
[转载]CSP-S2019 树的重心
题面分析
原题面
小简单正在学习离散数学,今天的内容是图论基础,在课上他做了如下两条笔记:
- 一个大小为 nn 的树由 n n 个结点与 n - 1n−1 条无向边构成,且满足任意两个结点间有且仅有一条简单路径。在树中删去一个结点及与它关联的边,树将分裂为若干个子树;而在树中删去一条边(保留关联结点,下同),树将分裂为恰好两个子树。
- 对于一个大小为 nn 的树与任意一个树中结点 cc,称 cc 是该树的重心当且仅当在树中删去 cc 及与它关联的边后,分裂出的所有子树的大小均不超过 \lfloor \frac{n}{2} \rfloor ⌊2n⌋(其中 \lfloor x \rfloor ⌊x⌋ 是下取整函数)。对于包含至少一个结点的树,它的重心只可能有 1 或 2 个。
课后老师给出了一个大小为 nn 的树 SS,树中结点从 1 \sim n 1∼n 编号。小简单的课后作业是求出 S S 单独删去每条边后,分裂出的两个子树的重心编号和之和。即:
\sum_{(u,v) \in E} \left( \sum_{1 \leq x \leq n \atop 且 x 号点是 S'_u 的重心} x + \sum_{1 \leq y \leq n \atop 且 y 号点是 S'_v 的重心} y \right)
(u,v)∈E∑⎝⎜⎛且x号点是Su′的重心1≤x≤n∑x+且y号点是Sv′的重心1≤y≤n∑y⎠⎟⎞
上式中, E E 表示树 SS 的边集, (u,v)(u,v) 表示一条连接
uu 号点和 vv 号点的边。S'_u Su′与
S'_v
Sv′分别表示树 S S 删去边 (u,v) (u,v) 后, u u 号点与
vv 号点所在的被分裂出的子树。
小简单觉得作业并不简单,只好向你求助,请你教教他。

细节分析
- 多测不清空,爆零两行泪。

- 如果没有下面这一句提示我们同样需要观察给出的大样例的强度和满足的特殊性质。

- 本题部分分设置的最大玄机:
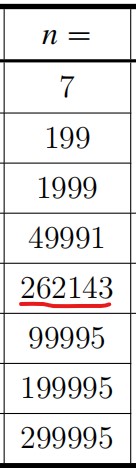
1.注意 nn后面跟的是等号。
2. nn的最后一位数字实际上将这题的子任务划分为了5个档次,我们无需自己判断数据是否满足特殊性质。
3.划红线的数字:

一句话题意
求一颗树断掉任意一条边之后的两棵树的所有重心的编号的和的和。
注:一棵树存在一个或者两个重心。
n\leq 3\times 10^5 n≤3×105。
本题得分目标
- 暴力选手最低配置:暴力, 40+15=55 40+15=55。
带了脑子考试的暴力选手配置:暴力+特性AB,40+15+20=7540+15+20=75。
- AK day2 大佬配置:正解,
90\sim 100
90∼100分。
部分分算法
算法1:暴力(40分)/算法2:链(15分)
暴力按题意断掉一条边然后分别对两个树dfs找出重心即可。
链上的重心显然为这条链的中点(一个或两个),直接模拟即可。
算法3:完美二叉树(20分)
一个显然的想法是完美二叉树具有极强的对称性,考虑我们每层都只删一条边然后暴力,其它的边我们可以通过对称方法等价出来。因此删的边只会是
O(\log n)
]O(logn)级别的,能够通过数据。
当然这题也有很强的规律性。
例如下面这个完美二叉树:

试着分别割去图中带红黄切点的两种边,可以归纳出结论:
- 删除叶子节点连边,根会成为重心之一。
-删除某个除根节点外的节点连边时,这个点会成为重心之一。
-删除根的左子树某条边时,根的右儿子会成为重心之一,对称同理。
这样我们就可以直接计算重心编号之和了。
正解
算法1:换根+倍增
应该是本题最自然的一种解法。
这种做法依据的一个关键性质是:
引理:
对于一个点 xx,如果它不是这颗树的重心,那么重心一定在以它为根的重儿子的子树里面。
这个证明其实比较好理解,大概可以看这张图感性理解一下:

