聊聊微服务治理体系
你的微服务项目真的支持集群部署吗?真的做到业务解耦了吗?我相信现在大一点的项目,基本都会选择微服务,但是,真的能体现微服务核心价值的项目不多。在我上篇文章《聊聊微服务架构思想》中,基于个人认知,讲述了软件架构的发展历程和微服务核心思想,主要阐述了微服务架构要解决的痛点和使用微服务带来的好处。凡事都有两面性,微服务在解决痛点和带来便利的同时,也有自身的一些痛点和弊端。微服务能受大家热捧,不仅仅是分而治之的思想有多先进,主要是因为他有一套完善的服务治理体系,能解决了微服务自身的带来的弊端。这篇文章主要分析微服务带来的痛点和微服务架构是如何解决痛点的。
写在篇头
读到我文章的朋友,如果你是着急查找料,找具体的解决方案,可能会让你失望,本编文章不讲纯技术。我的文章可能更多是聊思想、方法论,帮助你构建认知体系,适合想转架构、转产品的开发者潜心阅读。技术可以不深挖,但一定揭开神秘的技术面纱,了解解决问题的本质(方法论和底层原理),当你掌握了背后的逻辑,就是掌握了其精华或者说是产品的灵魂,掌握了灵魂(思想),躯壳都不是最重要了,因为躯壳自己都能造。
单机部署→集群部署
传统的项目都是单体服务,大多数也局限于单机部署。其实单体服务集群部署的方案很简单,首先,服务部署在多台电脑上,或者不同容器上,然后用nginx做反向代理和负载均衡,最后前端直接通过nginx调用服务。这样就实现了集群部署。
那么,集群这么容易,为什么传统项目很少用集群部署,等到微服务才开始流行集群部署呢?(注:为什么用集群请看上篇文章,这篇文章主要说集群部署要解决的问题)。
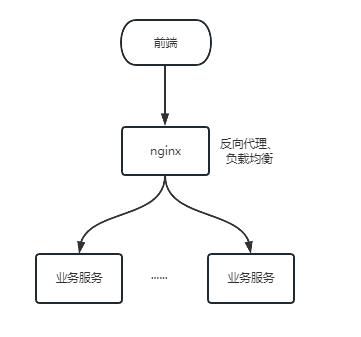
单体服务部署集群的九个统一。
- 上下文统一
传统项目都是通过session获取前后端对话信息,即用户登录了,后端会在session里存储当前登录用户状态信息,该在访问接口的时候,从session中获取到他的权限信息,进行接口鉴权等操作。如果集群部署,部署了两台,用户登录时,会将登录状态存储到发起登录的服务上,而再次发起请求时,如果负载转发到另一台服务上,将获取不到登录状态。微服务解决方案:使用无状态登录,后端不再使用session,前端登录时,将用户登录状态信息通过加密算法生成token,token可以携带更多的信息写入redis,当用户再次访问时,通过解析token验证用户登录信息,同时从redis获取用户更多的信息,做鉴权等处理。这样做,前端只要用token,就可以访问任一集群上节点服务。其实,在传统的项目中也可以用token的方式依赖nginx搭建双节点,而微服务框架中,网关做了路由分发、负载均衡、授权鉴权等功能,开箱即用。路由分发和负载均衡,其实就是nginx一样的功能,当网关所有的请求来,根据访问的地址,将请求转发到对应的服务,如果有大量的请求,会根据轮询分发到各个节点上。授权便是登录的时候,验证用户账号密码信息,严重通过下发token,前端获取token后,再次访问待着token,网关检验token是否有效,同时根据token获取用户接口权限,做鉴权拦截。 - 缓存统一
在我们项目中,通常都会有这样一些热点数据,访问很频繁,但变动极少。比如用户信息,权限信息,商品信息等,为了提升系统性能,减轻DB压力,我们通常都会把这类信息放在缓存中。如果使用的是本地缓存,在集群部署模式下,就会出现缓存失效。除非达到所有节点都有缓存,推荐的方式是用分布式缓存框架。可以选择redis做缓存数据库,不论是不是微服务项目吧,要搭建集群,就要考虑是否有本地缓存,有很多缓存框架,比如Spring Caching基本都是支持分布式缓存,即用redis做缓存数据库。 - 数据统一
