in、left、right、SUBSTRING、substring_index、数据查询、排序、聚合函数、 -第七、八次课
第七次上课
集合包含判断 in
(1)单值情况:
Where x =单值
(2)多值、集合:
where 字段名 in(集合值) --例子 select * from 学生表 where 学号='2009010103' select * from 学生表 where 学号= (select 学号 from 学生表 where 姓名='李四方') --以下用法错误 select * from 学生表 where 学号= (select 学号 from 学生表 where 姓名='李四方' or 姓名='李大方') --面对条件是集合,正确用法 select * from 学生表 where 学号 in (select 学号 from 学生表 where 姓名='李四方' or 姓名='李大方') --上句还可以简化为: select 学号 from 学生表 where 姓名 in ('李四方','李大方','杨春')
说明:关系运算> < = != 只能用于单值比较。
包含于多值时,要使用集合运算判断in
子查询 in
用于条件限制表达式,指定表达式范围值,返回 内容
查询满足=值一、值二。。。的 行
直接上例题
例:查出所有男生的选课情况及成绩,格式为:
学号 课程号 成绩
select 学号,课程号,成绩 from 成绩表 where 学号 in(select 学号 from 学生表 where 性别='男')
例:查出所有男生团员的计算机网络基础 ,计算机基础,高等数学上下的成绩情况(学号,课程号,成绩)
select * from 成绩表 where 学号 in (select 学号 from 学生表 where 性别='男' and 团员否=1) and 课程号 in(select 课程号 from 课程表 where 名称 in('计算机网络基础','计算机基础','高等数学上','高等数学下'))
left、right、SUBSTRING、substring_index用法:
1、left(name,4)截取左边的4个字符
列:
SELECT LEFT(201809,4) 年
结果:2018
2、right(name,2)截取右边的2个字符
SELECT RIGHT(201809,2) 月份
结果:09
3、SUBSTRING(name,5,3) 截取name这个字段 从第五个字符开始 只截取之后的3个字符
SELECT SUBSTRING('成都融资事业部',5,3)
结果:事业部
4、SUBSTRING(name,3) 截取name这个字段 从第三个字符开始,之后的所有个字符
SELECT SUBSTRING('成都融资事业部',3)
结果:融资事业部
5、SUBSTRING(name, -4) 截取name这个字段的第 4 个字符位置(倒数)开始取,直到结束
SELECT SUBSTRING('成都融资事业部',-4)
结果:资事业部
6、SUBSTRING(name, -4,2) 截取name这个字段的第 4 个字符位置(倒数)开始取,只截取之后的2个字符
SELECT SUBSTRING('成都融资事业部',-4,2)
结果:资事
注意:我们注意到在函数 substring(str,pos, len)中, pos 可以是负值,但 len 不能取负值。
7、substring_index('www.baidu.com', '.', 2) 截取第二个 '.' 之前的所有字符
SELECT substring_index('www.baidu.com', '.', 2)
数据查询-like、[]、_、%:
1)字符串匹配 like
%代表任意多个字符(包括0-n个)
_ 必须只能代表一个任意字符
如:张_ 可代表张三,张六(两个字)
张% 可代表:张 张三 张三四(以要以张字开头即可)
[ ] 在其中只能选一个字符去匹配
[^字符] 不在其中选一个字符
例: 查出学生表中所有姓杨,张,李的人,有如下办法
Select * from 学生表 where left(姓名,1)=’杨’ or left(姓名,1)=’张’ or left(姓名,1)=’李’ Select * from 学生表 where left(姓名,1) in(’杨’,’张’,’李’) Select * from 学生表 where left(姓名,1) like '[杨张李]' Select * from 学生表 where 姓名 like '[杨张李]%' Select * from 学生表 where substring(姓名,1,1) like '[杨张李]'
例:上例中求反操作
Select * from 学生表 where 姓名 like '[^杨张李]%'
注意:如果查询时,% 或_ 本身就是被查询的内容,如何处理?
例:要从表中查出某说明列中含有“50%”字样的串
Select * from xx where 列名 like ’50%’ (不对)
Select * from xx where 列名 like ’%50!%%’ escape ’!’
说明:第1个%和第3个%是匹配任意字符串,第2个!%表示此%不是匹配意义,escape ’!’ 说明!后面这个字符不是匹配意义(类似于早期C语言中的\转意
例:有产品表,有列产品编号,现要查出编号中含有 no_2字样的所有产品
Select * from 产品表 where 编号 like ’%no!_2%’ escape ’!’
