y_train,m.predict_proba(train)[:,1]),
-
metrics.roc_auc_score(y_test,m.predict_proba(test)[:,1]))
-
# Parameter Tuning
-
model = xgb.XGBClassifier()
-
param_dist = {"max_depth": [10,30,50],
-
"min_child_weight" : [1,3,6],
-
"n_estimators": [200],
-
"learning_rate": [0.05, 0.1,0.16],}
-
grid_search = GridSearchCV(model, param_grid=param_dist, cv = 3,
-
verbose=10, n_jobs=-1)
-
grid_search.fit(train, y_train)
-
grid_search.best_estimator_
-
model = xgb.XGBClassifier(max_depth=50, min_child_weight=1, n_estimators=200,\
-
n_jobs=-1 , verbose=1,learning_rate=0.16)
-
model.fit(train,y_train)
-
auc(model, train, test)
Light GBM
-
import lightgbm as lgb
-
from sklearn import metrics
-
def auc2(m, train, test):
-
return (metrics.roc_auc_score(y_train,m.predict(train)),
-
metrics.roc_auc_score(y_test,m.predict(test)))
-
lg = lgb.LGBMClassifier(silent=False)
-
param_dist = {"max_depth": [25,50, 75],
-
"learning_rate" : [0.01,0.05,0.1],
-
"num_leaves": [300,900,1200],
-
"n_estimators": [200]
-
}
-
grid_search = GridSearchCV(lg, n_jobs=-1, param_grid=param_dist, cv = 3, scoring="roc_auc", verbose=5)
-
grid_search.fit(train,y_train)
-
grid_search.best_estimator_
-
d_train = lgb.Dataset(train, label=y_train)
-
params = {"max_depth": 50, "learning_rate" : 0.1, "num_leaves": 900, "n_estimators": 300}
-
# Without Categorical Features
-
model2 = lgb.train(params, d_train)
-
auc2(model2, train, test)
-
#With Catgeorical Features
-
cate_features_name = ["MONTH","DAY","DAY_OF_WEEK","AIRLINE","DESTINATION_AIRPORT",
-
"ORIGIN_AIRPORT"]
-
model2 = lgb.train(params, d_train, categorical_feature = cate_features_name)
-
auc2(model2, train, test)
CatBoost
在为CatBoost调参时,我发现它很难为分类特征传递索引。所以我针对没传递的特征调整了参数,最后有了两个模型:一个包含分类特征,一个不包含。因为onehotmax_size不影响其他参数,所以我单独对它做了调整。
-
import catboost as cb
-
cat_features_index = [0,1,2,3,4,5,6]
-
def auc(m, train, test):
-
return (metrics.roc_auc_score(y_train,m.predict_proba(train)[:,1]),
-
metrics.roc_auc_score(y_test,m.predict_proba(test)[:,1]))
-
params = {'depth': [4, 7, 10],
-
'learning_rate' : [0.03, 0.1, 0.15],
-
'l2_leaf_reg': [1,4,9],
-
'iterations': [300]}
-
cb = cb.CatBoostClassifier()
-
cb_model = GridSearchCV(cb, params, scoring="roc_auc", cv = 3)
-
cb_model.fit(train, y_train)
-
With Categorical features
-
clf = cb.CatBoostClassifier(eval_metric="AUC", depth=10, iterations= 500, l2_leaf_reg= 9, learning_rate= 0.15)
-
clf.fit(train,y_train)
-
auc(clf, train, test)
-
With Categorical features
-
clf = cb.CatBoostClassifier(eval_metric="AUC",one_hot_max_size=31, \
-
depth=10, iterations= 500, l2_leaf_reg= 9, learning_rate= 0.15)
-
clf.fit(train,y_train, cat_features= cat_features_index)
-
auc(clf, train, test)
结果
现在我们就能从训练速度和准确率两个维度对3种算法进行评价了。
如上表所示,CatBoost在测试集上的准确率高达0.816,同时过拟合程度最低,训练时长短,预测时间也最少。但它真的打败其他两种算发了吗?很可惜,没有。0.816这个准确率的前提是我们考虑了分类变量,而且单独调整了onehotmax_size。如果没有充分利用算法的特性,CatBoost的表现是最差的,准确率只有0.752。
所以我们可以得出这样一个结论:如果数据中存在分类变量,我们可以充分利用CatBoost的特性得到一个更好的训练结果。
接着就是我们的数据竞赛王者XGBoost。它的表现很稳定,如果忽略之前的数据转换工作,单从准确率上看它和CatBoost非常接近。但是XGBoost的缺点是太慢了,尤其是调参过程,简直令人绝望(我花了6小时摆弄GridSearchCV)。
最后就是Light GBM,这里我想提一点,就是用cat_features时它的速度和准确率会非常糟糕,我猜测这可能是因为这时算法会在分类数据中用某种改良过的均值编码,之后就过拟合了。如果我们能像XGBoost一样操作,它也许可以在速度秒杀XGBoost的同时达到后者的精度。
综上所述,这些观察结果都是对应这个数据集得出的结论,它们可能不适用于其他数据集。我在文中没有展示交叉验证过程,但我确实尝试了,结果差不多。话虽如此,但有一个结果是千真万确的:XGBoost确实比其他两种算法更慢。
-
import numpy as np
-
from catboost import CatBoostClassifier,CatBoostRegressor,Pool
-
-
-
#####¥##################分类#################################
-
train_data=np.random.randint(0,100,size=(100,10))
-
train_label=np.random.randint(0,2,size=(100))
-
test_data=np.random.randint(0,100,size=(50,10))
-
model=CatBoostClassifier(iterations=2,depth=2,learning_rate=1,loss_function='Logloss', logging_level='Verbose')
-
model.fit(train_data,train_label,cat_features=[0,2,5])
-
preds_class=model.predict(test_data)
-
preds_proba=model.predict_proba(test_data)
-
print("class=",preds_class)
-
print("proba=",preds_proba)
-
-
-
#####¥##################回归#################################
-
train_data = np.random.randint(0, 100, size=(100, 10))
-
train_label = np.random.randint(0, 1000, size=(100))
-
test_data = np.random.randint(0, 100, size=(50, 10))
-
# initialize Pool
-
train_pool = Pool(train_data, train_label, cat_features=[0,2,5])
-
test_pool = Pool(test_data, cat_features=[0,2,5])
-
-
# specify the training parameters
-
model = CatBoostRegressor(iterations=2, depth=2, learning_rate=1, loss_function='RMSE')
-
#train the model
-
model.fit(train_pool)
-
# make the prediction using the resulting model
-
preds = model.predict(test_pool)
-
print(preds)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人