python(北京理工大学慕课)6-7章
6.组合数据类型
6.1 集合类型及操作
6.1.1集合类型定义
集合是多个元素的无序组合
1)集合类型与数学中的集合概念一致
2)集合元素之间无序,每个元素唯一,不存在相同元素
3)集合元素不可更改,不能是可变数据类型(数值类型【int、float、bool】、字符串类型、元组)
4)集合用大括号 {} 表示,元素间用逗号分隔
5)建立集合类型用 {} 或 set()
6)建立空集合类型,必须使用set() 【{}这个符号用来建立字典类型】
6.1.1补充:可变数据类型和不可变数据类型
- 可变数据类型:当该数据类型对应的变量的值发生了变化时,如果它对应的内存地址不发生改变,那么这个数据类型就是 可变数据类型。【引用数据类型】
list(列表)、dict(字典)、set(集合,不常用)
- 不可变数据类型:当该数据类型对应的变量的值发生了变化时,如果它对应的内存地址发生了改变,那么这个数据类型就是 不可变数据类型。【数据值类型】
数值类型(int、float、bool)、string(字符串)、tuple(元组)
案例:
>>> A = {"python", 123, ("python",123)} #使用{}建立集合
{123, 'python', ('python', 123)}
>>> B = set("pypy123") #使用set()建立集合
{'1', 'p', '2', '3', 'y'}
>>> C = {"python", 123, "python",123}
{'python', 123}
6.1.2集合操作符
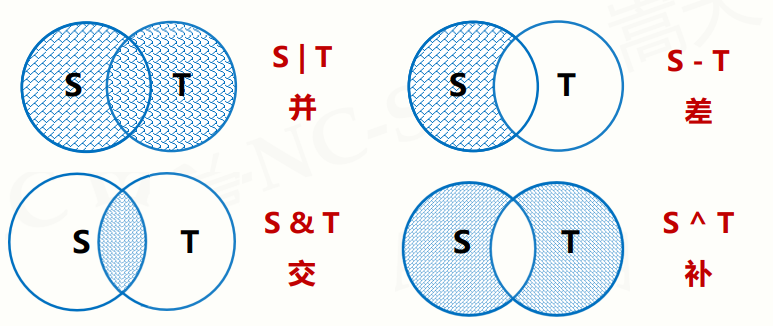
- 六个操作符
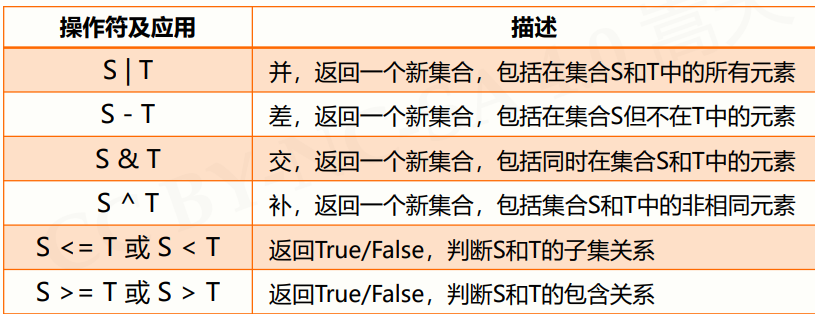
- 四个增强操作符 【更新就是覆盖了原来的值,不是追加在原来值后面】
案例:
>>> A = {"p", "y" , 123}
>>> B = set("pypy123")
>>> A-B
{123}
>>> B-A
{'3', '1', '2'}
>>> A&B
{'p', 'y'}
>>> A|B
{'1', 'p', '2', 'y', '3', 123}
>>> A^B
{'2', 123, '3', '1'}
6.1.3集合处理方法

