
一文理解GIT的代码冲突
对于GIT,不知道有没有人和我一样,很长时间都是小心翼翼、紧张兮兮,生怕一不小心,自己辛苦写的代码没了。
特别是代码冲突,更是难到我无法理解,每次都要求助于百度,跟着人家的教程一步步解决,下一次还是这样。
所有的紧张、不自信、不敢用、用不好,都来源于:不理解。
只要理解了,你会发现所有问题一下子没了,所有焦虑一下子释然,你变的自信而坚定。
接下来说一下我对GIT代码冲突的理解,希望能帮助到你。
GIT的代码冲突主要存在于两个地方:
(1)本地仓库和远程仓库之间
场景一般是:你从远程仓库拉取了代码开始开发,在这期间,有同事提交了代码,等你提交时,报错不让你提交了。
(2)本地的分支之间
场景一般是:你从master分支拉出了develop分支,在develop分支上开发,在这期间,各种原因,master分支发生了变化。等你想把develop分支合并到master分支,提示代码冲突。
其实,本质都是一样的,我们用一个简单的模型来解释,为什么会出现代码冲突。
(1)没有冲突的场景:
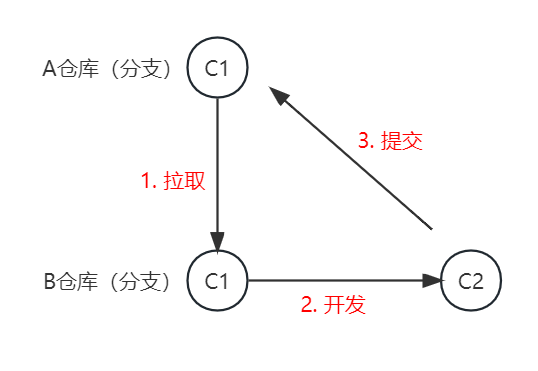
我们把A仓库(分支)的代码拉取到B仓库(分支),一顿开发后,向A提交。
这么做一点问题都没有,既然你是在我之上修改的船新版本,很好,一切以你为准,没问题。
(2)冲突来了:
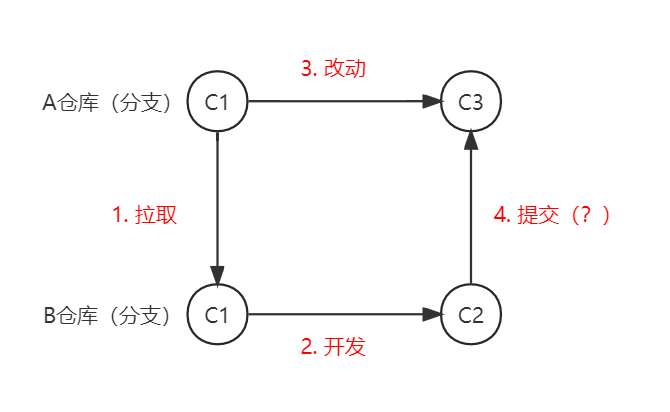
我们把A仓库(分支)的代码拉取到B仓库(分支),在我们开发的过程中,A发生了变化(不管什么原因),开发完成后我们再向A提交。
不用说GIT,我们自己都会觉得这事儿有问题。
我们俩都是在老代码之上修改的船新版本,那么以谁为准啊?咱俩改的不是一个地方还好说,如果改的是同一个地方,那么GIT根本没法自己判断选择哪一个。
这就是GIT的代码冲突,一句话:你跑了一趟回来(开发完成回来提交),它已经变了(相比当初拉取代码时,发生了变化)。
那么,GIT是怎么处理代码冲突的呢?有两种方式:
第一种方式:B仍然向A提交代码,A进行代码合并、处理冲突后,B再把A的代码拉过来,A和B都是最新版本了。

我们分别看一下采用这种方式,两种冲突场景各自是怎么处理的。
(1)远程仓库和本地仓库的冲突
在这种场景下,可以这么做吗?
显然,不行。因为远程仓库那边,没有人会给你处理冲突。所以远程仓库对于这种方式,是直接拒绝的,只能采用第二种了。
(2)本地分支之间的冲突
远程仓库不允许,本地分支却可以,因为都是在我们本地,程序员可以处理冲突。
一般对于本地分支的冲突,我们也是这么做的。master分支把develop分支merge过来,处理完冲突后,develop分支再把master分支merge回来,这样俩分支都是最新版本了。当然如果develop分支不需要了,你直接删了也可以。
第二种方式:B先拉取A的代码,在本地处理冲突后,再把代码提交给A,这样A和B都是最新版本了。
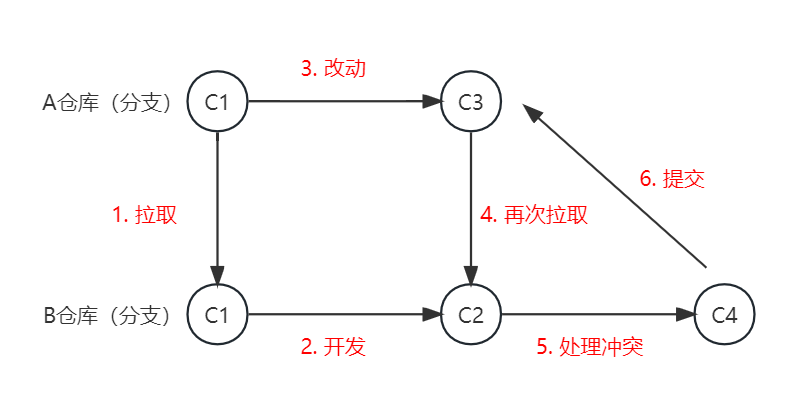
我们再来看一下采用这种方式,两种冲突场景各自是怎么处理的。
(1)远程仓库和本地仓库的冲突
对于本地和远程仓库的冲突,我们一般就是这么做的。
从逻辑上讲,既然你不敢接受我的推送,是因为我不是在你的基础上修改的。那好,我提交前先拉取你的代码,主动和你拉齐,现在你的代码我都有,我就是在你的基础上修改的了,你现在可以放心的接受我的推送了吧。
(2)本地分支之间的冲突
对于分支,我们也可以按照这个思路。先在develop上执行merge master,处理完冲突后,再切换到master,执行merge develop。这样,同样俩分支都成了最新版本。是不是发现比第一种方式更简单?
最后总结一下:
1、本地仓库和远程仓库的冲突:
(1)git pull。没有冲突最好,有冲突处理冲突。
(2)git add -A
(3)git commit -m
(4)git push
后三步和平时提交代码一个样。所以,提交代码前先pull,是一个很有必要的好习惯。
2、本地master分支和develop分支的冲突:
(1)git switch develop。切换到develop分支。
(1)git merge master。把master分支合并过来,没有冲突最好,有冲突处理冲突。
(2)git switch master。切换回master分支。
(3)git merge develop。把develop分支合并过来。