数据统一,这个话题比较泛,要看具体的应用场景,我这在说个简单常见的场景。业务编码的生成,要求不能重复且序号不间断,常见的做法是,从数据库取到最大的编码序号,然后序号加1,生成新的编码。如果在集群模式下,并发请求时,这种处理方式就很容易生成重复的编码。解决方案基本有2种,第1种是通过数据库表锁,在查询最大编码的时候将表上锁,直到新的编码生成并存入,再释放锁,当然不推荐这种做法,很容易出现死锁问题且性能极差。第2种方式是通过redis分布式锁实现。总结,有数据竞争的,不能本地处理,可以借助redis处理。 - 文件统一
文件统一是很常见的一个问题,几乎每个系统都有上传下载功能,上传的时候,配置一个文件存储路劲,下载的时候,根据文件路劲,获取文件。在集群部署时,这种做法就不可行了,上传到分散的集群节点上,下载的时候,就找不到文件了。这时候就需要一个统一存储文件的服务,大厂基本都有分布式文件存储服务,比如OSS,OBS等,也可以搭建开源的文件存储服务。 - 调度统一
调度也是最常见的阻碍集群部署的一大问题。传统项目基本都会用Quartz做调度,执行批次任务。而在集群模式中,就不允许同一任务在不同机器上同时跑了,特别是统计任务,很容易出错。也许我们常用的办法是加个配置开关,只在某一台机器上开启Quartz,但这不但增加了配置文件不一致导致的运维成本,同时也不利于资源平衡计算,集群几点那么多,凭什么让一台机器负担所有的调度任务。这个问题的解决方案通常是把调度抽离出来,用分布式调度系统,任务还是负载在集群几点上处理,但是调度要从业务中分离出来,可以参考比较成熟的 xxl-job 分布式调度系统。 - 配置统一
在上边我们讲了一个最简单的双节点例子,在实际场景中,一些秒杀活动,一些大型的TOC电商项目可能同时几十万甚至上百万的并发量,服务就需要部署几白甚至上千个节点。在这样庞大集群下,就会引发一些列的运维成本。比如配置,所有集群部署的服务的配置是要一致的,当我们需要改动配置时,如果要一个个的去改,运维估计直接奔溃了,最好的方式就是配置文件只在一个地方维护,所有集群都去读取这个配置文件,在需要修改配置的时候,只需要修改这个配置文件即可。配置中心就是起到这样一个作用,在配置中心填写配置,所有集群几点的服务都去配置中心读取配置,在配置维护时,也不需要一个个节点去维护。 - 日志统一
日志统一在大规模集群也是非常重要,出了问题,需要开发定位问题,必须要看日志,大规模集群部署,日志一个个翻看就不太现实了,也是需要把所有集群节点上的日志都采集到一起,然后合并分类,方便查阅。最常用的方案是ELK日志管理系统。ELK的大概过程是,服务节点通过filebeat,周期性的把本地日志推送到LogStash进行日志收集转换,通过LogStash将日志分析转换后,存入ES,再通过Kibana从ES读取数据,并可视化查看日志,方便开发定位问题。 - 统一监控
如果是2个人干活,有偷懒的一眼就看出来了,但是有几百人干活,有浑水摸鱼的,靠人发现就很难了吧。如果真用到庞大集群,服务监控是少不了的,服务监控也主要用来监控和报警一些挂掉的或者资源不足的服务节点。 - 统一部署
同一个服务部署很多个节点,存在大量重复的工作,一个个去部署服务,显然有很多的重复工作。容器化部署时最好的选择,可以用k8s进行服务编排,自动部署,自动扩展,让大集群部署易控、低成本。
搭建集群是容易的,但可用、可控、可管理的集群服务还是有很多困难要克服。用道家先哲话,“一生二、二生三、三生万物···”,软件架构也是从单机部署到双节点热备部署,再到微服务集群应对高并发无限扩展部署,集群规模可以根据业务扩展、收缩。但前提是要能做到“九九归一”,收放自如的微服务集群,大规模集群至少要做到上边提到的9个统一,如果是小集群,至少要做到前5个统一。
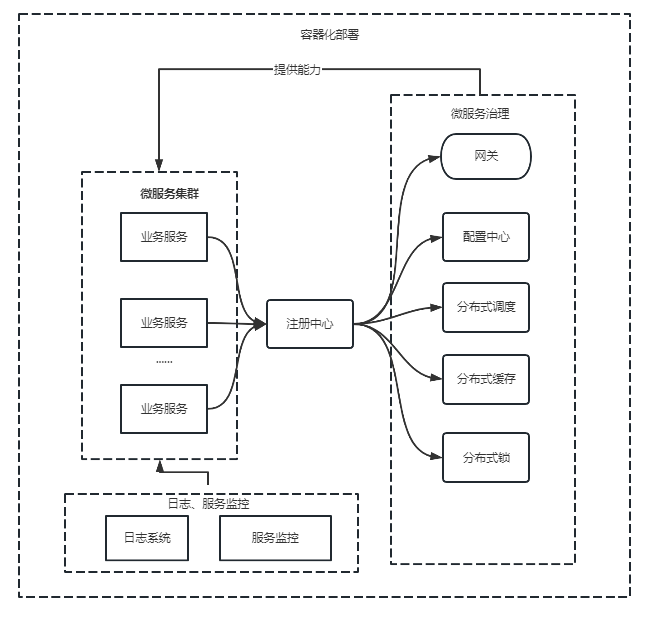
服务治理的工具有点像上篇文章提到的各个职能部门,这些职能部门就是从业务服务中心抽离出来的,更多是为了技术内聚。我经手的很多微服务项目,特别是一些数字化工厂、政务类、电力安全管控等,这些项目真正的用户比较少,并发量也比较小,不过业务功能很多,项目规模也很大,也都选用了微服务框架,进行单机部署,不需要集群,顶多双节点保证系统容错性,这类toB项目选择微服务更多是为了业务解耦,便于开发管理、功能维护和灵活交付。