智障与大佬问答环节:
小P:如果一个节点有两个大小相同的最大siz的时候该走那边啊…
巨佬:你可以直接放弃选择。
小P:???
巨佬:此时两个节点的siz显然 \leq \lfloor\frac{n}{2}\rfloor ≤⌊2n⌋,那么这个点就是重心。
小P:…
知道这个做法就好做了,我们考虑换根,每次我们计算割去 x x为父亲 v v为儿子的边两颗树的重心。

定义 hs_{x,k} hsx,k表示以
xx为根时向它的重儿子走 k k步时到达的节点。
假设我们已经求出 hs_{x,k} hsx,k数组,考虑如何求答案:
注意到我们总是往儿子走,那么走到的点的 siz siz会随着走的步数的增加而递减,而我们向下走始终会找到一个重心,因此我们找深度最大的满足 siz_x-siz_v\leq \lfloor\frac{siz_x}{2}\rfloor sizx−sizv≤⌊2sizx⌋的点 vv即为这个树的一个重心,由于可能存在两个重心,我们还需要检验 vv的父亲是不是重心。
那么我们分别考虑在 x x为根和 vv为根的两个联通块内倍增即可。
然而我们还需要处理 siz_x sizx和 hs_{x,k} hsx,k。
- 在处理 xx这一部分时, siz_x sizx改为 n-siz_v n−sizv, hs_{x,0} hsx,0儿子现在不包含 x x而加入了父亲,因此还要记录 x x的次重儿子进行更新,更新完 hs_{x,0} hsx,0之后再依次更新 hs_{x,1...} hsx,1...的信息。
- 在处理 vv这一部分时,无需进行更改。
- 注意保存割去边后的父亲数组也会相应更改,这里不详细解释。
处理完 xx之后,我们还需要记住还原 xx被修改的信息。
一次dfs找重儿子和次重儿子,一次dfs找答案即可。
复杂度:
O(n\log n) O(nlogn)
#include<cstdio>
#include<iostream>
#include<algorithm>
#include<cstring>
#include<cmath>
#include<queue>
#include<vector>
using namespace std;
#define LL long long
#define MAXN 3000000
#define mem(x,v) memset(x,v,sizeof(x))
LL read(){
LL x=0,F=1;char c=getchar();
while(c<'0'||c>'9'){if(c=='-')F=-1;c=getchar();}
while(c>='0'&&c<='9'){x=x10+c-'0';c=getchar();}
return xF;
}
int T,n;
vector<int> G[MAXN+5];
int siz[MAXN+5],hs[MAXN+5][18],f[MAXN+5];
int phs[MAXN+5];LL ans;
void upd(int x){
for(int k=1;k<=17;k++)
hs[x][k]=hs[hs[x][k-1]][k-1];
}
bool check(int x,int N){
return max(N-siz[x],siz[hs[x][0]])<=(N/2);
}
void dfs1(int x,int fa){
siz[x]=1,hs[x][0]=phs[x]=0,f[x]=fa;
for(int i=0;i<G[x].size();i++){
int v=G[x][i];
if(vfa)continue;
dfs1(v,x);
siz[x]+=siz[v];
if(siz[hs[x][0]]<siz[v])phs[x]=hs[x][0],hs[x][0]=v;
else if(siz[phs[x]]<siz[v])phs[x]=v;
}
}
void dfs2(int x,int fa){
int prehs=hs[x][0],presz=siz[x];
for(int i=0;i<G[x].size();i++){
int v=G[x][i];
if(vfa)continue;
if(v==prehs)hs[x][0]=phs[x];
else hs[x][0]=prehs;
if(siz[fa]>siz[hs[x][0]])hs[x][0]=fa;
upd(x);
siz[x]=n-siz[v],f[x]=0,f[v]=0;
int p=x;
for(int k=17;k>=0;k--)
if(hs[p][k]&&siz[x]-siz[hs[p][k]]<=(siz[x]/2))p=hs[p][k];
ans+=p+f[p]check(f[p],siz[x]);
//printf("::%d %d\n",x,v);
//printf("**%d %d\n",p,f[p]check(f[p],siz[x]));
p=v;
for(int k=17;k>=0;k--)
if(hs[p][k]&&siz[v]-siz[hs[p][k]]<=(siz[v]/2))p=hs[p][k];
