Redis-分布式锁(解决缓存击穿问题)
一. 简介
分布式锁在很多场景中都非常的有用,分布式锁是一个概念,实现他的方式有很多,本篇文章是基于Redis实现的单机分布式锁。
主要解决多并发编程中由于锁竞争而带来的数据不一致的问题。
二. 应用场景
在本篇文章中主要解决Redis中缓存击穿问题。
并发的访问一条数据,数据库有,但是缓存中不存在(没人访问这条数据或者Redis中数据刚好过期),导致一瞬间多个请求访问数据库,数据库压力增大,这类数据通常为热点数据。
三. 模拟缓存击穿
以下程序模拟100个线程同时去访问一条没有缓存的数据。
1. 业务代码(service层)
@Override
public Object listByRedis(String id) {
HashMap<Object, Object> result = new HashMap<>();
//通过布隆过滤器 解决缓存穿透问题. 会有误判 但是没有关系 不会有太多误判。
if (!bloomFilter.isExist(id)){
result.put("status", 400);
result.put("msg", "非法访问");
return result;
}
//查询缓存
Object redisData = redisTemplate.opsForValue().get(id);
//是否命中
if(redisData != null){
//返回结果
result.put("status", 200);
result.put("msg", "缓存命中");
result.put("data", redisData);
return result;
}
try {
UserInfo userInfo = userInfoMapper.selectById(id);
if (userInfo != null){
redisTemplate.opsForValue().set(id, userInfo, 10, TimeUnit.MINUTES);
result.put("status", 200);
result.put("msg", "查询数据库");
result.put("data", userInfo);
return result;
}else{
result.put("status", 200);
result.put("msg", "没有数据");
return result;
}
}finally {
}
}2. 并发模拟
并发访问id=1096这条数据
public class ReadTest {
private static CountDownLatch countDownLatch = new CountDownLatch(99);
@Test
public void test() throws InterruptedException {
TicketsRunBle ticketsRunBle = new TicketsRunBle();
for (int i = 0;i<=99;i++){
new Thread(ticketsRunBle, "窗口"+i).start();
countDownLatch.countDown();
}
Thread.currentThread().join();
}
public class TicketsRunBle implements Runnable{
@Override
public void run() {
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
RestTemplate restTemplate = new RestTemplate();
R forObject = restTemplate.getForObject("http://localhost:8082/user?id=1096", R.class);
System.out.println("结果:" + forObject);
}
}
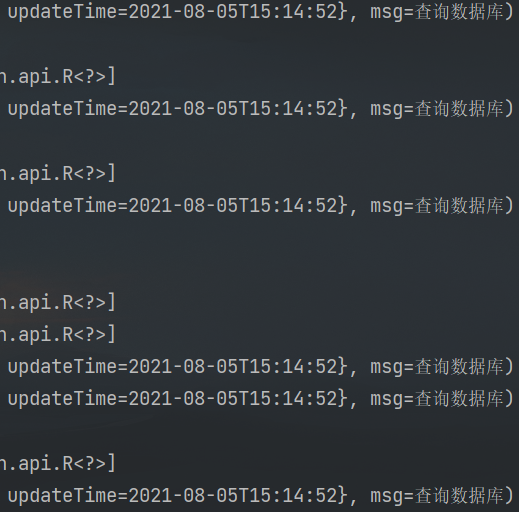
}3. 执行结果
截取部分,都是数据库查询出来的,日志打印也有Mybatis的记录。
四. 单机Redis分布式锁的实现
Redis分布式锁原理上是使用Setnx命令实现:
SET resource_name my_random_value NX PX 30000。
这个命令仅在不存在key的时候才能被执行成功(NX选项),并且这个key有一个30秒的自动失效时间(PX属性)。这个key的值是“my_random_value”(一个随机值),这个值在所有的客户端必须是唯一的,所有同一key的获取者(竞争者)这个值都不能一样。
当client尝试获取锁时,我们将事先定义的key设置一个值,之后的client再设置时则会不成功。
释放锁时实现:
为什么value要使用一个唯一的值,主要是为了更安全的释放锁,释放锁的时候使用脚本告诉Redis:只有key存在并且存储的值和我指定的值一样才能告诉我删除成功。可以通过以下Lua脚本实现:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end使用这种方式可以避免删除别的Client获得的锁。举个栗子:
客户端A取得资源锁,但是紧接着被一个其他操作阻塞了,当客户端A运行完毕其他操作后要释放锁时,原来的锁早已超时并且被Redis自动释放,并且在这期间资源锁又被客户端B再次获取到。如果仅使用DEL命令将key删除,那么这种情况就会把客户端B的锁给删除掉。使用Lua脚本就不会存在这种情况,因为脚本仅会删除value等于客户端A的value的key(value相当于客户端的一个签名)。
本篇文章获取锁有一点不同,上面说的是设置一个固定的key,而本篇文章解决的问题是基于单条数据的一个并发查询。
所以需要对单条数据的ID作为key进行加锁,防止查询同一条数据多次访问数据库。
1. 锁实现:
/**
* 自定义分布式锁
* 这里主要实现对单条数据进行加锁,通过id进行加锁
* 多个线程同时访问该数据会阻塞
* @author
* @Date 2022/1/6
*/
@Component
public class RedisLock {
private static JedisPool jedisPool;
@Autowired
public void setJedisPool(JedisPool jedisPool){
RedisLock.jedisPool = jedisPool;
}
/**
* 锁健
*/
private final static String KEY = "lock_key_";
/**
* 锁过期时间
*/
private final static long LOCK_EXPIRED = 30000;