案例:
#集合遍历 A = {"p", "y" , 123} for item in A: print(item, end="") #输出结果:p123y ,可以看出集合无序 #try - except可捕捉异常 try: while True: print(A.pop(), end="")) except: pass #输出结果:p123y ,可以看出集合无序
6.1.4集合类型应用场景
1)包含关系比较
"p" in {"p, "y" , 123} 输出:True {"p", "y"} >= {"p", "y" , 123} 输出:False
2)数据去重:集合类型所有元素无重复
ls = ["p , "p", "y", "y", 123] s = set(ls) # 利用了集合无重复元素的特点,强转set() {'p', 'y', 123} lt = list(s) # 还可以将集合转换为列表 ['p', 'y', 123]
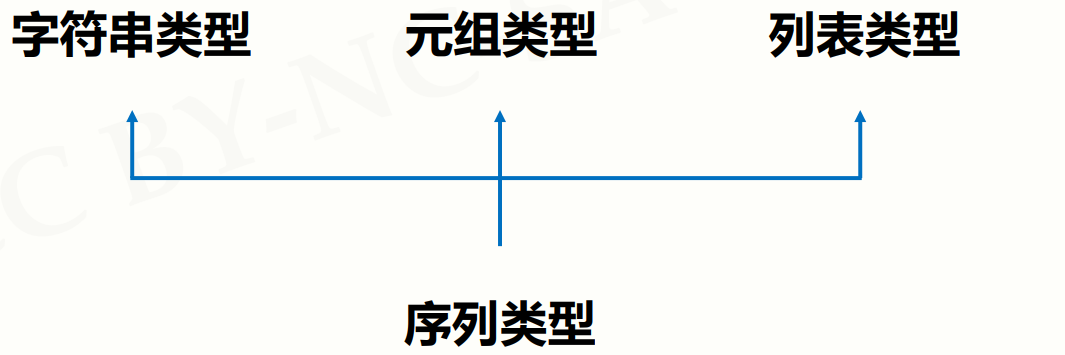
6.2 序列类型及操作
6.2.1序列类型定义
- 序列是具有先后关系的一组元素
1)序列是一维元素向量,元素类型可以不同
2)类似数学元素序列: s0, s1, … , sn-1
3)元素间由序号引导,通过下标访问序列的特定元素
- 序列是一个基类类型 【序列的一些特性,操作方法,对于序列的派生类型也适用,但是下面的派生类型也有自己定义的操作方法】
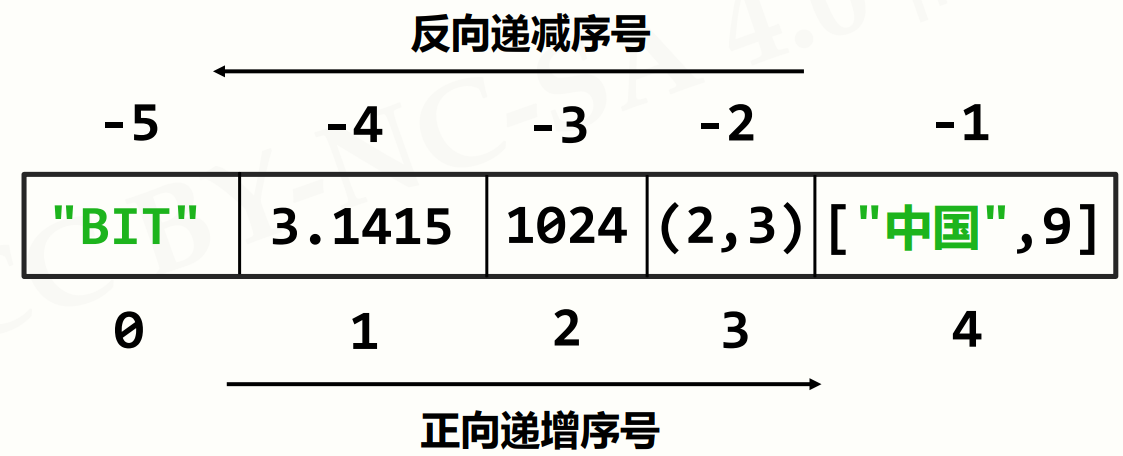
- 序号的定义
6.2.2序列处理函数及方法
- 六个操作符
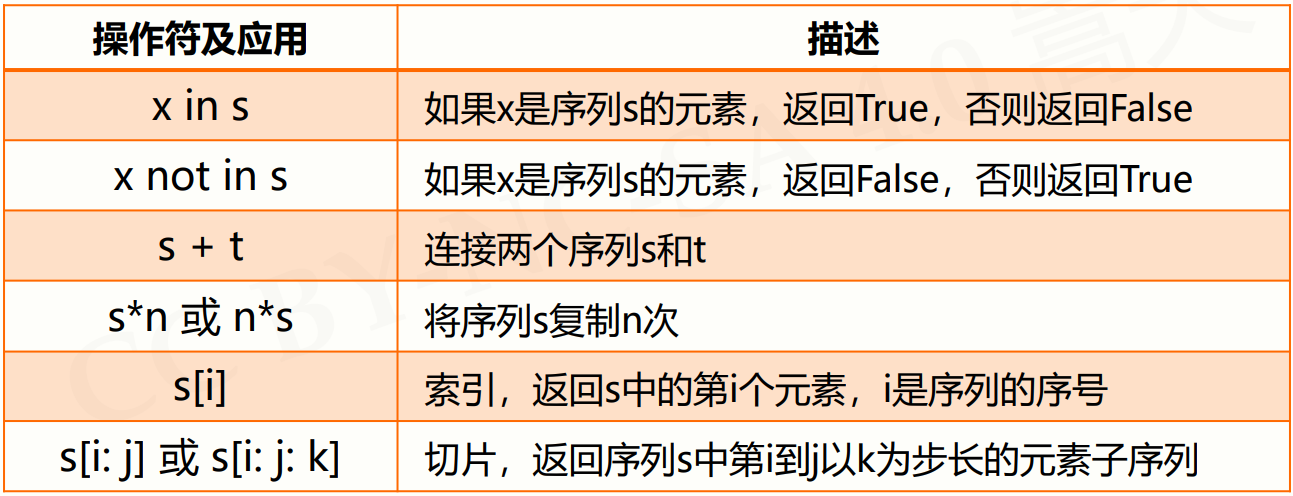
案例:
ls = ["python", 123,".io"] ls[::-1] #输出结果:['.io', 123, 'python'] s = "python123.io" s[::-1] #输出结果:'oi.321nohtyp' #字符串也具有序列类型的操作
- 5个函数和方法