微服务拆分(业务解耦)
微服务架构最关键的是微服务拆分,一旦拆分不合理,将是深不见底的坑,就得拆西墙补东墙,很难维护。我们通常习惯性的会根据功能模块拆分,其实这是不正确的,功能和功能之间一般是有依赖的,把两个互相依赖的功能拆分开,得不偿失。拆分的依据要根据拆分的目的决定,拆分的最终目的是为了易维护,易扩展。拆分的合不合理,要权衡这样拆分了是否易扩展、易维护。拆分的方式有很多种,可以根据领域建模DDD拆分,也可以根据用户群体拆分,最理想的拆分是每个服务职责单一,低依赖。本篇不讲如何拆分,主要将服务拆分后,如何补偿因拆分带来的不足。
- 数据一致性
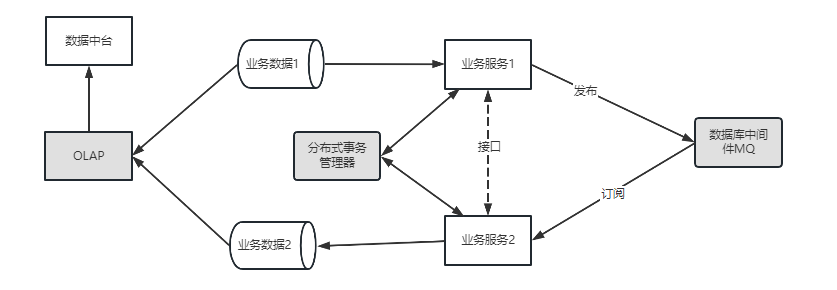
数据一致性是微服务解决的首要问题,原本是单体服务,现在要拆成多个服务,必然存在数据流转的问题。比如阿里的电商中台业务,包含 用户账号子系统、商品子系统、订单子系统、客户子系统、物流子系统 等。有新订单生成的时候,需要库存、物流、财务等多个子系统去处理订单相关的业务,为保证数据的ACID,就需要把这些操作放在一个事务中,其中一个失败,其他都失败,全部成功,才算订单生成成功。原本单体服务,用本地事务就很容易保证数据的一致性,微服务框架中,就需要分布式事务管理器去保证数据的一致性。分布式事务(Seata)就是一个很好的分布式事务解决方案,易于集成到项目中。 - 数据解耦
业务耦合的主要是数据,如果数据能够解耦,业务自然解耦,特别是流程数据。上一个服务的输出数据,可能是下一个服务的输入数据,每个服务有出有进,各自负责自己数据流程节点上的业务处理。这种数据的传递,不能依靠数据同步,两边都存数据解决。这样数据冗余严重,并且还会存在数据不一致性问题。当然也不能完全依赖于接口,接口依赖也是强依赖,存在接口版本管控、接口联调等成本。好的方案是通过数据中间件MQ解决,上一个服务将自己生产的数据发送到MQ,下一个服务去消费MQ中的数据即可,这样即使其中一个服务宕机了,也不影响其他服务的运行,更不会存在数据丢失问题等。 - 数据融合
我刚开始做微服务的时候,这个问题也困扰我很久。数据分离容易,输入融合难。很常见的一个场景是,分页关联表查询。不同数据阶段或领域的数据存在不同的数据库内,每个数据库只能被自己的服务访问,在做报表或统计功能的时候,可能需要联合多个服务的表进行关联查询。关联查询写在那个服务就头疼了。后来解决这个问题,用到一些数据库中间件,比如mycat,PrestoDB这类支持多数据源关联查询的数据库中间件。随着后来做大数据,个人认为,OLAP要跟OLTP分开,要做数据统计,数据分析,就不应该以事务数据的处理思维去考虑。可以用做数据中台,去提供各种个性化的数据需求。 - 链路追踪
微服务增加了程序的复杂度,特别是微服务调微服务,多层调用。接口报错时,要一层层的去排查,时间非常麻烦的事。链路追踪可以帮你分析调用链,可视化展示,方便排查问题。
业务拆分微服务是容易的,按自己的规则都可以拆分,但是要做好服务拆分引起的副作用才是关键。
![image]()
写在最后
其实微服务的兴起,主要是微服务框架(springcloud)有一系列解决自身架构不足的解决方案,也许微服务的思想有人提前也能想到,但是拿出来一讨论,基本会被新的方式带来的弊端给淘汰掉。做人、做事、做产品,也都一样,就像网上卖东西这件事,马云之前,就有很多电商产品,网上卖东西这并不是有多新的创意想法,但是还是被jack马把淘宝做大做强了,为什么?主要是因为他解决了电商自带弊端,在线支付、产品信任、产品物流、甚至高并发下的技术壁垒等等。
本文来自博客园,作者:·志坚行远·,转载请注明原文链接:https://www.cnblogs.com/luze/p/17275729.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号