爬虫与Python:(三)基本库的使用——6.XPath——XML中查找信息的语言
Path是一门在XML文档中查信息的语言,XPath可用来XML文档中对元素和属性进行遍历。XPath是W3C XSLT 标准的主元素,并且XQuery和Xpointer都构建于XPath表达上。XPath在Python的爬虫学习中,起着举足轻重的作用,对比正则表达式re,两者可以完成同样的工作,实现功能页类似,但XPath比re具有明显的优势。
XPath,全称 XML Path Language, 是一种小型语言查询语言,有一下优点:
- 可在XML中查找信息。
- 支持HTML查找
- 可通过元素和属性进行导航。
Python开发使用XPath条件:由于XPath属于lxml库。Inc,需要先安装lxml库,安装步骤请参考:https://www.cnblogs.com/luyj00436/p/15415280.html 。
输入安装的pip命令为:
pip install lxml
本文的主要内容包括:
1. XPath的使用方法
下面介绍一下XPaht的基础语法知识,常见的使用方法主要有以下几种:
- // (双斜杠):定位根节点,会对全文进行扫描,在文档中选取所有符合条件的内容,以列表的形式返回。
- /(单斜杆) : 寻找当前标签路径的下一层路径标签或对当前路径标签内容进行操作。
- /text() :获取当前路径下的文本内容。
- /@xxxx : 获取当前路径下标签的属性值。
- |(可选符) : 使用“|”可选取若干路径,如//p | div,即当前路径下选取的所有符合条件的P标签和div标签。
- .(点):用来选取当前节点。
- ..(双点):选取当前节点的父节点。
2. 利用示例讲解XPath的使用
以下是一段HTML代码:
1 <div> 2 <ul> 3 <li class="item-0"><a href="www.baidu.com"></a></li> 4 <li class="item-1"><a href="https://www.cnblogs.com/luyj00436">myblog</a></li> 5 <li class="item-2"><a href="https://www.csdn.net/">csdn</a></li> 6 <li class="item-3"><a href="https://www.hao123.com/">hao123</a></li>
显然,这段HTML代码没有闭合,因此可以使用lxml中的etree模块进行补全,示例代码入如下:
1 from lxml import etree 2 3 text = ''' 4 <div> 5 <ul> 6 <li class="item-0"><a href="www.baidu.com"></a></li> 7 <li class="item-1"><a href="https://www.cnblogs.com/luyj00436">myblog</a></li> 8 <li class="item-2"><a href="https://www.csdn.net/">csdn</a></li> 9 <li class="item-3"><a href="https://www.hao123.com/">hao123</a></li> 10 ''' 11 html = etree.HTML(text) 12 result = etree.tostring(html) 13 print(result.decode("UTF-8"))
运行后控制台会输出:
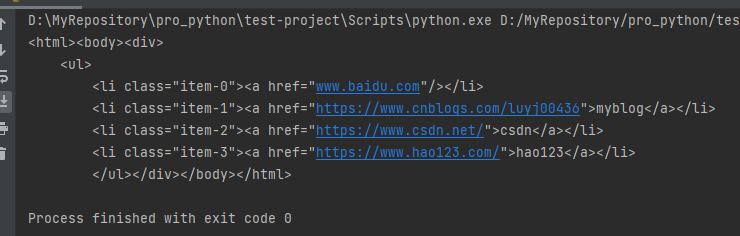
可以看到,etree不仅闭合了节点,还添加了其他需要的标签。除了直接读取文本进行解析外,etree还可以读取文件进行解析,示例代码如下:
1 from lxml import etree 2 3 html = etree.parse('./test.html',etree.HTMLParser()) 4 result = etree.tostring(html) 5 print(result.decode("UTF-8"))
3. 获取所有节点
根据XPath常用规则可知,通过“//”可以查找当前节点的子孙节点,以上面的HTML为例获取所有的节点,示例代码如下:
1 from lxml import etree 2 3 html = etree.parse('./test.html',etree.HTMLParser()) 4 result = html.xpath('//*') # 表示获取当前节点的子孙的节点,*表示所有节点, 5 # //* 表示获取当前节点下的所有节点 6 for item in result: 7 print(item)
注:如果不是获取所有节点而是指定获取某个节点,只需要将“*”改为指定节点名称即可,如获取所有的节点。这个HTMLdiam可以直接放在代码变量中,也可以放在文件中,效果一致。
4. 获取子节点
根据XPath的常用规则可知,通过“/”或“//”可以获取子孙结点或子节点。
“//”表示选择的所有节点,‘/’表示选择的直接节点。
示例代码如下:
1 from lxml import etree 2 3 html = etree.parse('./test.html',etree.HTMLParser()) 4 result = html.xpath('//ul//a') # 先选择所有ul节点,再选择ul节点下的所有a节点。包含元素。 5 result = html.xpath('//ul/a') # 先选择所有ul节点,再选择ul节点下的直接子节点a,不包含元素 6 result = html.xpath('//li/a') # 先选择所有li节点,再选择ul节点下的直接子节点a,包含元素
5. 获取文本信息
大多数时候,找到指定节点都是要获取节点的文本信息。这里使用text()方法获取节点的文本。获取所有的a标签文本信息,示例代码如下。
1 from lxml import etree 2 3 html = etree.parse('./test.html',etree.HTMLParser()) 4 result = html.xpath('//ul//a/text()') 5 print(result)
有兴趣可以去W3School官网查看XPath教程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号