循环神经网络---LSTM模型
补充:
常见的激活函数:https://blog.csdn.net/tyhj_sf/article/details/79932893
常见的损失函数:https://blog.csdn.net/github_38140310/article/details/85061849
一、LSTM原理
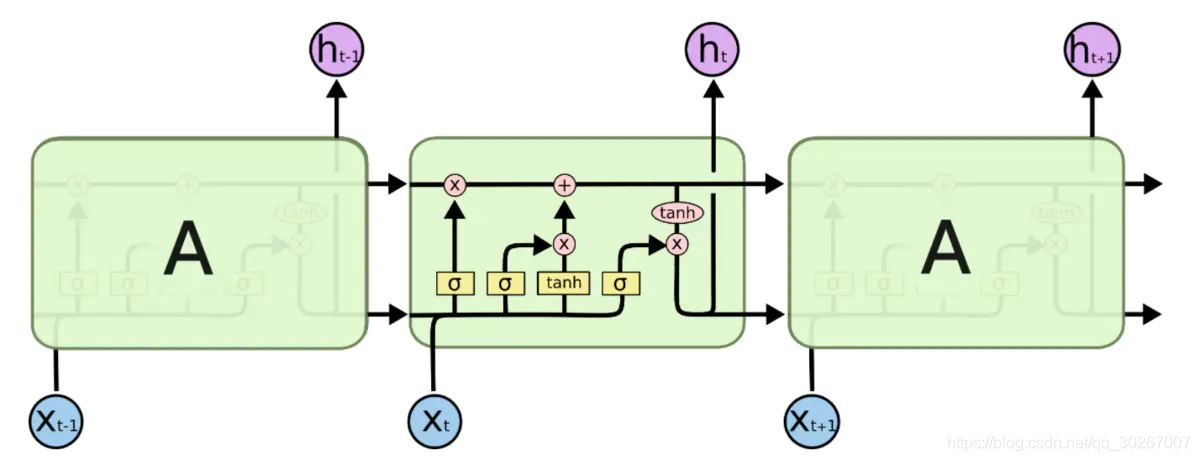
拆分理解:
如果不加门结构的话,细胞的状态类似于输送带,细胞的状态在整个链上运行,只有一些小的线性操作作用其上,信息很容易保持不变的流过整个链。
门(Gate)是一种可选地让信息通过的方式。 它由一个Sigmoid神经网络层和一个点乘法运算组成。简单理解就是对数据进行一下运算,看结果情况对运算的信息是否进行处理。Sigmoid神经网络层输出0和1之间的数字,这个数字描述每个组件有多少信息可以通过, 0表示不通过任何信息,1表示全部通过。LSTM有三个门,用于保护和控制细胞的状态。
1、忘记门
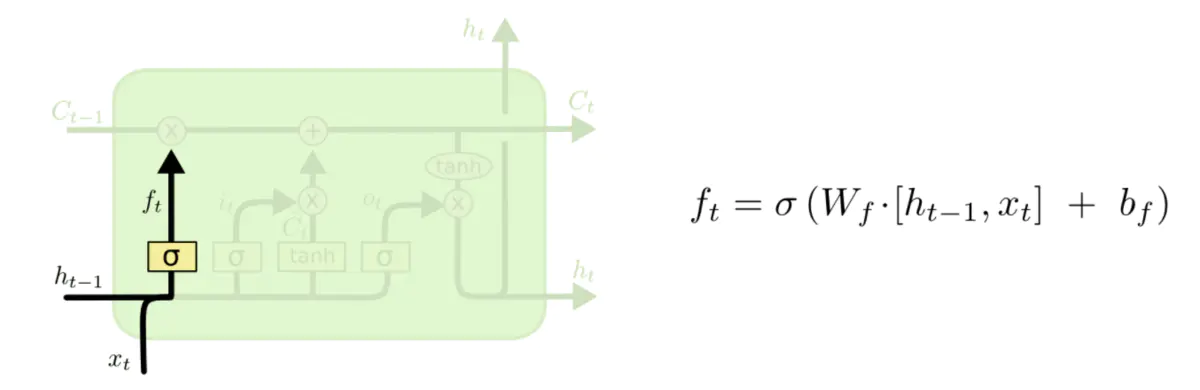
2、输入门
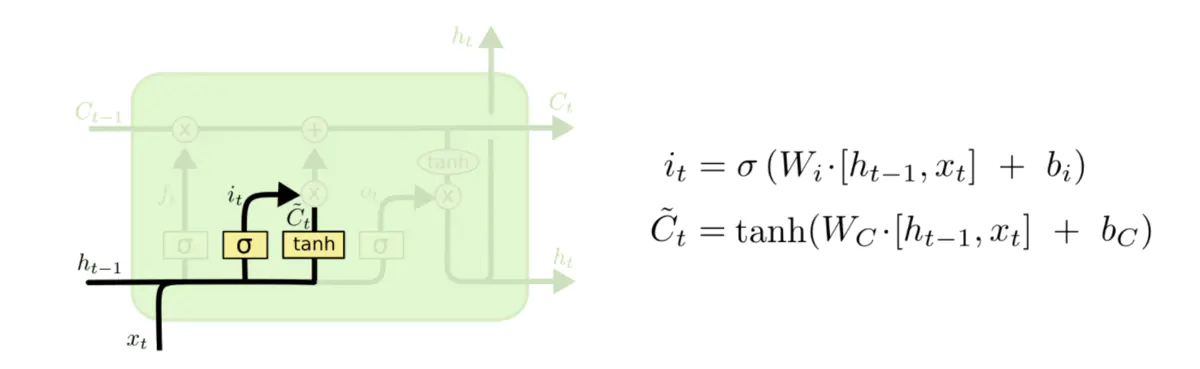
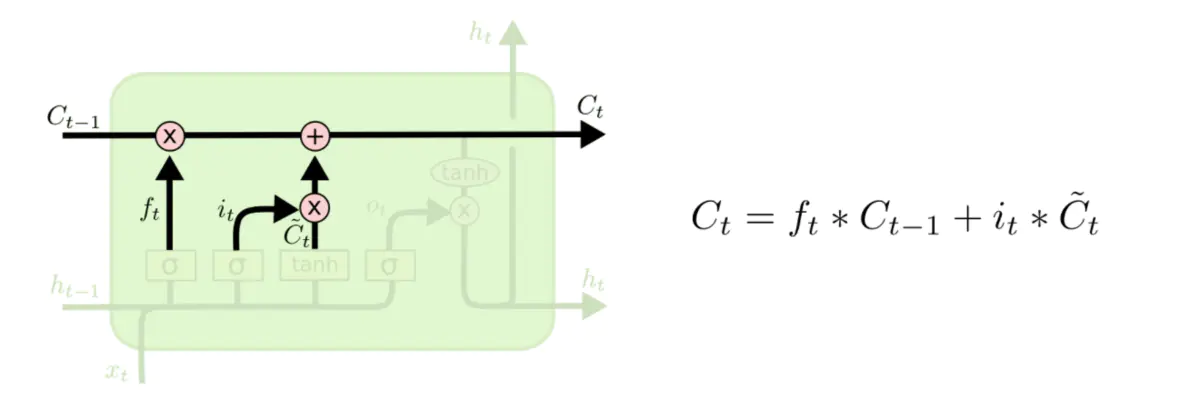
3、输出门
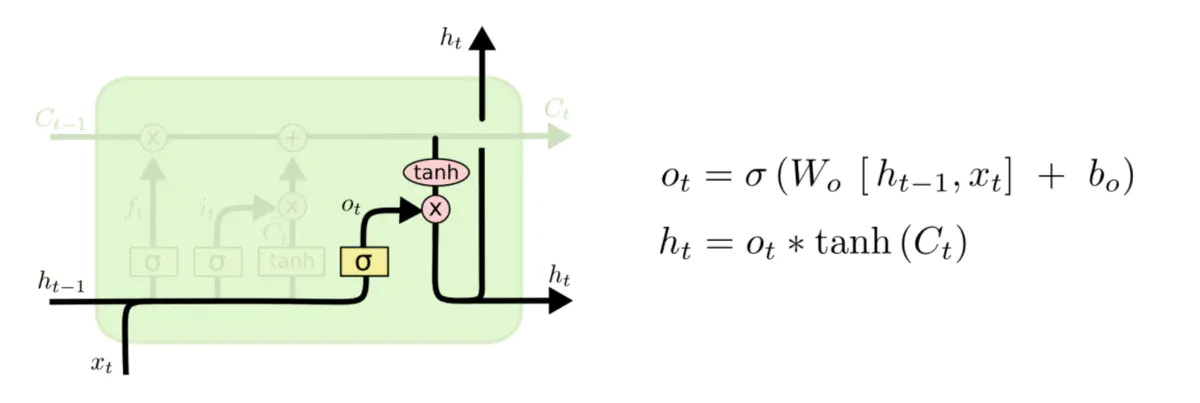
参考:
二、LSTM api
torch.nn.LSTM(input_size,hidden_size,num_layers,batch_first,dropout,bidirectional)
参数列表:
input_size:输入数据的形状,即embedding_dimhidden_size:隐藏层神经元的数量,即每一层有多少个LSTM单元,即隐藏层节点的个数,这个和单层感知器的结构是类似的。这个维数值是自定义的,根据具体业务需要决定num_layer:即RNN的中LSTM单元的层数,lstm隐层的层数,默认为1,LSTM 堆叠的层数,默认值是1层,如果设置为2,第二个LSTM接收第一个LSTM的计算结果。也就是第一层输入 [ X0 X1 X2 ... Xt],计算出 [ h0 h1 h2 ... ht ],第二层将 [ h0 h1 h2 ... ht ] 作为 [ X0 X1 X2 ... Xt] 输入再次计算,输出最后的 [ h0 h1 h2 ... ht ]。batch_first:默认值为False,输入的数据需要[seq_len,batch,feature],如果为True,则为[batch,seq_len,feature]dropout: dropout的比例,默认值为0。dropout是一种训练过程中让部分参数随机失活的一种方式,能够提高训练速度,同时能够解决过拟合的问题。这里是在LSTM的最后一层,对每个输出进行dropoutbidirectional:是否使用双向LSTM,默认是False。是否是双向 RNN,默认为:false,若为 true,则:num_directions=2,否则为1。 我的理解是,LSTM 可以根据数据输入从左向右推导结果。然后再用结果从右到左反推导,看原因和结果之间是否可逆。也就是原因和结果是一对一关系,还是多对一的关系。这仅仅是我肤浅的假设,有待证明。- bias: 隐层状态是否带bias,默认为true。bias是偏置值,或者偏移值。没有偏置值就是以0为中轴,或以0为起点。偏置值的作用请参考单层感知器相关结构。
输入:input, (h0, c0)
输入数据格式:
input (seq_len, batch, input_size)
h0 (num_layers * num_directions, batch, hidden_size)
c0 (num_layers * num_directions, batch, hidden_size)
输出:output, (hn,cn)