案例:
ls = ["python", 123, ".io"] len(ls) #结果:3 s = "python123.io" max(s) #结果:'y'
6.2.3元组类型及操作
1)定义:元组是序列类型的一种扩展
1.元组是一种序列类型,一旦创建就不能被修改
2.使用小括号 () 或 tuple() 创建,元素间用逗号 , 分隔
3.可以使用或不使用小括号 【比如函数返回多个值时 语句“return 1,2”,默认返回值就是一个元组类型】
4. 元组继承了序列类型的全部通用操作
5.元组因为创建后不能修改,因此没有特殊操作
6.使用或不使用小括号
案例:
creature = "cat", "dog","tiger","human" creature #结果:('cat', 'dog', 'tiger', 'human') color = (0x001100, "blue", creature) color #结果:(4352, 'blue', ('cat', 'dog', 'tiger', 'human'))
creature = "cat", "dog","tiger","human" creature[::-1] ('human', 'tiger', 'dog', 'cat') color = (0x001100, "blue", creature) color[-1][2] 'tiger'
6.2.4列表类型及操作
1. 列表类型定义
列表是序列类型的一种扩展,十分常用,列表是引用类型
1)列表是一种序列类型,创建后可以随意被修改
2)使用方括号 [] 或list() 创建,元素间用逗号 , 分隔
3)列表中各元素类型可以不同,无长度限制
案例:
ls = ["cat", "dog","tiger", 1024] ls ['cat', 'dog', 'tiger', 1024] #赋值 lt = ls lt ['cat', 'dog', 'tiger', 1024] #注意:列表是引用类型,附值只是引用传递,传递地址,并没有开辟一个新的空间,新的列表
注意:方括号 [] 真正创建一个列表(开辟一个新的空间),赋值仅传递引用
2.操作函数和方法
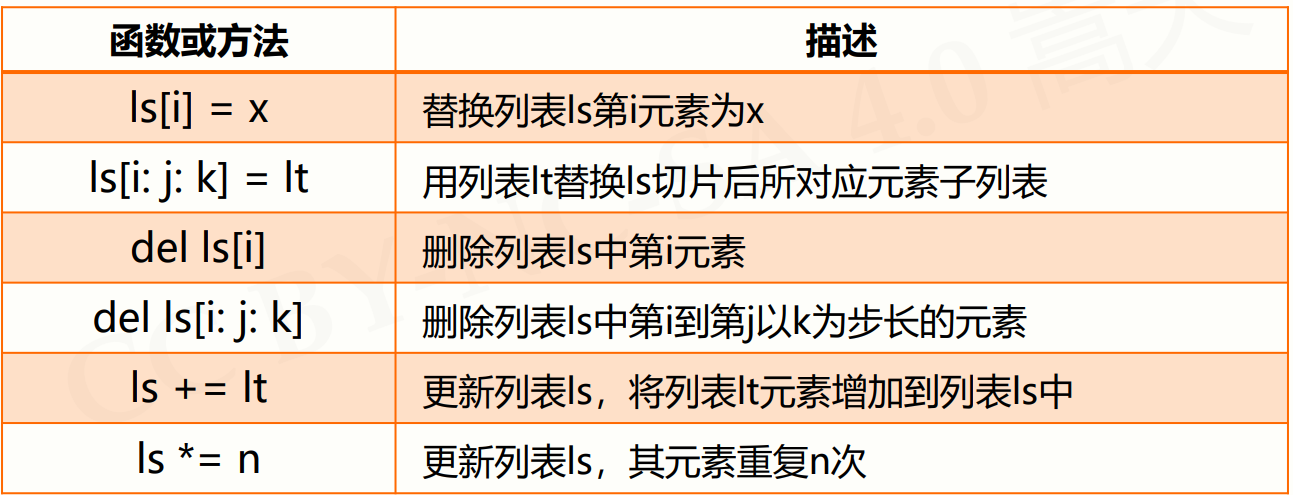
ls = ["cat", "dog","tiger", 1024] ls[1:2] = [1, 2, 3, 4] ['cat', 1, 2, 3, 4, 'tiger', 1024] del ls[::3]#步长为三 [1, 2, 4, 'tiger'] ls*2 [1, 2, 4, 'tiger', 1, 2, 4, 'tiger']
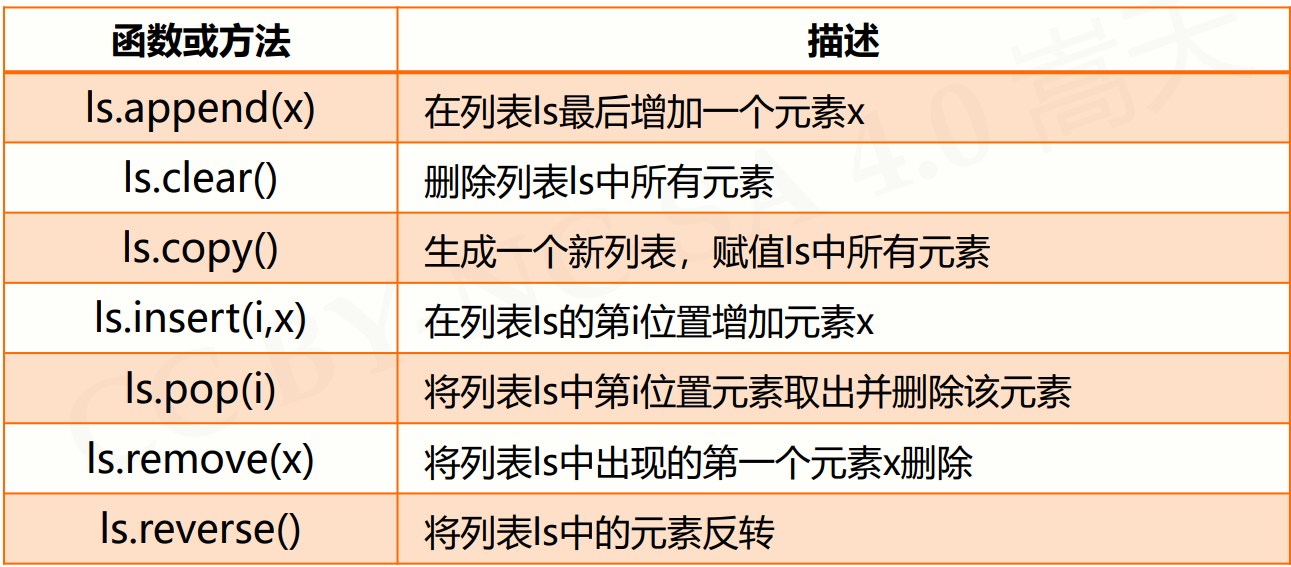
>>> ls = ["cat", "dog","tiger", 1024] >>> ls.append(1234) ['cat', 'dog', 'tiger', 1024, 1234] >>> ls.insert(3, "human") ['cat', 'dog', 'tiger', 'human', 1024, 1234] >>> ls.reverse() [1234, 1024, 'human', 'tiger', 'dog', 'cat']
6.2.5序列类型应用场景
数据表示:元组 和 列表
1)元组用于元素不改变的应用场景,更多用于固定搭配场景
2)列表更加灵活,它是最常用的序列类型
3)最主要作用:表示一组有序数据,进而操作它们
- 应用场景一

