

集成学习—多算法融合
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
集成学习(Emsemble Learning)–融合学习
分类和回归的延续和升华
使用一系列学习器进行学习,把各个学习结果进行融合,
从而获得比单个学习器更好的学习效果的一种机器学习方法。一、基学习器构建方法
1. 不同的算法,相同的训练集
2. 相同的算法,不同的参数设置
3. 不同的训练集,相同的算法(Bagging Boosting)
附:(A:算法 C:分类器)
三. 模型融合
单个模型容易发生过拟合,多个模型提高泛化能力(提升预测能力)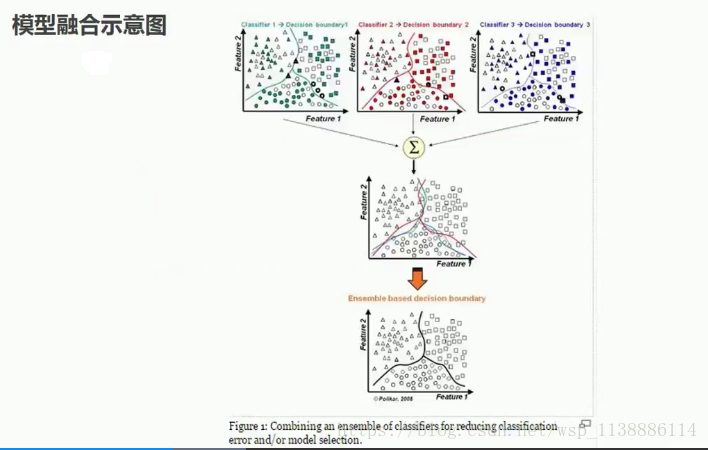
3.1 Voting 和 Averaging 融合
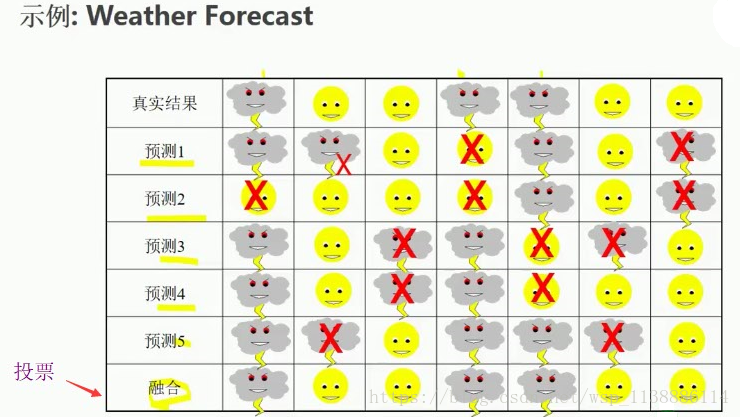
Voting: 投票法 --针对分类问题
硬投票(hard):基于分类标签投票
软投票(soft):基于分类标签概率投票代码:
sklearn.ensemble.VotingClassifier(
estimators,
voting = 'hard',
weights = None,
flatten_transform = None
)
一些重要的参数:
estimators: list if (string,estimators)tuples 需要融合的多个分类器
voting: str,{'hard','soft'}(default = 'hard') 投票方式
weights: array-like,shape = [n_classifiers],optional(default = 'None') 是否加权Averaging: 平均法 --针对回归问题
简单平均
加权平均
3.2 Bagging 融合—并行训练 (例如 随机森林)
Bagging:关键两步:
Bootstrap取样(重复有放回);
模型综合Bagging 融合:
1. 既要利用训练集中更多的样本,又要同时尽量保证训练集的独立性。
2. 在可重复取样中,我们假设每个样本被选中的概率一样。
3. 一般情况下,使用 bootstrap 取样得到的 n 个样本中既有重复的,也有原来没被抽到的:
极端情况:bootstrap 取样得到整个原来的数据集。
可以使用(一次都没有抽中的 【OOB】out-of-sample)训练集样本来估计基学习器的性能。
4. 有放回K次取样--并行训练(K个子模型)分类器--投票/平均--强分类器
优点:多个分类器噪声控制好,结果具有稳定性。
不易出现过拟合现象---是一种减少方差(variance)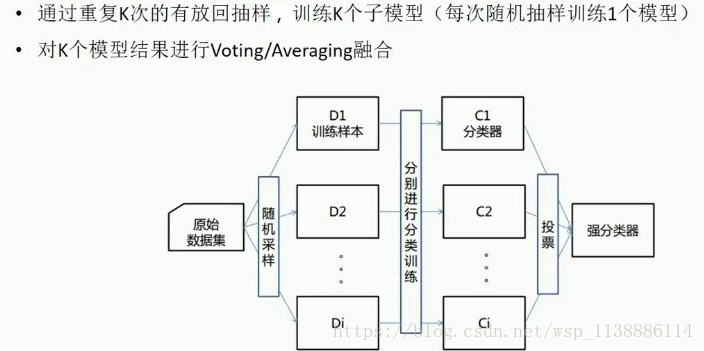
3.3 Boosting 融合—-串行(迭代)训练
每次训练都关心上次分类错误的样例--给分类错误的样例更大的权重
---下一次训练识别上一次的错误
---最终将多次迭代训练得到的弱分类器进行加权相加得到最终的强分类器
优点:多个分类器噪声控制好,结果具有稳定性。
不易出现过拟合现象---是一种减少篇差(bias)
Boosting 融合典型代表算法--Adaboost
GBDT(Gradient Boosting Decision Tree)
XGBoost3.3 Stacking
一般偏向简单模型(如 线性回归)
1. 计算复杂度较大(计算多个模型并综合)
分类:
AI(人工智能)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2018-08-20 2017年5大最热门区块链话题