output (seq_len, batch, hidden_size * num_directions)
hn (num_layers * num_directions, batch, hidden_size)
cn (num_layers * num_directions, batch, hidden_size)
理解:
input:
第一维度体现的是batch_size,也就是一次性喂给网络多少条句子,或者股票数据中的,一次性喂给模型多少个时间单位的数据,具体到每个时刻,也就是一次性喂给特定时刻处理的单元的单词数或者该时刻应该喂给的股票数据的条数。上图中10表示一次性喂给模型10个句子。
第二维体现的是序列(sequence)结构,也就是序列的个数,用文章来说,就是每个句子的长度,因为是喂给网络模型,一般都设定为确定的长度,也就是我们喂给LSTM神经元的每个句子的长度,当然,如果是其他的带有带有序列形式的数据,则表示一个明确分割单位长度。上图中40表示10个句子的统一长度均为40个单词。
例如是如果是股票数据内,这表示特定时间单位内,有多少条数据。这个参数也就是明确这个层中有多少个确定的单元来处理输入的数据。
第三维度体现的是输入的元素(elements of input),也就是,每个具体的单词用多少维向量来表示,或者股票数据中 每一个具体的时刻的采集多少具体的值,比如最低价,最高价,均价,5日均价,10均价,等等。上图中100表示每个单词的词向量是100维的。
h0-hn
就是每个时刻中间神经元应该保存的这一时刻的根据输入和上一课的时候的中间状态值应该产生的本时刻的状态值,这个数据单元是起的作用就是记录这一时刻之前考虑到所有之前输入的状态值,形状应该是和特定时刻的输出一致
c0-cn
就是开关,决定每个神经元的隐藏状态值是否会影响的下一时刻的神经元的处理,形状应该和h0-hn一致。当然如果是双向,和多隐藏层还应该考虑方向和隐藏层的层数。
三、问题
LSTM模型输出的output是啥意思?
