【扩展】浅浅的理解——雪花算法,全局唯一的ID
最近,学习Mybatis-Plus,其中注解TableId 使用的是雪花算法,似乎是为了解决分布式分表的问题。以我目前的项目经历,项目的使用人数还没有大到使用分布式。而且,即是用到,我也只需要知其然,不用知其所以然。不过可以作为扩展知识,了解一下。
背景
随着数据量的规模增大,数据库表示压力很大。在一张数据规模庞大数据库中一条记录,犹如在熙熙攘攘的人群中找寻自己心爱自然人;在一张数据规模庞大的数量中插入一条记录,犹如在拥挤的人群中,完成一场马拉松;在一张数据规模庞大的数据库中删除一条记录,犹如在人山人海中,寻找丢失的物品。所以,数据库规模越大,处理数据耗时越大。
当数据十分庞大时,你以为它能刹那见完成。结果,它完成的时间,比你的人生还长。
所以,我们需要为数据库解决问题。将庞大的数据分到其他表去——这就是分表;整个数据库不够存储这些数据了,那就分到其他数据库,其他服务器上去——这就是分布式。
适用场景
在分布式环境下生成唯一ID,用于分布式算法。
特性
全局唯一
原理
分表
分表的分类
分表氛围垂直分表和水平分表。
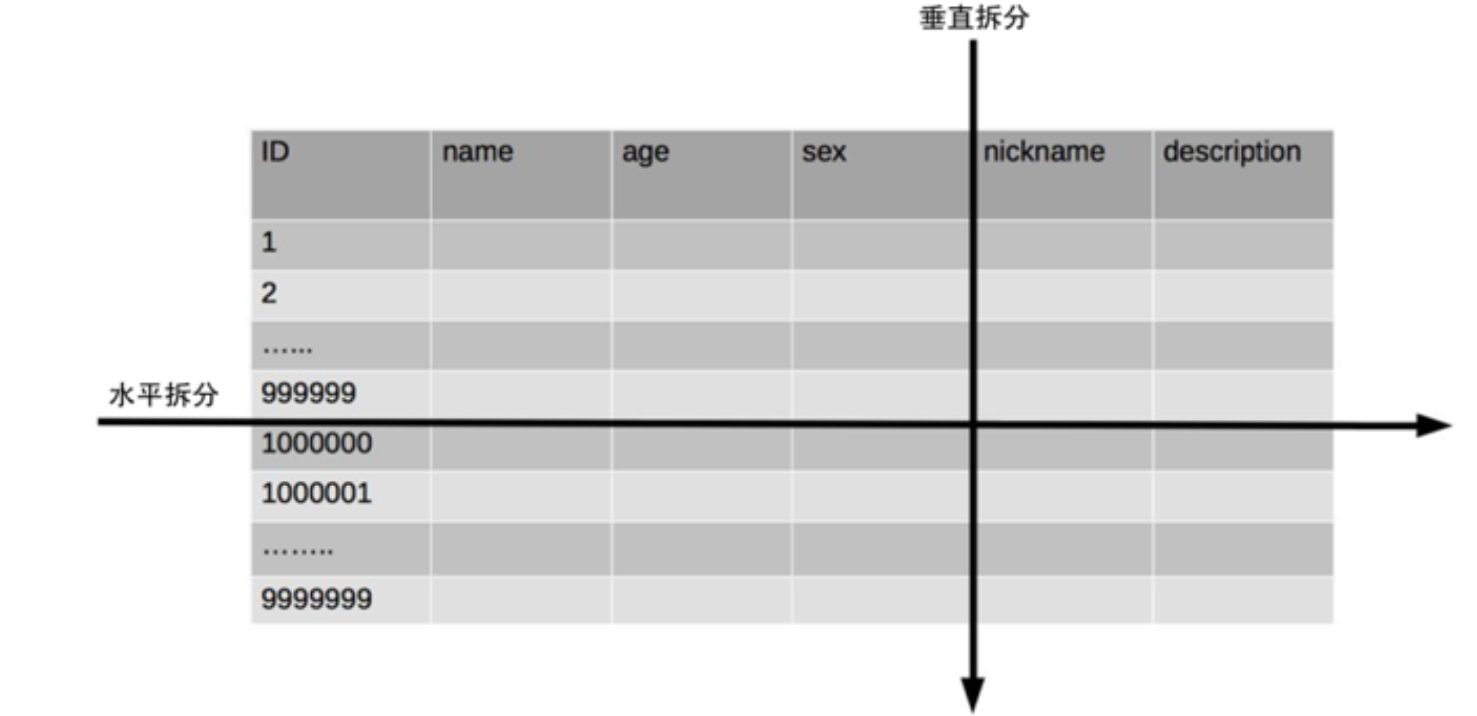
显而易见,垂直分表,将表中不常用,大量占用字段的列拆分到另一张表中,比如个人信息的详细信息描述、个人照片(如果用二进制存的话),存放在另一张表。
水平分表,当表的数据量足够大(例如有公司要求当章表超过5000万时必须分表,数据量仅供参考)时,额外用相同字段表保存在另一张表中。
我们在建表的时候,需要保证关键字唯一性,各个分表的关键字也需要保证唯一性。
其实,雪花算法解决的是分布式环境中,水平id唯一性问题。
常见算法,优缺点比较
似乎,我们常见的设计ID自增能不能完成似乎也能完成分表。思考这个问题的人,当然比我们香的更高、更远。接下来,我们说两种更早想到的分表方法:主键自增和取模(这里关键字为Id)。
|
|
主键自增 |
取模 |
|
定义 |
根据id的值分在不同的表中。例如,分段范围为100000,则第一张表存放id为1~999999,第二张表存放id为100000~1999999,以此类推 |