- 应用场景二 数据保护 :如果不希望数据被程序所改变,转换成元组类型,比如函数返回值

6.3 实例9: 基本统计值计算
需求:给出一组数,对它们有个概要理解
该怎么做呢? 总个数、求和、平均值、方差、中位数…
- 总个数:len()
- 求和:for … in
- 平均值:求和/总个数
- 方差: 各数据与平均数差的平方和的平均数
- 中位数:排序,然后… 奇数找中间1个,偶数找中间2个取平均
案例:
def getNum(): #获取不定长输入,没输入一个数字要回车 nums = [] strs = input("请输入数字,按enter键结束:") while strs != "": nums.append(eval(strs)) strs = input("请输入数字,按enter键结束:") return nums def meam(numStr):# 求平均数 sum = 0 for num in numStr: sum = sum + num return sum / len(numStr) def dev(numStr, mean): #计算方差 sdel = 0.0 for num in numStr: sdel = (num - mean) ** 2 +sdel return sdel / len(numStr) def median(numStr): sorted(numStr) size = len(numStr) if (size % 2 == 0): dem = (numStr[size/2-1] + numStr[size/2]) / 2 else: dem = numStr[size//2] return dem numStr = getNum() meam = meam(numStr) print("平均值:{},方差:{:.2},中位数:{}.".format(meam, dev(numStr, meam), median(numStr)))
6.4 字典类型及操作
6.4.1字典类型定义
1)字典类型的定义
- 理解“映射”
映射是一种键(索引)和值(数据)的对应

- 序列类型由0..N整数作为数据的默认索引 ,字典类型则由用户自定义索引
- 字典类型是“映射”的体现
1)键值对:键是数据索引的扩展,key-val
2)字典是键值对的集合,键值对之间无序
3)采用大括号{}和dict()创建,键值对用冒号: 表示 {<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}
2)字典类型的用法
在字典变量中,通过键获得值;[ ] 用来向字典变量中索引或增加元素
用法:
<字典变量> = {<键1>:<值1>, … , <键n>:<值n>} #定义,或者dict()
<值> = <字典变量>[<键>] #索引
<字典变量>[<键>] = <值> #增加 key-val,或者修改value
案例:
d = {"中国":"北京", "美国":"华盛顿", "法国":"巴黎"}
print(d)
{'中国': '北京', '美国': '华盛顿', '法国': '巴黎'}
d["中国"]
'北京'
de = {} ;
type(de);# 获取de的类型
<class 'dict'>
6.4.2字典处理函数及方法
pop、popitem都是返回并且删除返回的键值对
items()把每一对键值对组成一个元组类型,返回 。例如:('the', 1138)



6.4.3字典类型应用场景
- 映射的表达
映射无处不在,键值对无处不在
例如:统计数据出现的次数,数据是键,次数是值
最主要作用:表达键值对数据,进而操作它们
- 元素遍历 键就是d

6.5 模块5: jieba库的使用
6.5.1jieba库概述
jieba是优秀的中文分词第三方库
1)中文文本需要通过分词获得单个的词语
2)jieba是优秀的中文分词第三方库,需要额外安装
3)jieba库提供三种分词模式,最简单只需掌握一个函数
6.5.2jieba库的安装
(cmd命令行) pip install jieba
6.5.3jieba分词的原理
jieba分词依靠中文词库
1)利用一个中文词库,确定中文字符之间的关联概率
2)中文字符间概率大的组成词组,形成分词结果
3)除了分词,用户还可以添加自定义的词组
6.5.4jieba库使用说明
1)三种模式
- 精确模式:把文本精确的切分开,不存在冗余单词
jieba.lcut("中国是一个伟大的国家") ['中国', '是', '一个', '伟大', '的', '国家']
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
jieba.lcut("中国是一个伟大的国家",cut_all=True) ['中国', '国是', '一个', '伟大', '的', '国家']
- 搜索引擎模式:在精确模式基础上,对长词再次切分
jieba.lcut_for_search(“中华人民共和国是伟大的") ['中华', '华人', '人民', '共和', '共和国', '中华人民共 和国', '是', '伟大', '的']
2)相关函数


