
[Datawhale AI 夏令营] 机器学习 Task1 体验记录 思考 补充
![[Datawhale AI 夏令营] 机器学习 Task1 体验记录 思考 补充](https://img2024.cnblogs.com/blog/3207177/202407/3207177-20240711211035893-1828449003.png) 陆爻齐参加由 Datawhale 组织的 AI 夏令营第二期活动记录
陆爻齐参加由 Datawhale 组织的 AI 夏令营第二期活动记录
前言
首先感谢 Datawhale 组织这个活动,让我有机会入门机器学习。
嘛,不过这个 Task1 只要跟着速通手册运行给定程序,再拿结果去提交,体验下过程而已,于我而言,更为宝贵的地方是后续的“加餐”,也就是分析题目,精读代码的部分
“加餐”小结
分析题目
赛题任务是:通过多个房屋历史电力消耗数据等信息,预测房屋对应电力的消耗。
这是所谓的“时间序列问题”,简单地说就是分析数据和预测趋势。
说起来,大一的课程设计也简单做过所谓的“酒吧销量预测”功能,当时是采用“线性回归”来着。
而要解决这样的问题,就大致有建立传统时间序列模型、机器学习模型、深度学习模型的方法。
这三种方法各有利弊,按适合处理数据集规模大小和预测能力升序,按解释性和计算资源降序。
分析代码
先贴出代码好了
# 1. 导入需要用到的相关库
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 导入 numpy 库,用于科学计算和多维数组操作
import numpy as np
# 2. 读取训练集和测试集
# 使用 read_csv() 函数从文件中读取训练集数据,文件名为 'train.csv'
train = pd.read_csv('train.csv')
# 使用 read_csv() 函数从文件中读取测试集数据,文件名为 'train.csv'
test = pd.read_csv('test.csv')
# 3. 计算训练数据最近11-20单位时间内对应id的目标均值
target_mean = train[train['dt']<=20].groupby(['id'])['target'].mean().reset_index()
# 4. 将target_mean作为测试集结果进行合并
test = test.merge(target_mean, on=['id'], how='left')
# 5. 保存结果文件到本地
test[['id','dt','target']].to_csv('submit.csv', index=None)
如果只是想了解思路,那么看完速通手册,大致读读注释即可,不过陆爻齐喜欢再深入一点点。