根据id取余,放在不同的表中。以用户ID为例,加入我们一开始规划了10个数据库表,可以简单地用user_id%10表示数据所述的数据库表编号,ID为985的用户放在编号为5的子表中,ID为10086的用户放到编号为6的子表中。 |
|
难点 |
分段大小的选取。分段太小会导致切分后子表数量过多,增加维护难度;分段太大可能会导致单表依然存在性能问。一般建议分段大小在100万·至2000万之间,具体根据业务选取合适的分段大小。 |
初始数量的确定。表数量太多,维护比较麻烦,表数量太少又可能导致表性能存在问题。 |
|
优点 |
可以随着数据的增加平滑的扩充新的表。例如,现在有用户100万,如果增加到100万只需要增加新的表就可以了,原有的数据不需要动 |
表分布比较均匀。 |
|
缺点 |
分布不均匀。加入按照1000万来进行分布,有可能某个分段实际存储的数量只有1条,而另一个分段实际存储的数量有1000万条。 |
扩充新的表很麻烦,所有数据都要重分布。 |
雪花算法
雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同表的主键的不重复性,以及相同表的主键的有序性。
核心思想
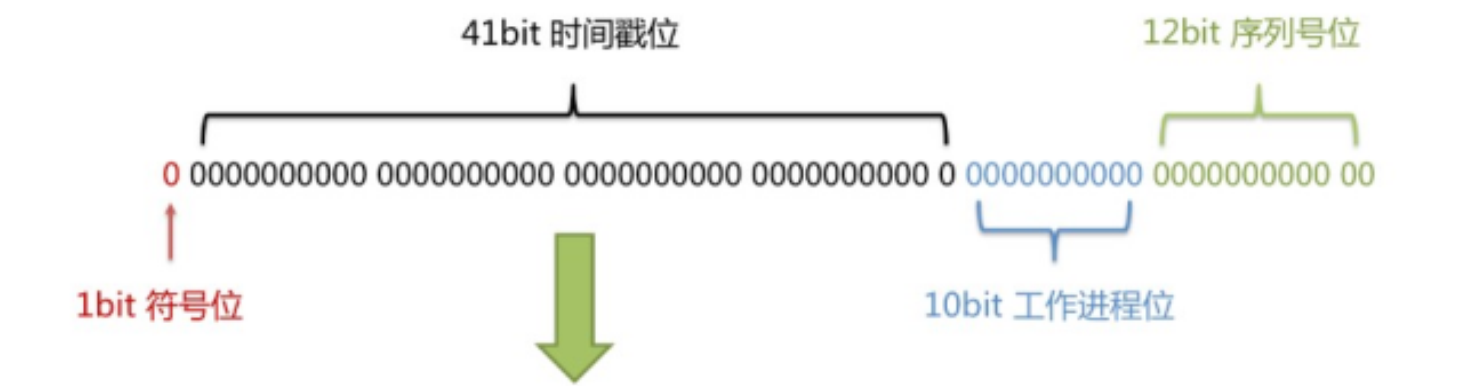
- 长度共64bit(一个long型)。
- 首先是一个符号位,1bit标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0。
- 41bit时间截(毫秒级),存储的是时间截的差值(当前时间截 - 开始时间截),结果约等于69.73年。
- 10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID,可以部署在1024个节点)。
- 12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID)。
优点
整体上按照时间自增排序,并且整个分布式系统不会产生ID碰撞,并且效率较高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号