爬虫与Python:(一)网络爬虫概念篇——3.爬虫的基本结构和工作流程
基本结构
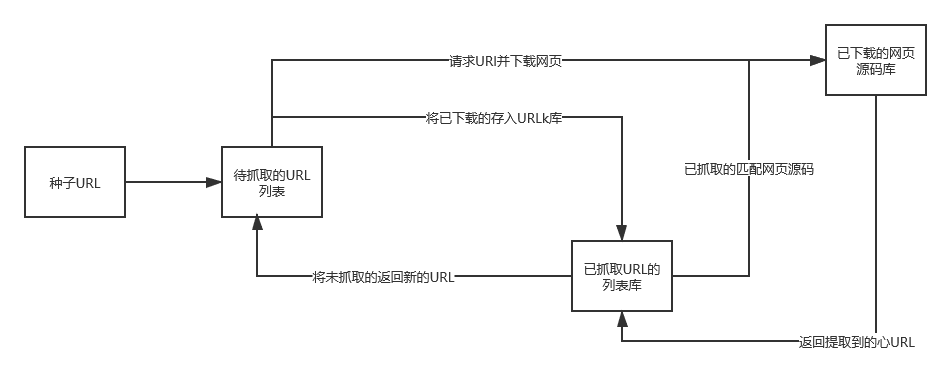
网络爬虫是搜索引擎抓取系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地形成一个互联网内容的镜像备份。通用的爬虫基本结构如下图所示。
工作流程
爬虫的基本工作流程如下:
- 选取一些种子URL 。例如某地区的新闻列表1~10页的URL。
- 将这些URL放入待抓取的URL列表中。
- 提取网页源码。依次从待抓取的URL列表中取出URL进行解析,得到网页源码,并下载存储到已下载网页源码库中,同时将已抓取过的URL放进URL列表中。
- 依次循环抓URL和提取网页源码。分析已抓取URL列表对应的网页源码,从中按照一定的需求或规则,提取出新URL放入待抓取的URL列表,这样依次循环,直到待抓取URL列表中的URL抓取完为止。例如,新闻列表每页每条新闻标题详情URL。
有志者,事竟成,破釜沉舟,百二秦关终属楚; 苦心人,天不负,卧薪尝胆,三千越甲可吞吴。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号