
昨天遇到一个问题,就是需要删掉一个表里的重复数据,还有就是希望这个表的ID能够连续,因为一旦删掉重复记录,作为自增主键的ID就会不连续了,所以就要想办法搞定
表中数据:
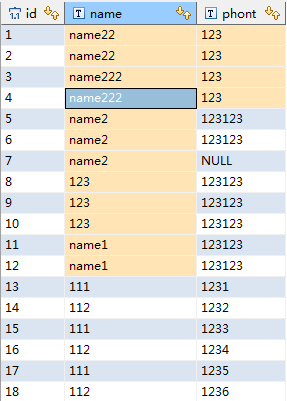
我想要把名字重复的去掉,但是还希望ID能够连续。
首先是将数据库里边的重复记录删掉,我看网上有好多答案是这样的:
1 delete from people 2 where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1) 3 and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
但其实我每次运行这条语句都是行不通的,会报错:
SQL 错误 [1093] [HY000]: You can't specify target table 'test1' for update in FROM clause
java.sql.SQLException: You can't specify target table 'test1' for update in FROM clause
去网上查过好像是说update以及delete操作没办法跟查询操作一起做的,我看过有的更新的跟查询的一起做的好像是给查出来的那部分起个别名,然后进行更新就可以了,但是删除这个我起了别名也不对,不知道是我写错还是不行,我就跳过这个方法了。
我用的方法是:先查出数据库中的重复记录的数据中的一条,这个不难,很简单的,sql语句如下:
select * from test1 where name in (select name from test1 group by name having count(name) > 1) and id in (select min(id) from test1 group by name having count(name)>1)
结果如下:
id |name |phont |
---|--------|-------|
1 |name22 |123 |
3 |name222 |123 |
5 |name2 |123123 |
8 |123 |123123 |
11 |name1 |123123 |
13 |111 |1231 |
14 |112 |1232 |
这些都是不重复的,换句话说都是要保留的,不被删掉的,而其余与这些结果中name相同的应该被删掉。
也就是说将上边那个sql语句id后边加一个not ,查出来的结果就是要删掉的:结果如下
id |name |phont |
---|--------|-------|
2 |name22 |123 |
4 |name222 |123 |
6 |name2 |123123 |
7 |name2 |NULL |
9 |123 |123123 |
10 |123 |123123 |
12 |name1 |123123 |
15 |111 |1233 |
16 |112 |1234 |
17 |111 |1235 |
18 |112 |1236 |
我把这些需要删掉的存到另外一个表里,然后我新建一个test2表,结构复制test1的结构就好了
1 CREATE TABLE `test2` ( 2 `id` int(11) NOT NULL AUTO_INCREMENT, 3 `name` varchar(50) DEFAULT NULL, 4 `phont` varchar(50) DEFAULT NULL, 5 PRIMARY KEY (`id`) 6 ) ENGINE=InnoDB DEFAULT CHARSET=utf8
然后插入语句是:
1 insert into test2( 2 select * from test.test1 where name in (select name from test.test1 group by name having count(name) > 1) 3 and id not in (select min(id) from test.test1 group by name having count(name)>1) 4 )
然后test2的表里的数据就是下图这样的:
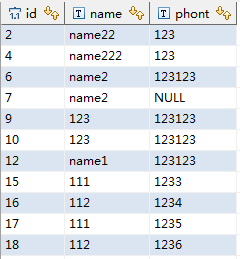
那接下来做的就是删掉test1表里边与test2表的id相同的数据。
1 delete a.* from test1 a, test2 b where a.id = b.id ;
这样,test1里边的数据就变成了:

这样的结果就是完全不重复的,但是我还想要他们的id是连续的,而不是这样的断开的。
我的做法是将这个表的除掉id之外的所有字段查出插入到另外一个表test3中,当然,test3要设置id为自增主键,但是不插入id,让它自增,就连续了
当然要新建表test3啦,不过把上边新建的test2那个复制下来改名字为test3就好啦。
然后插入:
1 insert into test3(name, phont) 2 (select name, phont from test1)
test3表里的结果就是:
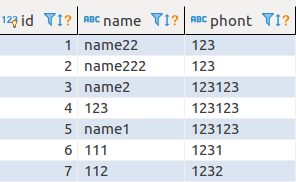
这样就可以把test3改成你想要的名字,然后删掉test1和test2了,大功告成~
不过感觉还可以就是将已经删掉重复数据的表test1的数据全都导出来,一般的数据库连接工具都有这样的功能,导成sql格式的,然后新建一个表,比test1多增一个自增主键字段叫NewId字段,但是Id字段不能再自增了,然后将导成的sql文件导入,不过那个sql文件可能要编辑一下,改一下自增主键id变为普通的字段什么的,然后到新表了之后,删掉id字段,修改NewId为Id,应该也可以,但是这个方法我没试过,原先预想过要这么做但是没有这么做,估计以后可以试试,但是感觉两种的麻烦程度都差不多啊,但是如果将sql语句写下来之后可能还是第一种方法比较快一点吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号