比如,为啥只要11-20天数据,1-20不行吗,reset_index()是什么函数?
要理解处理数据的方式,可以看看数据本身的样子,不过这里吐槽下,我还是第一次见到 WPS 会说太大了,受不了:)

回到正题,来看看这数据集究竟长啥样
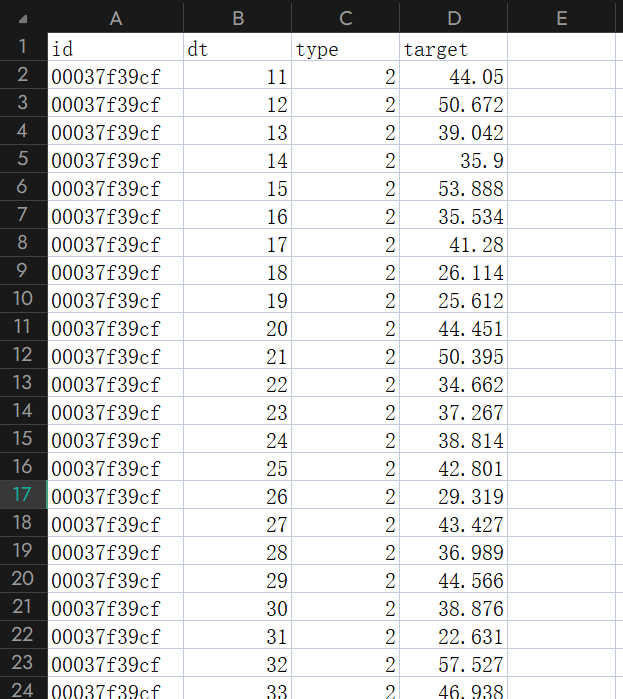
……………………………………………………
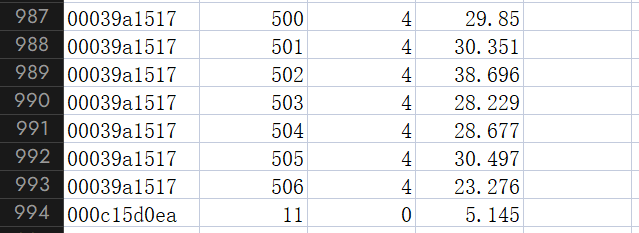
显然,图中 id 是房子编号,dt 是日期,type 是房子类型(暂且用不到),target 是用电量。
所以,代码target_mean = train[train['dt']<=20].groupby(['id'])['target'].mean().reset_index()翻译为自然语言,就是:以 id 为分组标识(想起了 mysql ),选择其中日期 dt 小于等于 20 的数据,计算均值并重置索引。
重置索引的具体解释,可以参考 这篇文章。
如此,target_mean 相当于下面数据
id target
00037f39cf 39.6543
……
而代码test = test.merge(target_mean, on=['id'], how='left')则将上面刚得的 target_mean 与 test 左外连接。
先看看test长啥样好了
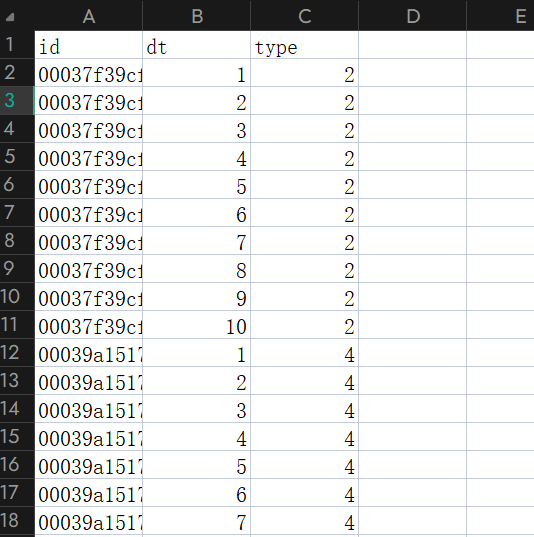
图片不用多加解释,其实所谓的左外连接(又想起 mysql 了),就是把 test 以 id 为组,连到右边的 target_mean,离散数学的映射中算是“满射”
举个栗子,test 中,id 00037f39cf 有十条,区别只有 id 1-10,而target_mean 中,id 00037f39cf 只有一条数据,也就是上面的
id target
00037f39cf 39.6543
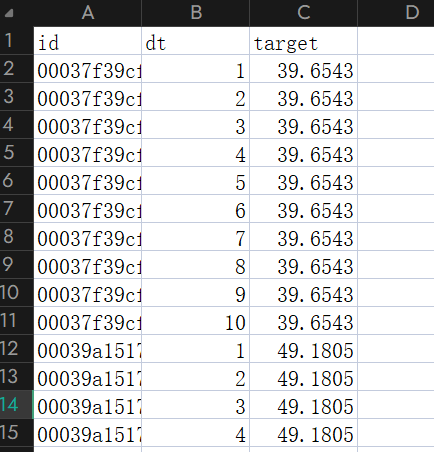
于是按 id 连接,将相同 id 对应进行连接,也就是在 test 的基础上,把 target_mean 同 id 那条数据中,除 id 自己外的属性,连接到 test 上,如
id dt type target
00037f39cf 1 2 39.6543
00037f39cf 2 2 39.6543
00037f39cf 3 2 39.6543
……
最后一条代码,即只保留该数据的id dt target,保存为新的表格 csv 文件,也就是那个 submit.csv。
小结
Task1 本身操作很简单,要理解也不难,对于陆爻齐这样稍微有点基础知识也算有趣,后续推荐的 Pandas 学习的第十章也是时序预测(笑,期待 Task2。