6.6 实例10: 文本词频统计
案例1:"Hamlet英文词频统计"实例
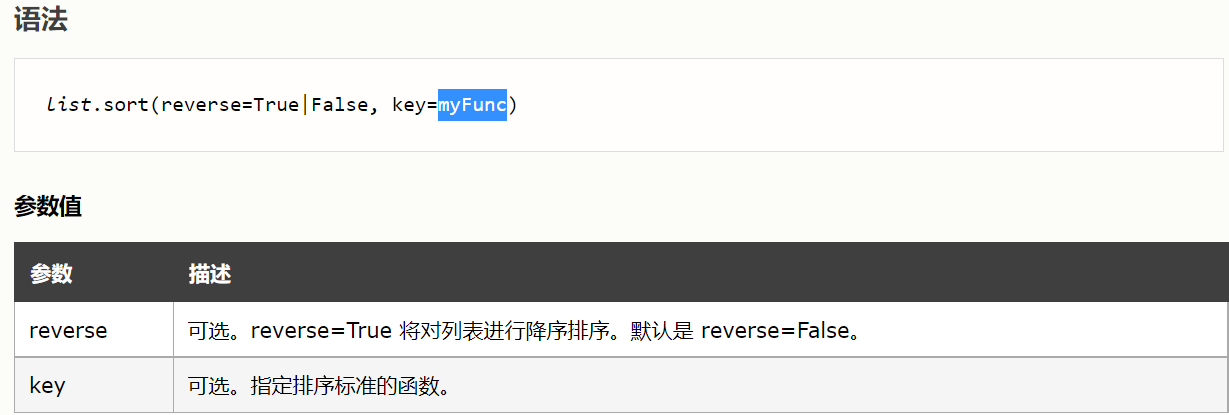
#获取文本 def getText(str): txt = open(str, "r").read() txt = txt.lower() for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~': txt = txt.replace(ch, " ") return txt hamletTxt = getText("D:\hamlet.txt") words = hamletTxt.split() #给字符串切片,返回一个列表类型,默认分隔符为“ ” counts = {} #定义一个字典类型用来统计 for word in words: counts[word] = counts.get(word,0) + 1 items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True) #降序排序 for i in range(10): word, count = items[i] print("{0:<10}{1:>5}".format(word, count))
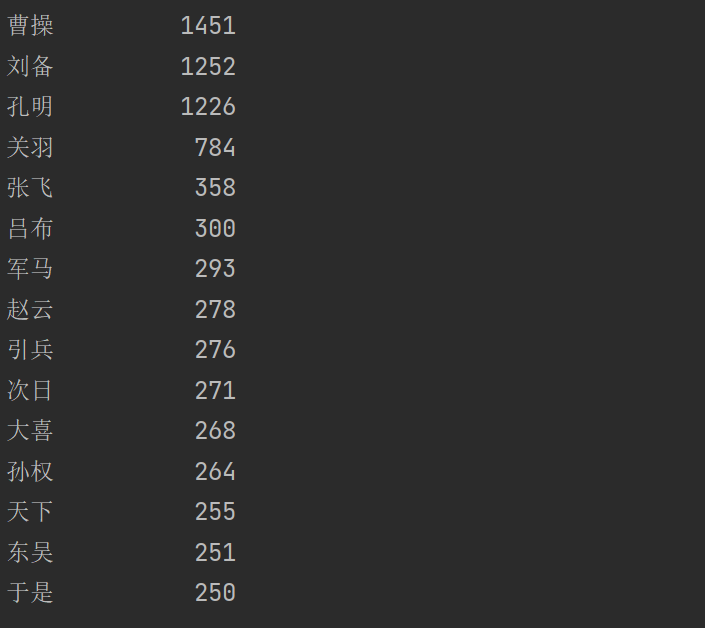
案例2:"《三国演义》人物出场统计"实例
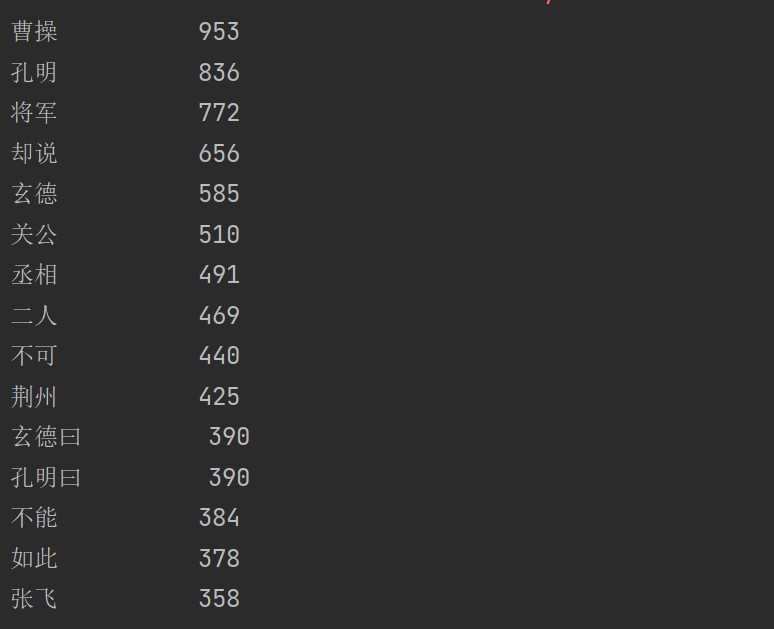
import jieba txt = open("D:\\threekingdoms.txt", "r", encoding="utf-8").read() words = jieba.lcut(txt) counts = {} for word in words: if len(word) == 1: continue else: counts[word] = counts.get(word,0) + 1 items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True) for i in range(15): word, count = items[i] print("{0:<10}{1:>5}".format(word, count))
运行结果:
改进后:
import jieba txt = open("D:\\threekingdoms.txt", "r", encoding="utf-8").read() excludes = {"将军", "却说", "荆州", "二人", "不可", "不能", "如此", "商议", "如何", "军士", "主公", "左右"} words = jieba.lcut(txt) counts = {} for word in words: if len(word) == 1: continue elif word == "孔明" or word == "孔明曰": rword = "孔明" elif word == "关公" or word == "云长": rword = "关羽" elif word == "玄德" or word == "玄德曰": rword = "刘备" elif word == "孟德" or word == "丞相": rword = "曹操" else: rword = word counts[rword] = counts.get(rword,0) + 1 for word in excludes: del counts[word] items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True) for i in range(15): word, count = items[i] print("{0:<10}{1:>5}".format(word, count))
运行结果:
7.文件和数据格式化
7.1 文件的使用
7.1.1文件的类型
1)文件的理解——文件是数据的抽象和集合
- 文件是存储在辅助存储器上的数据序列
- 文件是数据存储的一种形式
- 文件展现形态:文本文件和二进制文件
- 文本文件和二进制文件只是文件的展现方式
- 本质上,所有文件都是二进制形式存储
- 形式上,所有文件采用两种方式展示
2)文本文件
- 由单一特定编码组成的文件,如UTF-8编码
- 由于存在编码,也被看成是存储着的长字符串
- 适用于例如:.txt文件、.py文件等
3)二进制文件
- 直接由比特0和1组成,没有统一字符编码
- 一般存在二进制0和1的组织结构,即文件格式
- 适用于例如:.png文件、.avi文件等
7.1.2文件的打开和关闭
1)文件处理的步骤: 打开-操作-关闭