ans+=p+f[p]check(f[p],siz[v]);
//printf("**%d %d\n",p,f[p]check(f[p],siz[v]));
f[x]=v;
dfs2(v,x);
}
siz[x]=presz,hs[x][0]=prehs,f[x]=fa,upd(x);
}
int main(){
T=read();
while(T--){
ans=0;
n=read();
for(int i=1;i<=n;i++)G[i].clear();
for(int i=1;i<n;i++){
int u=read(),v=read();
G[u].push_back(v),G[v].push_back(u);
}
dfs1(1,0);
for(int k=1;k<=17;k++)
for(int i=1;i<=n;i++)
hs[i][k]=hs[hs[i][k-1]][k-1];
dfs2(1,0);
printf("%lld\n",ans);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
算法2:换根+树状数组
这个做法具有一定的通用性。
考虑对于每一个点计算作为重心的次数。
那么对于一个点 xx而言我们可以:
- 切取它子树内的一个子树,这个点成为重心。
- 切取它子树外的一个子树,这个点成为重心。
- 保留包含该子树的一个子树,这个点成为重心。
这样讨论不是不可做,但是讨论起来相当麻烦,因此我们试着优化一下。
考虑我们首先找到原树的一个重心作为根 rtrt,对于一个点
x \neq rt x=rt就不会存在第一种情况。因为子树内的点数始终小于 \lfloor \frac{n}{2}\rfloor ⌊2n⌋,父亲方向的连通块大小就会始终大于
\lfloor \frac{n}{2}\rfloor ⌊2n⌋。
设
mx_x=\max^{siz_x}_{i=1}{siz_{son_{x,i}}}
mxx=maxi=1sizxsizsonx,i
考虑割掉子树外大小为 PP的连通块使得
xx成为重心,那么应该满足:
n-P-siz_x\leq \lfloor \frac{n-P}{2}\rfloor\\ mx_x\leq \lfloor\frac{n-P}{2}\rfloor\\ n−P−sizx≤⌊2n−P⌋mxx≤⌊2n−P⌋
联立不等式得到
n-2siz_x\leq P\leq n-2mx_x n−2sizx≤P≤n−2mxx
仍然考虑换根,我们在换根时维护 P=x P=x时有多少种割法,一次换根只会影响到一个
PP值的改变。
然而这样统计我们也统计了在 xx子树内的 PP值,我们需要想办法减去它。
注意到子树是dfs过程中连续的一段,因此我们可以让答案在dfs出 x x点时已经过的点符合条件的
P P值的个数减去进 xx点时已经过的点符合条件的 PP值的个数。类似NOIP2016天天爱跑步的思路。
同样可以用一个树状数组解决这个问题。当然如果你没有想到这个思路,无脑线段树合并也是可做的。
但是我们还需要统计 x=rtx=rt时合法的割边数。
由于只有一个点,我们暴力讨论即可。
- 若割掉的边是该点的重儿子,设次大儿子的大小为 cmx_{rt} cmxrt,需要满足:
cmx_{rt}\leq \lfloor\frac{n-P}{2}\rfloor\\ mx_{rt}-P\leq \lfloor\frac{n-P}{2}\rfloor\\ cmxrt≤⌊2n−P⌋mxrt−P≤⌊2n−P⌋
联立解得:
2mx_{rt}-n\leq S\leq n-2cmx_rt 2mxrt−n≤S≤n−2cmxrt
不过由于 rt rt是重心,后面的值恒小于 0 0,因此可以忽略后面的限制。 - 若割掉的边不是该点的重儿子,那就只需要满足:
mx_{rt}\leq \lfloor\frac{n-P}{2}\rfloor\\ mxrt≤⌊2n−P⌋
因此
S\leq n-2mx_{rt}S≤n−2mxrt
在上面dfs时同时计算即可。
复杂度: O(n\log n) O(nlogn)。
#include<cstdio>
#include<iostream>
#include<algorithm>
#include<cstring>
#include<cmath>
#include<queue>
#include<vector>
using namespace std;
#define LL long long
#define MAXN 3000000
#define mem(x,v) memset(x,v,sizeof(x))
LL read(){
LL x=0,F=1;char c=getchar();
while(c<'0'||c>'9'){if(c=='-')F=-1;c=getchar();}
while(c>='0'&&c<='9'){x=x10+c-'0';c=getchar();}
return xF;
}
int T,n,rt;
int siz[MAXN+5],hs[MAXN+5],phs[MAXN+5],flag[MAXN+5];