例:select * from 学生表 where 姓名 like '李_'
排序-desc、asc、order by、with ties、top n、NEWID() :
默认为升序asc , 也可以人为指定为降序desc
select 学号,姓名,年龄 from 学生表 where 性别='男' order by 年龄 desc
如果是计算结果排序呢?
select 学号,姓名,YEAR(getdate())-YEAR(生日) from 学生表 where 性别='男' order by 3 desc
注意:order by 依据可以是列名,也可是列序号(如3表示按第3列排序)
select 学号,姓名,YEAR(getdate())-YEAR(生日) as 年龄 from 学生表 where 性别='男' order by 年龄 desc
(注意:本处的年龄不是表中的原属性年龄,是查询结构别名年龄
(查询结果如果直接来自物理表的列名,查询结果列名同物理表列名)
多列参与排序:
如:先按科室把所有员工分成类,同科室的人连续位置排列,在同科室内部再按补贴多高到低排序。
Select * from 补贴表 order by 科室 ASC, 补贴 desc
一个desc只管自己的列,本处科室是升序,补贴是降序
例:把学生表所有人按性别分类,同类性别内按身高降序,如果性别和身高再相同,则进一步按年龄升序(年龄以生日为准)
select 学号,姓名,性别,身高 ,生日
from 学生表 order by 性别,身高 desc,生日 desc
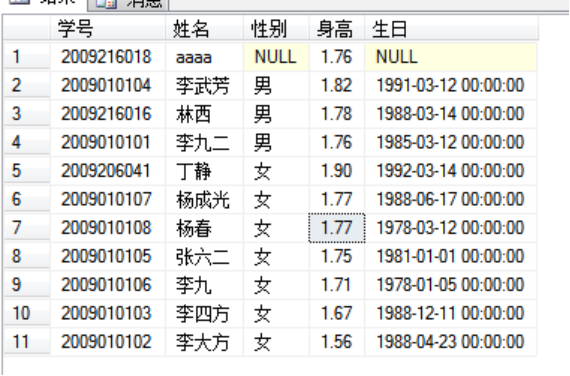
注:数值直接比较大小,汉字按拼音,日期是今天比昨天大,逻辑值true>false
注:多关键参与排序时,第一个主关键字,后面第二,三关键字. 从左向右,先满足左边的关键字排序,在值重复情况下才再按右边关键字排序.
如何从排序结果里面取前面一部分元组行呢?
Top n , top n percent
取前n个, 取前n%
select top 5 学号,姓名,性别,身高 ,生日 from 学生表 order by 身高 desc 取出身高前五名
再例:要取出年龄较小的前30%的人呢?
select top 30 percent 学号,姓名,性别,身高 ,生日 from 学生表 order by 生日 desc
如果刚好第4和5名身高的同学身高值相同,都是1.77,咋取??
select top 4 with ties 学号,姓名,性别,身高 ,生日 from 学生表 order by 身高 desc
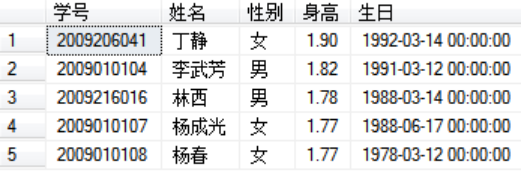
如果不加with ties,则取不到杨春
不加with ties则只会取 身高相同的 排在前面的第一 的人那一行,加上with ties 则 对于最后一个数据,身高相同的都能取到
例:随机挑选四个记录出来
select top 4 学号,姓名,身高 from 学生表 order by NEWID()
第八次课
聚合函数的运用:
函数在sqlserver中,分:系统函数(可 new(), sin(x),getdate() ), 聚合函数(专用于表的统计工作),自定义函数
其中自定义函数又分:标值函数(返回的结果一个标量值,如学号,身高这些单一值),表值函数(返回一堆数据,以视图表的形式返回)
1 count( )统计表中元组个数
select COUNT(性别) from 学生表
select COUNT(姓名) from 学生表
select COUNT(*) from 学生表 //常用的
可见,空值当空气,啥也不参与。空值不是空格!
例:统计表中的女生比男生多几个人?
select (select COUNT(*) from 学生表 where 性别='女')
-(select COUNT(*) from 学生表 where 性别='男')
例: 根据成绩表统计出有几门课有学生选
select COUNT(distinct 课程号) from 成绩表
补:哪些课程有人选? 列出课程名
select 名称 from 课程表 where 课程号 in (select distinct 课程号 from 成绩表)
2 sum( ) avg( )
纵向对数值型列求和,平均
select SUM(成绩) from 成绩表 where 课程号='101'
select SUM(学号) from 成绩表 where 课程号='101' 错
select AVG(成绩) from 成绩表 where 课程号='102'
select AVG(成绩) from 成绩表 where 课程号='109'
没有109课程,结果为null,实际上是总和/数据个数,0/0 严格说要溢出,sqlserver做了溢出容错处理的.