2)打开文件语法格式:

文件路径和名称的写法:

3)打开模式,打开模式可省略不写,如省略默认打开方式是文本形式+只读

7.1.3文件内容的读取


注意:of.read()是一次读入,统一处理。如果有参数则按数量读入,分行处理
of.readlines()这是分行读入,逐步处理、
7.1.4数据的文件写入


7.2 实例11: 自动轨迹绘制
需求:根据脚本来绘制图形?
- 不通过写代码而通过写数据绘制轨迹
- 数据脚本是自动化最重要的第一步
基本思路:
步骤1:定义数据文件格式(接口)

步骤2:编写程序,根据文件接口解析参数绘制图形
步骤3:编制数据文件
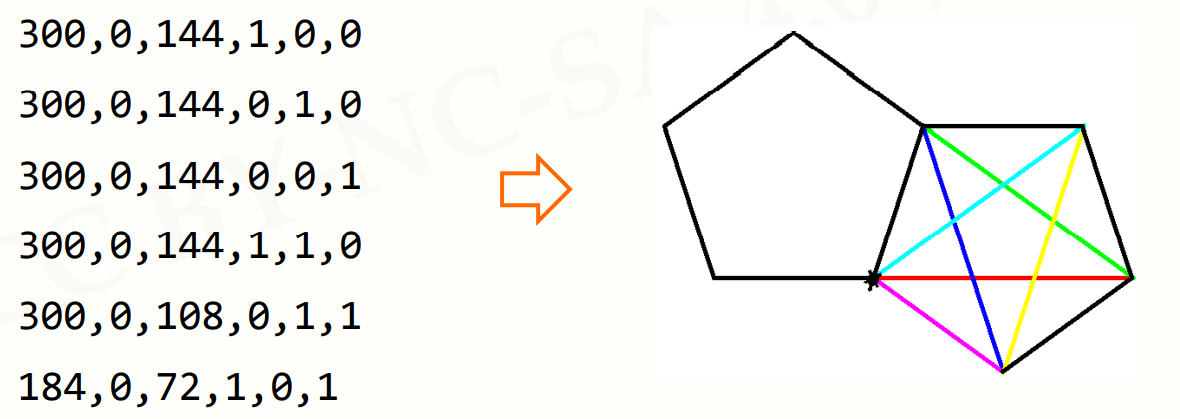
import turtle as t t.title('自动轨迹绘制') t.setup(800, 600, 0, 0) t.pencolor("red") t.pensize(5) #数据读取 datals = [] f = open("data.txt") for line in f: line = line.replace("\n","") datals.append(list(map(eval, line.split(",")))) f.close() #自动绘制 for i in range(len(datals)): t.pencolor(datals[i][3],datals[i][4],datals[i][5]) t.fd(datals[i][0]) if datals[i][1]: t.right(datals[i][2]) else: t.left(datals[i][2]) t.done()
数据文件内容:
300,0,144,1,0,0 300,0,144,0,1,0 300,0,144,0,0,1 300,0,144,1,1,0 300,0,108,0,1,1 184,0,72,1,0,1 184,0,72,0,0,0 184,0,72,0,0,0 184,0,72,0,0,0 184,1,72,1,0,1 184,1,72,0,0,0 184,1,72,0,0,0 184,1,72,0,0,0 184,1,72,0,0,0 184,1,720,0,0,0
运行结果:
7.3 一维数据的格式化和处理
7.3.1数据组织的维度
- 维度:一组数据的组织形式
- 一维数据:由对等关系的有序或无序数据构成,采用线性方式组织。 对应列表、数组和集合等概念
- 二维数据:由多个一维数据构成,是一维数据的组合形式。表格是典型的二维数据 其中,表头是二维数据的一部分
- 多维数据:由一维或二维数据在新维度上扩展形成
- 高维数据:仅利用最基本的二元关系展示数据间的复杂结构

