Hadoop组件---HDFS&Yarn&MapReduce
一. HDFS
1. namenode作用
元数据信息存储

2. datanode作用


3. 文件副本机制

4. 机架感知


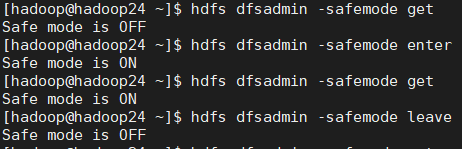
5. 命令操作
DEMO

1 import org.apache.commons.io.IOUtils; 2 import org.apache.hadoop.conf.Configuration; 3 import org.apache.hadoop.fs.*; 4 import org.junit.Test; 5 6 import java.io.File; 7 import java.io.FileOutputStream; 8 import java.io.IOException; 9 import java.net.URI; 10 11 public class HadoopTestDemo { 12 13 // 连接hadoop获取filesystem的四种方式 14 @Test 15 public void getFileSystem1() throws IOException { 16 Configuration configuration = new Configuration(); 17 configuration.set("fs.defaultFS", "hdfs://192.168.217.4:8020/"); 18 configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem"); 19 FileSystem fileSystem = FileSystem.get(configuration); 20 System.out.println(fileSystem.toString()); 21 } 22 23 @Test 24 public void getFileSystem2() throws Exception { 25 FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.217.4:8020"), new Configuration()); 26 System.out.println(fileSystem.toString()); 27 } 28 29 @Test 30 public void getFileSystem3() throws IOException { 31 Configuration configuration = new Configuration(); 32 configuration.set("fs.defaultFS", "hdfs://192.168.217.4:8020/"); 33 configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem"); 34 FileSystem fileSystem = FileSystem.newInstance(configuration); 35 System.out.println(fileSystem.toString()); 36 } 37 38 @Test 39 public void getFileSystem4() throws Exception { 40 FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://192.168.217.4:8020"), new Configuration()); 41 System.out.println(fileSystem.toString()); 42 } 43 44 // 遍历HDFS中所有文件 45 @Test 46 public void listMyFiles() throws Exception { 47 FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://192.168.217.4:8020"), new Configuration()); 48 RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fileSystem.listFiles(new Path("/"), true); 49 while (locatedFileStatusRemoteIterator.hasNext()) { 50 LocatedFileStatus next = locatedFileStatusRemoteIterator.next(); 51 System.out.println(next.getPath().toString()); 52 } 53 fileSystem.close(); 54 } 55 56 // HDFS上创建文件夹 57 @Test 58 public void mkdirs() throws Exception { 59 FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://192.168.217.4:8020"), new Configuration()); 60 boolean mkdirs = fileSystem.mkdirs(new Path("/hello/mydir/test")); 61 System.out.println(mkdirs); 62 fileSystem.close(); 63 } 64 65 // 下载文件 66 @Test 67 public void downloadFile() throws Exception { 68 FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://192.168.217.4:8020"), new Configuration()); 69 FSDataInputStream inputStream = fileSystem.open(new Path("/test/a.txt")); 70 FileOutputStream fileOutputStream = new FileOutputStream(new File("./a.txt")); 71 IOUtils.copy(inputStream, fileOutputStream); 72 IOUtils.closeQuietly(inputStream); 73 IOUtils.closeQuietly(fileOutputStream); 74 System.out.println("end"); 75 fileSystem.close(); 76 } 77 78 // 文件上传 79 @Test 80 public void uploadFile() throws Exception { 81 FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://192.168.217.4:8020"), new Configuration()); 82 fileSystem.copyFromLocalFile(new Path("./delubi.jpg"), new Path("/test")); 83 fileSystem.close(); 84 } 85 86 // 小文件合并 87 @Test 88 public void mergeFile() throws Exception { 89 FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://192.168.217.4:8020"), new Configuration()); 90 FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("/test/lucian.txt")); 91 LocalFileSystem local = FileSystem.getLocal(new Configuration()); 92 FileStatus[] fileStatuses = local.listStatus(new Path("./input")); 93 for (FileStatus fileStatus : fileStatuses) { 94 FSDataInputStream inputStream = local.open(fileStatus.getPath()); 95 IOUtils.copy(inputStream, fsDataOutputStream); 96 IOUtils.closeQuietly(inputStream); 97 } 98 IOUtils.closeQuietly(fsDataOutputStream); 99 local.close(); 100 fileSystem.close(); 101 } 102 103 }
