

决策树的可视化输出
前面的博客里有提到决策树,我们也了解了决策树的构建过程,如果可以可视化决策树,把决策树打印出来,对我们理解决策树的构建会有很大的帮助。这篇文章中,我们就来看下如何可视化输出一棵决策树。
一、安装相应的插件
我们需要安装Graphviz和pygraphviz,教程,这个教程里有详细的安装过程,这里就不赘述了。
二、运行实例
我们依然以iris数据集为例,打印输出决策树看下效果。
-
#coding=utf-8
-
import numpy as np
-
import pandas as pd
-
import pydotplus
-
def lrisTrain():
-
#预处理-引入鸢尾数据:
-
from sklearn.datasets import load_iris
-
iris = load_iris()
-
-
from sklearn.cross_validation import train_test_split
-
# 把数据分为测试数据和验证数据
-
train_data,test_data,train_target,test_target=train_test_split(iris.data,iris.target,test_size=0.2,random_state=1)
-
#Model(建模)-引入决策树
-
from sklearn import tree
-
#建立一个分类器
-
clf = tree.DecisionTreeClassifier(criterion="entropy")
-
#训练集进行训练
-
clf.fit(train_data,train_target)
-
#画图方法1-生成dot文件
-
with open('treeone.dot', 'w') as f:
-
dot_data = tree.export_graphviz(clf, out_file=None)
-
f.write(dot_data)
-
-
#画图方法2-生成pdf文件
-
dot_data = tree.export_graphviz(clf, out_file=None,feature_names=clf.feature_importances_,
-
filled=True, rounded=True, special_characters=True)
-
graph = pydotplus.graph_from_dot_data(dot_data)
-
###保存图像到pdf文件
-
graph.write_pdf("treetwo.pdf")
-
-
#进行预测
-
y_pred = clf.predict(test_data)
-
-
#Verify(验证)
-
#引入模块
-
from sklearn import metrics
-
#法一:通过准确率进行验证
-
print(metrics.accuracy_score(y_true =test_target,y_pred=y_pred))
-
#法二:通过混淆矩阵验证(横轴:实际值,纵轴:预测值)(理想情况下是个对角阵)
-
#print(metrics.confusion_matrix(y_true=test_target,y_pred=y_pred))
-
lrisTrain()
三、输出结果
上述的两个方法将会产生两个文件,一个是dot文件,我们打开这个dot文件,得到的是决策树生成的文本结构信息:

如何把它转换成树的图形结构呢?
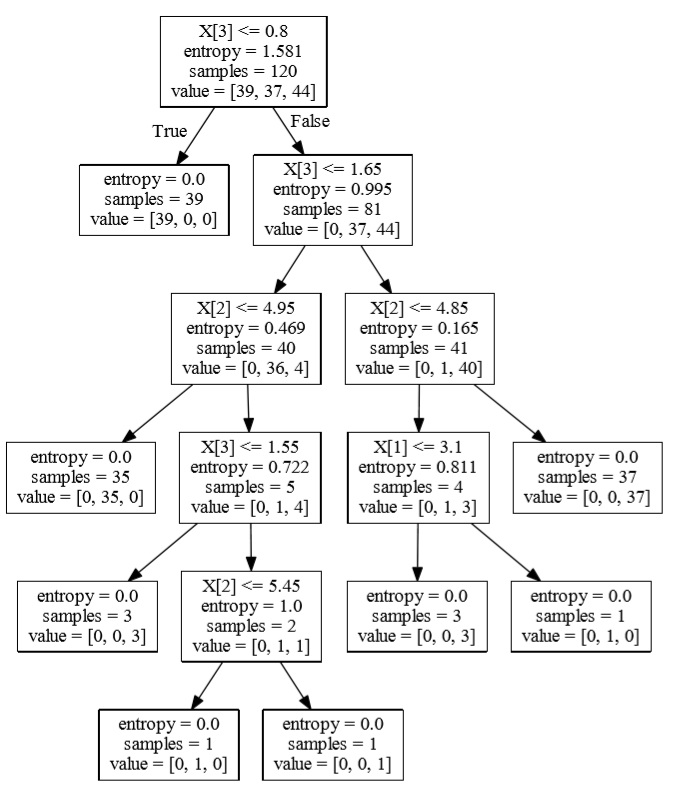
打开一个黑窗口(cmd,Anaconda prompt...都可以),先定位到生成的决策树 treeone.dot 所在的路径下,然后输入命令行:dot -Tpdf treeone.dot -o treeone.pdf ,这样就把名为treeone.dot文件在当前目录下编译生成了treeone.pdf文件,打开后效果如下:
生成的第二个文件treetwo.pdf就可以直接打开了,效果如下:
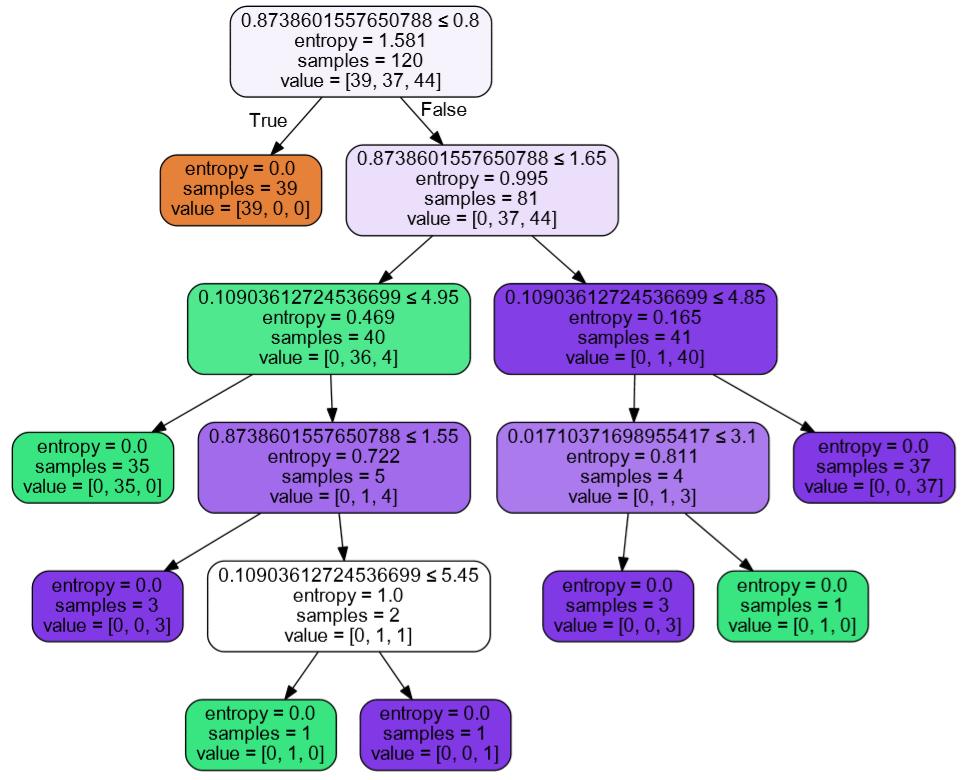
我们生成决策树就是调用了export_graphviz函数,这个函数有很多参数值,可以通过设置这些参数值,控制生成节点上的输出信息,大家可以根据自己的需求设置参数。
小结:我们这里是用sklearn中的DecisionTreeClassifier进行分类的,构建模型的时候只用到了这一棵决策树。后面我们会将到集成学习算法xgboost算法中决策树的可视化,xgboost是直接用它自己封装的plot_tree这个类来进行输出,不需要单独安装插件,反而更加容易可视化输出决策树。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人