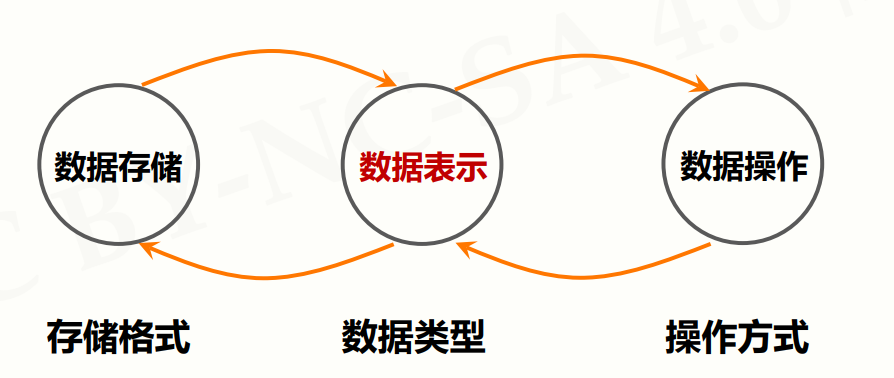
- 数据的操作周期:
存储 <-> 表示 <-> 操作
7.3.2一维数据的表示
如果数据间有序:使用列表类型
- 例如:ls = [3.1398, 3.1349, 3.1376]
- 列表类型可以表达一维有序数据
- for循环可以遍历数据,进而对每个数据进行处理
如果数据间无序:使用集合类型
- 例如:st = {3.1398, 3.1349, 3.1376}
- 集合类型可以表达一维无序数据
- for循环可以遍历数据,进而对每个数据进行处理
7.3.3一维数据的存储
存储方式一:空格分隔
- 例如:中国 美国 日本 德国 法国 英国 意大利
- 使用一个或多个空格分隔进行存储,不换行
- 缺点:数据中不能存在空格
存储方式二:逗号分隔
- 例如:中国,美国,日本,德国,法国,英国,意大利
- 使用英文半角逗号分隔数据进行存储,不换行
- 缺点:数据中不能有英文逗号
存储方式三:其他方式
- 例如:中国$美国$日本$德国$法国$英国$意大利
- 使用其他符号或符号组合分隔,建议采用特殊符号
- 缺点:需要根据数据特点定义,通用性较差
7.3.4一维数据的处理
存储 <-> 表示:
- 将存储的数据读入程序
- 将程序表示的数据写入文件
一维数据的读入处理:
从特殊符号分隔的文件中读入数据。例如:中国$美国$日本$德国$法国$英国$意大利
txt = open(fname).read()
ls = txt.split("$")
f.close()
输出:ls= ['中国', '美国', '日本', '德国 ', '法国', '英国', '意大利']
一维数据的写入处理:
采用空格分隔方式将数据写入文件
ls = ['中国','美国','日本']
f = open(fname, 'w')
f.write(' '.join(ls))
f.close()
7.4 二维数据的格式化和处理
7.4.1二维数据的表示
使用列表类型:
- 例如:使用二维列表[ [3.1398, 3.1349, 3.1376], [3.1413, 3.1404, 3.1401] ]
- 使用两层for循环遍历每个元素
- 外层列表中每个元素可以对应一行,也可以对应一列
7.4.2CSV数据存储格式
CSV: Comma-Separated Values
- 国际通用的一二维数据存储格式,一般.csv扩展名
- 每行一个一维数据,采用逗号分隔,无空行
- Excel和一般编辑软件都可以读入或另存为csv文件

注意事项:
- 如果某个元素缺失,逗号仍要保留
- 二维数据的表头可以作为数据存储,也可以另行存储
- 逗号为英文半角逗号,逗号与数据之间无额外空格
7.4.3二维数据的存储
1)按行存或者按列存都可以,具体由程序决定
2)一般索引习惯:ls[row][column],先行后列
3)根据一般习惯,外层列表每个元素是一行,按行存
7.4.4二维数据的处理
从CSV格式的文件中读入数据:
fo = open(fname)
ls = []
for line in fo:
line = line.replace("\n","")
ls.append(line.split(","))
fo.close()
将数据写入CSV格式的文件:
ls = [[], [], []] #二维列表
f = open(fname, 'w')
for item in ls:
f.write(','.join(item) + '\n')
f.close()
二维数据的逐一处理: 采用二层循环
ls = [[1,2], [3,4], [5,6]] #二维列表
for row in ls:
for column in row:
print(column)
7.5 模块6: wordcloud库的使用
7.5.1wordcloud库基本介绍
wordcloud库概述:
wordcloud是优秀的词云展示第三方库