二. MapReduce
1.基本使用
WordCountMapper.java
1 package com.luyizhou.mapreduce; 2 3 import org.apache.hadoop.io.LongWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Mapper; 6 7 import java.io.IOException; 8 9 /* 10 四个泛型 11 */ 12 public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> { 13 14 // map方法就是将k1/v1转为k2,v2 15 // k1 偏移量,v1 每一行的文本数据 16 // context 上下文对象 17 @Override 18 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 19 Text text = new Text(); 20 LongWritable longWritable = new LongWritable(); 21 // 1.将一行的文本数据拆分 22 String[] split = value.toString().split(","); 23 // 2.遍历数组,组装k2,v2 24 for (String word : split) { 25 // 3.将k2,v2写入上下文 26 text.set(word); 27 longWritable.set(1); 28 context.write(text, longWritable); 29 } 30 31 } 32 }
WordCountReducer.java
1 package com.luyizhou.mapreduce; 2 3 import org.apache.hadoop.io.LongWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Reducer; 6 7 import java.io.IOException; 8 9 public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> { 10 11 /* 12 * 将新的k2,v2转为k3,v3,并写入上下文 13 * key:新k2 14 * values:集合,新v2 15 * context:表示上下文对象 16 * */ 17 @Override 18 protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { 19 long count = 0; 20 //1.遍历集合,将集合中的数字相加,得到v3 21 for (LongWritable value : values) { 22 count += value.get(); 23 } 24 //2.将k3和v3写入上下文 25 context.write(key, new LongWritable(count)); 26 } 27 }
JobMain.java
1 package com.luyizhou.mapreduce; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.conf.Configured; 5 import org.apache.hadoop.fs.FileSystem; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 11 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 12 import org.apache.hadoop.util.Tool; 13 import org.apache.hadoop.util.ToolRunner; 14 15 import java.net.URI; 16 17 18 public class JobMain extends Configured implements Tool { 19 20 // 该方法用于指定一个Job任务 21 @Override 22 public int run(String[] strings) throws Exception { 23 // 1.创建一个job任务对象 24 Job job = Job.getInstance(super.getConf(), "wordcountOfluyizhou"); 25 job.setJarByClass(JobMain.class); // 必须添加,否则打包jar报错,跟版本有关 26 // 2.配置job任务对象, 八个步骤 27 28 // map阶段 29 // 第一步:指定文件的读取路径和读取方式 30 job.setInputFormatClass(TextInputFormat.class); 31 TextInputFormat.addInputPath(job, new Path("hdfs://192.168.217.4:8020/wordcount")); 32 // 本地模式 33 // TextInputFormat.addInputPath(job, new Path("file:///F:\\tmp\\input")); 34 // 第二步:指定map阶段的处理方式 35 job.setMapperClass(WordCountMapper.class); 36 job.setMapOutputKeyClass(Text.class); 37 job.setMapOutputValueClass(LongWritable.class); 38 39 // shuffle阶段 40 // 第三、四、五、六步:采用默认方式,暂时不做处理 41 42 // reduce阶段 43 // 第七步:指定reduce阶段处理方式和数据类型 44 job.setReducerClass(WordCountReducer.class); 45 job.setOutputKeyClass(Text.class); 46 job.setOutputValueClass(LongWritable.class); 47 // 第八步:设置输出类型和输出路径 48 job.setOutputFormatClass(TextOutputFormat.class); 49 Path path = new Path("hdfs://192.168.217.4:8020/wordcount_out"); 50 TextOutputFormat.setOutputPath(job, path); 51 52 // 本地模式运行 53 // TextOutputFormat.setOutputPath(job, new Path("file:///F:\\tmp\\output")); 54 55 // 获取filesystem,判断目录是否存在 56 FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.217.4:8020"), new Configuration()); 57 boolean exists = fileSystem.exists(path); 58 if (exists) { 59 // 删除目录 60 fileSystem.delete(path, true); 61 } 62 63 // 等待任务结束 64 boolean b = job.waitForCompletion(true); 65 return b ? 0:1; 66 } 67 68 public static void main(String[] args) throws Exception { 69 Configuration configuration = new Configuration(); 70 // 启动job任务 71 int run = ToolRunner.run(configuration, new JobMain(), args); 72 System.exit(run); 73 } 74 }
2. 分区
com.luyizhou.partition.PartitionMapper