输出的h_n是啥意思?
输出的c_n是啥意思?
理解:
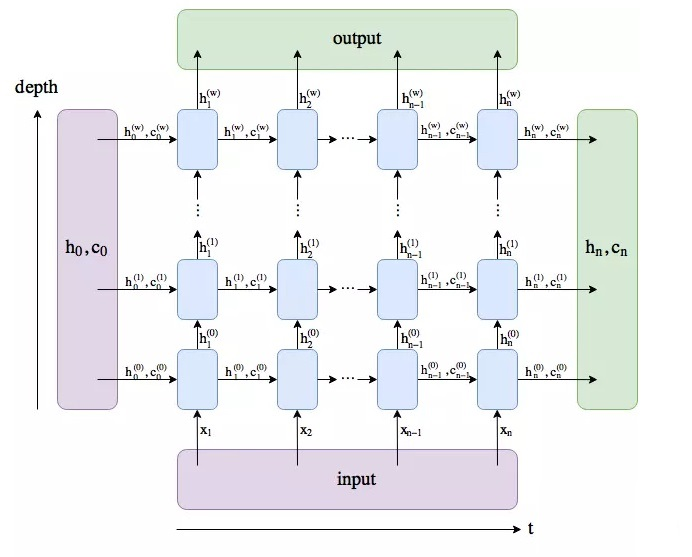
h_n:只返回最后一个时间步的隐藏层输出,第i层会输出h(i)nhn(i),所以第一维为num_layers * num_directions,第二维的维度为batch_size,第三位就是hh本身的维度大小,即hidden_size。
c_n:cn的维度同hn。
output:返回每个时间步的隐藏层输出,所以第一维为seq_len,第二维的维度为batch_size,第三维就是hidden_size,双向的话拼接起来就是2*hidden_size,所以就是num_directions * hidden_size。h_n和c_n我都理解分别是上图中横向箭头中的下方箭头和上方的箭头,那output是干什么用的?output是每个时间t,LSTM最后一层的输出特征h_t。
由于 h_n 和 output 都包含了最后一个时间步的隐藏层输出,所以output[−1,:,:]=hn[−1,:,:]
【注】如果batch_first=True,则 output[:,−1,:]=hn[−1,:,:]
实验一下:
使用文本情感分类的demo,双向lstm,
batch_size设置为64,
batch_first=False
seq_len:500
hidden_size :64
num_directions:2
num_layers:2

所以此时的output形状为【500,64,64*2】,h_n形状为【2*2,64,64】
反向的情况下:
output[0,:,-64:] == h_n[-1]
正向的情况下:
output[-1,:,:64] == h_n[-2]
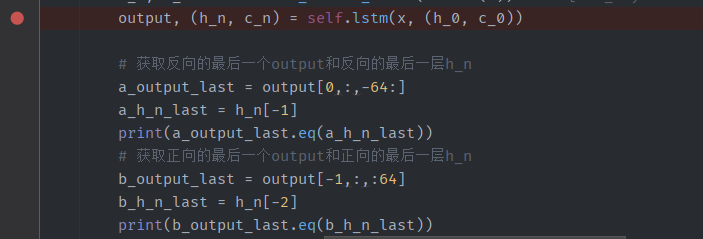
结果是:
参考:
https://www.cnblogs.com/zyb993963526/p/13786310.html
https://www.cnblogs.com/LiuXinyu12378/p/12322993.html
四、文本情感分类demo
使用的双向LSTM模型
训练结果:
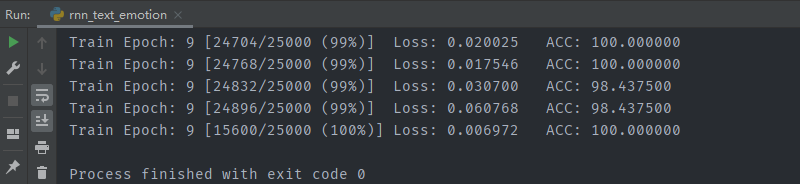
测试结果:
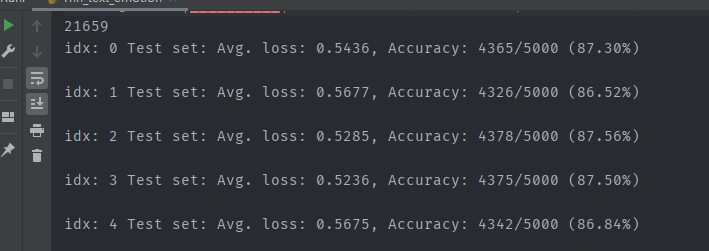
完整代码:


1 import torch 2 import torch.nn as nn 3 import torch.nn.functional as F 4 from torch import optim 5 import os 6 import re 7 import pickle 8 import numpy as np 9 from torch.utils.data import Dataset, DataLoader 10 from tqdm import tqdm 11 12 13 dataset_path = r'C:\Users\ci21615\Downloads\aclImdb_v1\aclImdb' 14 MAX_LEN = 500 15 16 def tokenize(text): 17 """ 18 分词,处理原始文本 19 :param text: 20 :return: 21 """ 22 fileters = ['!', '"', '#', '$', '%', '&', '\(', '\)', '\*', '\+', ',', '-', '\.', '/', ':', ';', '<', '=', '>', '\?', '@' 23 , '\[', '\\', '\]', '^', '_', '`', '\{', '\|', '\}', '~', '\t', '\n', '\x97', '\x96', '”', '“', ] 24 text = re.sub("<.*?>", " ", text, flags=re.S) 25 text = re.sub("|".join(fileters), " ", text, flags=re.S) 26 return [i.strip() for i in text.split()] 27 28 29 class ImdbDataset(Dataset): 30 """ 31 准备数据集 32 """ 33 def __init__(self, mode): 34 super(ImdbDataset, self).__init__() 35 if mode == 'train': 36 text_path = [os.path.join(dataset_path, i) for i in ['train/neg', 'train/pos']] 37 else: 38 text_path = [os.path.join(dataset_path, i) for i in ['test/neg', 'test/pos']] 39 self.total_file_path_list = [] 40 for i in text_path: 41 self.total_file_path_list.extend([os.path.join(i, j) for j in os.listdir(i)]) 42 43 def __getitem__(self, item): 44 cur_path = self.total_file_path_list[item] 45 cur_filename = os.path.basename(cur_path) 46 # 获取标签 47 label_temp = int(cur_filename.split('_')[-1].split('.')