一次性分组统计出两门课的平均成绩:
select 课程号, AVG(成绩) as 科平均 from 成绩表
where 课程号 in('102','105')
group by 课程号
等效写法:
select AVG(成绩) as 科平均 from 成绩表
where 课程号 in('102','105' )
select sum (成绩)/COUNT(*) as 科平均 from 成绩表
where 课程号 in('102','105' )
例;有结构:成绩表(学号,语文,数学,英语,总分,平均分)
根据三科成绩,计算出所有学生的总分,和平均分,不能使用sum,average,因为这个玩意是纵向操作。本题是要求横向计算
方法1:结果不填写表里
Select 学号,语文,数学,英语, 语文+数学+英语 as 总分,总分/3 as 平均分 from 成绩表
方法2:结果填表
Update 成绩表 set 总分 =语文+数学+英语,平均分 = 总分/3
3 max( ) min( ) 常用于对数值,日期列求大值,小值
select MAX(成绩)-MIN(成绩) from 成绩表 where 课程号='101'
select MAX(生日) from 学生表 求年龄最小值(生日最大值)
select MAX(姓名) from 学生表
也可以,可见姓名汉字按拼音排序的.
例:一次性求出101课程的最高,最低,平均,总分,选课人数
select MAX(成绩) as 最高分,MIN(成绩) 最低分,
avg(成绩) as 平均分 ,sum(成绩) as 科总分,
count(*) as 选课人数 from 成绩表 where 课程号='101'
说明:类似以上返回一堆数据,可以事先定义表值函数。
三 group by 分组及统计应用
分组一般结合统计聚会函数一起使用
例:统计出表各性别的人数
select 性别, COUNT(*) from 学生表 where 性别='男'
错:多了性别。因为这种统计结果是一个单一的数值,与哪一个人无关,所以不能引用查询非统计外的其它列.再如:统计全班的人数,这个人数值与哪一个具体的学生是无关,所以:
Select 姓名,count(*) from 学生表 也是错的
select COUNT(*) from 学生表 where 性别='女' 这个是对的
但下面这样是对的:
select 性别, COUNT(*) from 学生表 where 性别='男' group by 性别

统计各性别人数正确做法,是按性别先分组,再统计每组的人数.此时的统计结果与性别值有关
select 性别, COUNT(*) as 人数 from 学生表 group by 性别
例:统计出成绩表中各课程的选课人数,科平均分
select 课程号,COUNT(*) as 选课人数,AVG(成绩) as 科平均 from 成绩表 group by 课程号
再例:求每个人的选课数和所选课的平均分:
select 学号,COUNT(*) as 选课门数,AVG(成绩)
as 人平均 from 成绩表
group by 学号
例:按科室汇总补贴:
Select 科室号,sum(补贴) as 科室总 from xxxx
Group by 科室号
结果:
科室号,科室总
1 45434
2 3432
3 43322
再打印详细明细表:
Select 姓名,科室号,补贴 order by 科室号 asc
例:统计出成绩表中,每个姓李的学生的选课情况;包括学号,科目数,总分,平均分,要求只列出选课数目大于等于6的人情况, 最后结果按科目数降排
select 学号,COUNT(*) as 科目数,SUM(成绩) as 总分,
AVG(成绩) as 平均分
from 成绩表 where 学号 in
(select 学号 from 学生表 where 姓名 like '李%')
group by 学号 having count(*)>=6 order by 2
仔细体会上面各子句的顺序,不能随意
例:求出杨春的计算机应用基础课程的成绩值。
select *from 课程表
select 成绩 from 成绩表 where 学号=
(select 学号 from 学生表 where 姓名='杨春')
and 课程号 in
(select 课程号 from 课程表 where 名称='计算机网络基础')
例:求出大学英语所有学生的总分和平均值,选课人数
select COUNT(*) as 人数, SUM(成绩) as 总分 ,AVG(成绩) as 科平均 from 成绩表
where 课程号= (select 课程号 from 课程表 where 名称='大学英语')
例题:体验临时变量
declare @nl1 int,@nl2 int ,@nlc int
declare @re nchar(20)
select @nl1=YEAR(GETDATE())-YEAR(出生日期) from 学生表 where 姓名='李九二'
select @nl2=YEAR(GETDATE())-YEAR(出生日期) from 学生表 where 姓名='李大方'
set @nlc=@nl1-@nl2//两人相差多少岁
if(@nlc>0)
begin
set @re='李九二比李四方大'+CONVERT(nchar(2), @nlc)+'岁'
end
else
begin
set @re='李四方比李九二大'+CONVERT(nchar(2),0-@nlc)+'岁'
end
print @re