1 package com.luyizhou.partition; 2 3 import org.apache.hadoop.io.LongWritable; 4 import org.apache.hadoop.io.NullWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Counter; 7 import org.apache.hadoop.mapreduce.Mapper; 8 9 import java.io.IOException; 10 11 /* 12 * k1 行偏移量 13 * v1 行文本数据 14 * k2 一整行文本数据 15 * v2 占位符 16 * */ 17 public class PartitionMapper extends Mapper<LongWritable, Text, Text, NullWritable> { 18 19 // map方法将k1,v1 转为k2,v2 20 @Override 21 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 22 // 方式一,定义计数器 23 Counter counter = context.getCounter("MR_COUNTER", "partition_counter"); 24 // 每次执行改方法,计数器数据加1 25 counter.increment(1L); 26 27 context.write(value, NullWritable.get()); 28 } 29 }
com.luyizhou.partition.PartitionReducer
1 package com.luyizhou.partition; 2 3 import org.apache.hadoop.io.NullWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Reducer; 6 7 import java.io.IOException; 8 9 /* 10 * k2 Text 一行文本数据 11 * V2 NullWritable 12 * k3 text 一行文本数据 13 * v2 NullWritable 14 * */ 15 public class PartitionReducer extends Reducer<Text, NullWritable, Text, NullWritable> { 16 17 public static enum Counter{ 18 MY_INPUT_RECORDS, MY_INPUT_BYTES 19 } 20 21 @Override 22 protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { 23 24 // 方式二:使用枚举来定义计数器 25 context.getCounter(Counter.MY_INPUT_RECORDS).increment(1L); 26 27 context.write(key, NullWritable.get()); 28 } 29 }
com.luyizhou.partition.MyPartition
1 package com.luyizhou.partition; 2 3 import org.apache.hadoop.io.NullWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Partitioner; 6 7 8 public class MyPartition extends Partitioner<Text, NullWritable> { 9 10 /* 11 * 定义分区规则 12 * 返回对应的分区编号 13 * 14 * */ 15 @Override 16 public int getPartition(Text text, NullWritable nullWritable, int i) { 17 // 1.拆分行文本数据(k2),获取中间字段值 18 String[] split = text.toString().split("\t"); 19 String numStr = split[5]; 20 // 2.判断中将字段的值和15的关系,返回对应的分区编号 21 if (Integer.parseInt(numStr) > 15) { 22 return 1; 23 } else { 24 return 0; 25 } 26 } 27 }
com.luyizhou.partition.JobMain
1 package com.luyizhou.partition; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.conf.Configured; 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.NullWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Job; 9 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 10 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 11 import org.apache.hadoop.util.Tool; 12 import org.apache.hadoop.util.ToolRunner; 13 14 public class JobMain extends Configured implements Tool { 15 16 @Override 17 public int run(String[] strings) throws Exception { 18 Job job = Job.getInstance(super.getConf(), "partition_mapreduce"); 19 job.setJarByClass(JobMain.class); 20 21 // map 22 job.setInputFormatClass(TextInputFormat.class); 23 TextInputFormat.addInputPath(job, new Path("hdfs://192.168.217.4:8020/input")); 24 job.setMapperClass(PartitionMapper.class); 25 job.setMapOutputKeyClass(Text.class); 26 job.setMapOutputValueClass(NullWritable.class); 27 28 // shuffle 29 // 分区 30 job.setPartitionerClass(MyPartition.class); 31 // 排序,规约,分组 32 33 // reduce 34 job.setReducerClass(PartitionReducer.class); 35 job.setOutputKeyClass(Text.class); 36 job.setOutputValueClass(NullWritable.class); 37 job.setNumReduceTasks(2); 38 39 job.setOutputFormatClass(TextOutputFormat.class); 40 TextOutputFormat.setOutputPath(job, new Path("hdfs://192.168.217.4:8020/output/partition_out")); 41 42 boolean b = job.waitForCompletion(true); 43 44 return b ? 0:1; 45 } 46 47 public static void main(String[] args) throws Exception { 48 Configuration configuration = new Configuration(); 49 int run = ToolRunner.run(configuration, new JobMain(), args); 50 System.exit(run); 51 } 52 }
3. 排序&序列化
4. 规约
理解:规约就是提前进行局部汇总,本质上属于reduce的一部分,减少网络IO次数,提高性能



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· Open-Sora 2.0 重磅开源!