[0]) - 1 48 label = 0 if label_temp < 4 else 1 49 text = tokenize(open(cur_path, encoding='utf-8').read().strip()) 50 return label, text 51 52 def __len__(self): 53 return len(self.total_file_path_list) 54 55 56 class Word2Sequence(): 57 UNK_TAG = 'UNK' 58 PAD_TAG = 'PAD' 59 UNK = 0 60 PAD = 1 61 62 def __init__(self): 63 self.dict = { 64 self.UNK_TAG: self.UNK, 65 self.PAD_TAG: self.PAD 66 } 67 self.count = {} # 统计词频 68 69 def fit(self, sentence): 70 """ 71 把单个句子保存到dict中 72 :return: 73 """ 74 for word in sentence: 75 self.count[word] = self.count.get(word, 0) + 1 76 77 def build_vocab(self, min=5, max=None, max_feature=None): 78 """ 79 生成词典 80 :param min: 最小出现的次数 81 :param max: 最大次数 82 :param max_feature: 一共保留多少个词语 83 :return: 84 """ 85 # 删除词频小于min的word 86 if min is not None: 87 self.count = {word:value for word,value in self.count.items() if value > min} 88 # 删除词频大于max的word 89 if max is not None: 90 self.count = {word:value for word,value in self.count.items() if value < max} 91 # 限制保留的词语数 92 if max_feature is not None: 93 temp = sorted(self.count.items(), key=lambda x:x[-1],reverse=True)[:max_feature] 94 self.count = dict(temp) 95 for word in self.count: 96 self.dict[word] = len(self.dict) 97 # 得到一个反转的字典 98 self.inverse_dict = dict(zip(self.dict.values(), self.dict.keys())) 99 100 def transform(self, sentence, max_len=None): 101 """ 102 把句子转化为序列 103 :param sentence: [word1, word2...] 104 :param max_len: 对句子进行填充或裁剪 105 :return: 106 """ 107 if max_len is not None: 108 if max_len > len(sentence): 109 sentence = sentence + [self.PAD_TAG] * (max_len - len(sentence)) # 填充 110 if max_len < len(sentence): 111 sentence = sentence[:max_len] # 裁剪 112 return [self.dict.get(word, self.UNK) for word in sentence] 113 114 def inverse_transform(self, indices): 115 """ 116 把序列转化为句子 117 :param indices: [1,2,3,4...] 118 :return: 119 """ 120 return [self.inverse_dict.get(idx) for idx in indices] 121 122 def __len__(self): 123 return len(self.dict) 124 125 126 def fit_save_word_sequence(): 127 """ 128 从数据集构建字典 129 :return: 130 """ 131 ws = Word2Sequence() 132 train_path = [os.path.join(dataset_path, i) for i in ['train/neg', 'train/pos']] 133 total_file_path_list = [] 134 for i in train_path: 135 total_file_path_list.extend([os.path.join(i, j) for j in os.listdir(i)]) 136 for cur_path in tqdm(total_file_path_list, desc='fitting'): 137 sentence = open(cur_path, encoding='utf-8').read().strip() 138 res = tokenize(sentence) 139 ws.fit(res) 140 # 对wordSequesnce进行保存 141 ws.build_vocab(min=10) 142 # pickle.dump(ws, open('./lstm_model/ws.pkl', 'wb')) 143 return ws 144 145 146 def get_dataloader(mode='train', batch_size=20, ws=None): 147 """ 148 获取数据集,转换成词向量后的数据集 149 :param mode: 150 :return: 151 """ 152 # 导入词典 153 # ws = pickle.load(open('./model/ws.pkl', 'rb')) 154 # 自定义collate_fn函数 155 def