词云以词语为基本单位,更加直观和艺术地展示文本
wordcloud库的安装:
(cmd命令行) pip install wordcloud
7.5.2wordcloud库使用说明
wordcloud库把词云当作一个WordCloud对象
- wordcloud.WordCloud()代表一个文本对应的词云
- 可以根据文本中词语出现的频率等参数绘制词云
- 词云的绘制形状、尺寸和颜色都可以设定
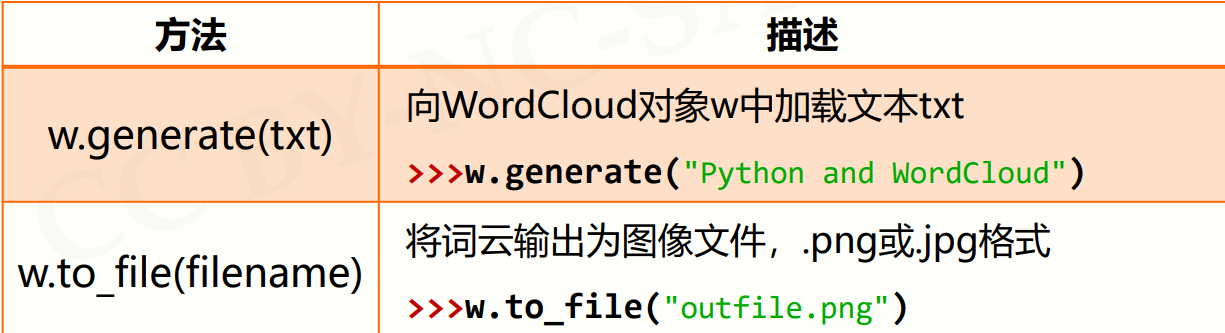
wordcloud库常规方法
- 获得WorldCloud对象:w = wordcloud.WordCloud()
- 以WordCloud对象为基础 ,配置参数、加载文本、输出文件
代码示例:
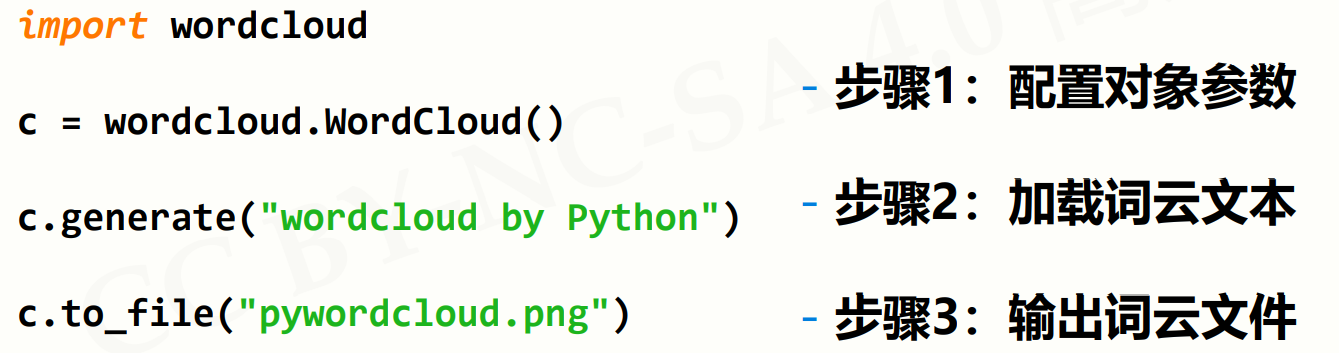
从文本到词云:

配置对象参数:
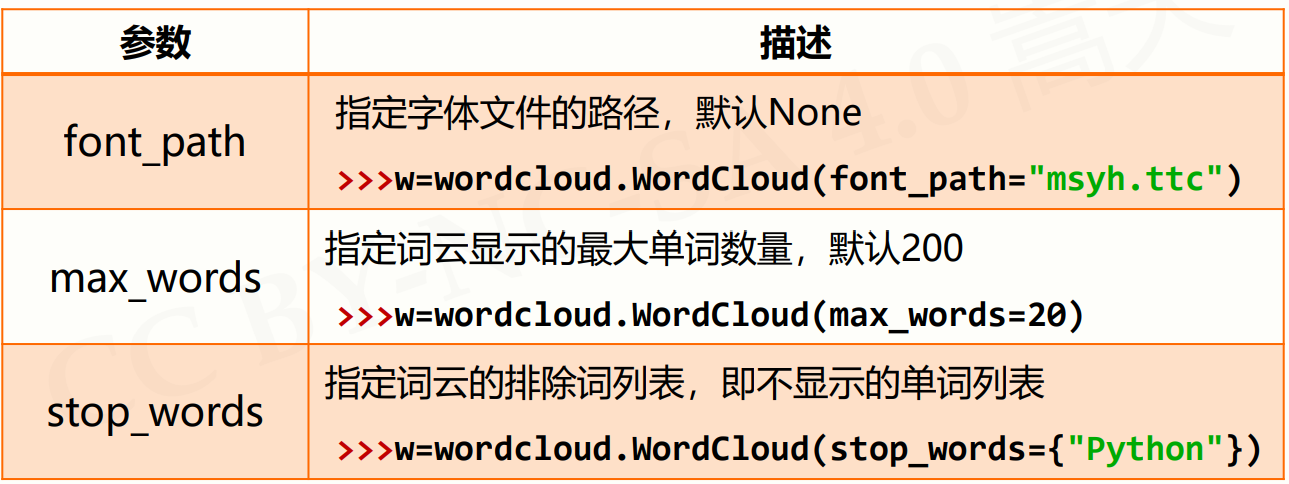
w = wordcloud.WordCloud(<参数>)



7.6 实例12: 政府工作报告词云

相关链接:https://python123.io/resources/pye/关于实施乡村振兴战略的意见.txt
https://python123.io/resources/pye/新时代中国特色社会主义.txt
基本思路:

# GovRptWordCloudv1.py import jieba import wordcloud f = open("D:\\政府工作报告.txt", "r", encoding="utf-8") t = f.read() f.close() ls = jieba.lcut(t) txt = " ".join(ls) w = wordcloud.WordCloud(font_path="msvc.ttc", width=1000, height=700, \ background_color="white", ) w.generate(txt) w.to_file("grwordcloud.png")

优化后:
import jieba import wordcloud from imageio import imread #生成特定形状的词云 mask = imread("vcc.png") #vcc.png是一只熊猫 f = open("D:\\政府工作报告.txt", "r", encoding="utf-8") t = f.read() f.close() ls = jieba.lcut(t) txt = " ".join(ls) w = wordcloud.WordCloud(font_path = "msyh.ttc",\ width = 1000, height = 700, background_color = "white", mask = mask,) w.generate(txt) w.to_file("groundcloth1.png")


 浙公网安备 33010602011771号
浙公网安备 33010602011771号