/**
* 锁竞争超时时间
*/
private final static long LOCK_WAIT_TIME_OUT = 999999;
/**
* SET命令参数
*/
static SetParams params = SetParams.setParams().nx().px(LOCK_EXPIRED);
/**
* ThreadLocal用于保存某个线程共享变量:对于同一个static ThreadLocal
* 不同的线程只能从中get,set到自己线程的副本
*/
private static ThreadLocal<String> threadLocal = new ThreadLocal<>();
/**
* 尝试获取锁
* @param key
* @return
*/
public Boolean tryLock(String key){
String value = UUID.randomUUID().toString();
Jedis resource = jedisPool.getResource();
long startTime = System.currentTimeMillis();
try {
for(;;){
//SET命令返回OK,获取锁成功
String set = resource.set(KEY.concat(key), value, params);
if ("OK".equals(set)){
threadLocal.set(value);
return true;
}
//增加一个超时时间判断
if(System.currentTimeMillis() - startTime > LOCK_WAIT_TIME_OUT){
return false;
}
//休眠一段时间 递归调用
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}finally {
resource.close();
}
}
/**
* 释放锁 通过lua脚本实现
* @param key
* @return
*/
public boolean unLock(String key){
Jedis resource = null;
try {
resource = jedisPool.getResource();
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then" +
" return redis.call('del', KEYS[1]) " +
"else" +
" return 0 " +
"end";
Object eval = resource.eval(script, Collections.singletonList(KEY.concat(key)), Collections.singletonList(threadLocal.get()));
if ("1".equals(eval.toString())) {
return true;
}
return false;
}catch (Exception e){
e.printStackTrace();
return false;
}finally {
if (resource != null){
resource.close();
}
}
}
}
2. 业务代码(service层)
@Override
public Object listByRedis(String id) {
HashMap<Object, Object> result = new HashMap<>();
//通过布隆过滤器 解决缓存穿透问题. 会有误判 但是没有关系 不会有太多误判。
if (!bloomFilter.isExist(id)){
result.put("status", 400);
result.put("msg", "非法访问");
return result;
}
//查询缓存
Object redisData = redisTemplate.opsForValue().get(id);
//是否命中
if(redisData != null){
//返回结果
result.put("status", 200);
result.put("msg", "缓存命中");
result.put("data", redisData);
return result;
}
try {
//添加分布式锁,进来后在查询一次缓存,如果上一个线程已经查询并且存入缓存
Boolean lock = redisLock.tryLock(id);
if (!lock){
result.put("status", 500);
result.put("msg", "访问超时,稍后再试");
return result;
}
//查询缓存
redisData = redisTemplate.opsForValue().get(id);
//是否命中
if(redisData != null){
//返回结果
result.put("status", 200);
result.put("msg", "缓存命中");
result.put("data", redisData);
return result;
}
UserInfo userInfo = userInfoMapper.selectById(id);
if (userInfo != null){
redisTemplate.opsForValue().set(id, userInfo, 10, TimeUnit.MINUTES);
result.put("status", 200);
result.put("msg", "查询数据库");
result.put("data", userInfo);
return result;
}else{
result.put("status", 200);
result.put("msg", "没有数据");
return result;
}
}finally {
redisLock.unLock(id);
}
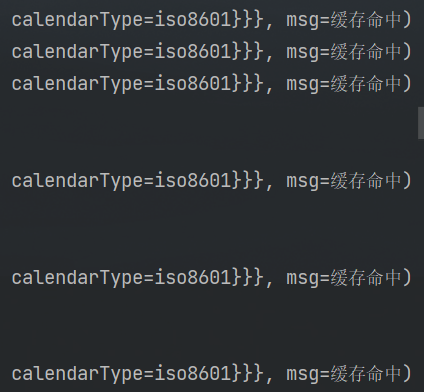
}3. 测试结果
打印日志显示,只会有一次数据库查询。
返回的结果除了第一次是查询数据库,后面的都是缓存命中

五. 总结
该锁的实现有很多不足之处,不断了解学习的一个过程,可使用Redisson中实现的分布式锁可用性更高。
本文来自博客园,作者:EchoLv,转载请注明原文链接:https://www.cnblogs.com/lvdeyinBlog/p/15774412.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号