vector<int> G[MAXN+5];
LL ans;
struct bit{
int C[MAXN+5];
void init(){mem(C,0);}
int lowbit(int x){return x&(-x);}
void Insert(int x,int v){
x++;
while(x<=n+1)C[x]+=v,x+=lowbit(x);
}
LL Query(int x){
x++;LL res=0;
while(x)res+=C[x],x-=lowbit(x);
return res;
}
}T1,T2;
bool check(int x,int N){
return max(N-siz[x],siz[hs[x]])<=(N/2);
}
void dfs1(int x,int fa){
siz[x]=1,hs[x]=phs[x]=0;
for(int i=0;i<G[x].size();i++){
int v=G[x][i];
if(vfa)continue;
dfs1(v,x);
siz[x]+=siz[v];
if(siz[hs[x]]<siz[v])phs[x]=hs[x],hs[x]=v;
else if(siz[phs[x]]<siz[v])phs[x]=v;
}
if(check(x,n))rt=x;
}
void dfs2(int x,int fa){
if(x!=rt){
flag[x]|=flag[fa];
T1.Insert(siz[fa],-1);
T1.Insert(n-siz[x],1);
ans+=x(T1.Query(n-2siz[hs[x]])-T1.Query(n-2siz[x]-1));
ans+=x(T2.Query(n-2siz[hs[x]])-T2.Query(n-2siz[x]-1));
if(flag[x])ans+=rt(siz[x]<=n-2siz[phs[rt]]);
else ans+=rt(siz[x]<=n-2siz[hs[rt]]);
}
T2.Insert(siz[x],1);
for(int i=0;i<G[x].size();i++){
int v=G[x][i];
if(vfa)continue;
dfs2(v,x);
}
if(x!=rt){
T1.Insert(siz[fa],1);
T1.Insert(n-siz[x],-1);
ans-=x(T2.Query(n-2siz[hs[x]])-T2.Query(n-2*siz[x]-1));
}
}
int main(){
T=read();
while(T--){
ans=rt=0;
n=read();
for(int i=1;i<=n;i++)G[i].clear();
for(int i=1;i<n;i++){
int u=read(),v=read();
G[u].push_back(v),G[v].push_back(u);
}
dfs1(1,0),dfs1(rt,0);
T1.init(),T2.init();
for(int i=1;i<=n;i++)T1.Insert(siz[i],1),flag[i]=0;
flag[hs[rt]]=1;
dfs2(rt,0);
printf("%lld\n",ans);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
本题小结
- 本题是CSP day2难度最高的题目,难度比T1T2相对来说要大的多。
对于在场大多数同学来说,这道题还是具有极大的挑战性的。
但是本题的部分分做法不难且与正解思路没有太大关联,因此,拿稳部分分75分相当关键。 - 虽然近年来D2T3题目难度逐年攀升,但是其中的核心思想还是没有变。
不难发现,每年联赛中最难的题很容易出现倍增思想的题目(NOIP2019,NOIP2018,NOIP2016,NOIP2015,NOIP2013,NOIP2012…好像有点规律),难度也逐渐提升。其中提升难度的一个重要方式就是借鉴往年题目的思路与做法。例如今年的题目就有借鉴NOIP2018保卫王国和NOIP2016天天爱跑步的思路,并在这个思路上做出创新,变成更难的题。
因此认真研究往年的题目肯定的是有一定作用的:) - 本题在考点上与[Day1T2 括号树]的换根有一定重合,但质量上仍然保持了往年联赛的水准(但是省选联考就不一样了啊…)。
- 关于联赛知识范围之外的知识,在本题中其实是有一定的思维弥补作用的。例如在方法二差分思想同样可以用线段树合并或者主席树代替,但这同时也增加了代码复杂度,并且这题时限比较紧,肯能会被卡成90分。
- 现在联赛出题越来越喜欢多组测试数据了…小心爆零…
骗分也越来越困难了。 - 最后,愿同学们认真研究本题,掌握其核心思想。
讲题人相信,这次美妙的讲题,可以给拼搏于AK IOI的逐梦之路上的你,提供一个有力的援助。
原博客:https://blog.csdn.net/qq_34940287/article/details/107555875