collate_fn(batch): 156 """ 157 batch是list,其中是一个一个元组,每个元组是dataset中__getitem__的结果 158 :param batch: 159 :return: 160 """ 161 batch = list(zip(*batch)) 162 labels = torch.LongTensor(batch[0]) 163 texts = batch[1] 164 # 获取每个文本的长度 165 lengths = [len(i) if len(i) < MAX_LEN else MAX_LEN for i in texts] 166 # 每一段文本句子都转换成了n个单词对应的数字组成的向量,即500个单词数字组成的向量 167 temp = [ws.transform(i, MAX_LEN) for i in texts] 168 texts = torch.LongTensor(temp) 169 del batch 170 return labels, texts, lengths 171 dataset = ImdbDataset(mode) 172 dataloader = DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn) 173 return dataloader 174 175 176 class ImdbLstmModel(nn.Module): 177 178 def __init__(self, ws): 179 super(ImdbLstmModel, self).__init__() 180 self.hidden_size = 64 # 隐藏层神经元的数量,即每一层有多少个LSTM单元 181 self.embedding_dim = 200 # 每个词语使用多长的向量表示 182 self.num_layer = 2 # 即RNN的中LSTM单元的层数 183 self.bidriectional = True # 是否使用双向LSTM,默认是False,表示双向LSTM,也就是序列从左往右算一次,从右往左又算一次,这样就可以两倍的输出 184 self.num_directions = 2 if self.bidriectional else 1 # 是否双向取值,双向取值为2,单向取值为1 185 self.dropout = 0.5 # dropout的比例,默认值为0。dropout是一种训练过程中让部分参数随机失活的一种方式,能够提高训练速度,同时能够解决过拟合的问题。这里是在LSTM的最后一层,对每个输出进行dropout 186 # 每个句子长度为500 187 # ws = pickle.load(open('./model/ws.pkl', 'rb')) 188 print(len(ws)) 189 self.embedding = nn.Embedding(len(ws), self.embedding_dim) 190 self.lstm = nn.LSTM(self.embedding_dim,self.hidden_size,self.num_layer,bidirectional=self.bidriectional,dropout=self.dropout) 191 self.fc = nn.Linear(self.hidden_size * self.num_directions, 20) 192 self.fc2 = nn.Linear(20, 2) 193 194 def init_hidden_state(self, batch_size): 195 """ 196 初始化 前一次的h_0(前一次的隐藏状态)和c_0(前一次memory) 197 :param batch_size: 198 :return: 199 """ 200 h_0 = torch.rand(self.num_layer * self.num_directions, batch_size, self.hidden_size) 201 c_0 = torch.rand(self.num_layer * self.num_directions, batch_size, self.hidden_size) 202 return h_0, c_0 203 204 def forward(self, input): 205 # 句子转换成词向量 206 x = self.embedding(input) 207 # 如果batch_first为False的话转换一下seq_len和batch_size的位置 208 x = x.permute(1,0,2) # [seq_len, batch_size, embedding_num] 209 # 初始化前一次的h_0(前一次的隐藏状态)和c_0(前一次memory) 210 h_0, c_0 = self.init_hidden_state(x.size(1)) # [num_layers * num_directions, batch, hidden_size] 211 output, (h_n, c_n) = self.lstm(x, (h_0, c_0)) 212 213 # 获取反向的最后一个output和反向的最后一层h_n 214 a_output_last = output[0,:,-64:] 215 a_h_n_last = h_n[-1] 216 print(a_output_last.eq(a_h_n_last)) 217 # 获取正向的最后一个output和正向的最后一层h_n 218 b_output_last = output[-1,:,:64] 219 b_h_n_last = h_n[-2] 220 print(b_output_last.eq(b_h_n_last)) 221 222 # 只要最后一个lstm单元处理的结果,这里多去的hidden state 223 out = torch.cat([h_n[-2, :, :], h_n[-1, :, :]], dim=-1) 224 out = self.fc(out) 225 out = F.relu(out) 226 out = self.fc2(out) 227 return F.log_softmax(out, dim=-1) 228 229 # output, (h_n, c_n) = self.lstm(x, (h_0, c_0)) 230 # # g = output[-1,:,:] 231 # # f = h_n[-1,:,:] 232 # # a = h_n[-2,:,:] 233 # # b = h_n[-1,:,:] 234 # # out = torch.cat([a, b], dim=-1) 235 # o = output[-1,:,:] 236 # out = self.fc(o) 237 # out = F.relu(out) 238 # out = self.fc2(out) 239 # res = F.log_softmax(out, dim=-1) 240 # return res 241 242 243 train_batch_size = 64 244 test_batch_size = 5000 245 246 def train(epoch, ws): 247 """ 248 训练 249 :param epoch: 轮次 250 :param ws: 字典 251 :return: 252 """ 253 mode = 'train' 254 imdb_lstm_model = ImdbLstmModel(ws) 255 optimizer = optim.Adam(imdb_lstm_model.parameters()) 256 for i in range(epoch): 257 train_dataloader = get_dataloader(mode=mode, batch_size=train_batch_size, ws=ws) 258 for idx, (target, input, input_length) in enumerate(train_dataloader): 259 optimizer.zero_grad() 260 output = imdb_lstm_model(input) 261 loss = F.nll_loss(output, target) 262 loss.backward() 263 optimizer.step() 264 265 pred = torch.max(output, dim=-1, keepdim=False)[-1] 266 acc = pred.eq(target.data).numpy().mean() * 100. 267 print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\t ACC: {:.6f}'.format(i, idx * len(input), len(train_dataloader.dataset), 268 100. * idx / len(train_dataloader), loss.item(), acc)) 269 torch.save(imdb_lstm_model.state_dict(), 'model/lstm_model.pkl') 270 torch.save(optimizer.state_dict(), 'model/lstm_optimizer.pkl') 271 272 273 def test(ws): 274 mode = 'test' 275 # 载入模型 276 lstm_model = ImdbLstmModel(ws) 277 lstm_model.load_state_dict(torch.load('model/lstm_model.pkl')) 278 optimizer = optim.Adam(lstm_model.parameters()) 279 optimizer.load_state_dict(torch.load('model/lstm_optimizer.pkl')) 280 lstm_model.eval() 281 test_dataloader = get_dataloader(mode=mode, batch_size=test_batch_size, ws=ws) 282 with torch.no_grad(): 283 for idx, (target, input, input_length) in enumerate(test_dataloader): 284 output = lstm_model(input) 285 test_loss = F.nll_loss(output, target, reduction='mean') 286 pred = torch.max(output, dim=-1, keepdim=False)[-1] 287 correct = pred.eq(target.data).sum() 288 acc = 100. * pred.eq(target.data).cpu().numpy().mean() 289 print('idx: {} Test set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(idx, test_loss, correct, target.size(0), acc)) 290 291 292 if __name__ == '__main__': 293 # 构建字典 294 ws = fit_save_word_sequence() 295 # 训练 296 train(10, ws) 297 # 测试 298 # test(ws)
参考:
https://www.cnblogs.com/luckyplj/p/13370072.html
https://blog.csdn.net/wangwangstone/article/details/90296461

 浙公网安备 33010602011771号
浙公网安备 33010602011771号