
查询优化,索引优化
先来两个简单案例!
1. 查询条件有范围的情况,单表

此时这个表没有建索引,所以执行计划分析sql后得出的结论是,性能辣鸡,注意type是All,全表遍历,extra有using filesort,文件排序,太辣鸡了。
按照最简单的想法,那我给categroy_id,comments,views三个列加个联合索引不就行了吗?那么来试试。

可以看到索引建好了,继续用执行计划分析。

发现索引确实被使用了(key),全表遍历也避免了(type=range),但是文件排序还没有解决。
也就是说,这个复合索引虽然解决了查询问题,但是没有解决排序问题,因为这个复合索引排序时是先按category_id排序,一样时再按comments排序,再一样时按views排序,而当comments处于索引的中间位置,且又是范围筛选条件comments>1时(type=range),会令索引后面的排序失效(views的排序)。
删掉这个索引,重新创建新的索引,因为是comments字段是范围筛选条件,干脆不对它做索引,只做另外两个字段,避免失效

执行计划验证下

解决问题!
2.连接查询,两表
有两个表,书籍book和书籍分类class,其中book表有主键bookid和卡号card字段,class表有主键id和卡号card字段,book.card和class.card是关联的,
即可以 book.card join class.card这么查,大概这意思。
左连接

2个表都是全表搜索,辣鸡!
应该加索引,那么问题来了,是加在book表还是class表呢?
先加book表试试,注意book表是右表。

很明显,比两个都不加强多了,book表的type从all变成了ref,rows也从20变成了1,extra变成了覆盖索引。
删除book.card的索引,换成class.card建索引。

发现class表的type变成了index,遍历索引,比之前的all强,但是不如之前book表的ref,并且rows还是20,不如之前book的rows=1,效率不如之前的索引。
为什么会这样?因为左连接的特性是,左表全都包括,我们需要注重的是如何优化右表,因此索引建立在右表效率更高,右连接则反之,但是实际工作中遇到这种情况,通常改一下sql里表的顺序就好了,可别去改表的索引啊!
另外在join的时候,注意要小表驱动大表,即需要遍历的表一定是小表比较好,因为数据量少,效率更高。
所以在这个例子中,class类别表的数据一定比book书本表的数据少,所以查询时以class为主,同时索引建在book表上效率更高。
索引优化
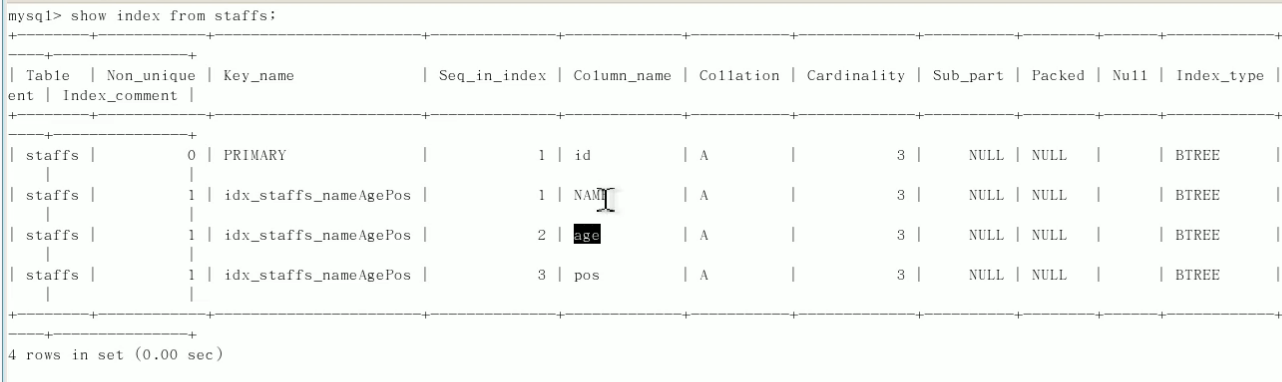
先建立这么一个表staffs,索引如下图,一个主键id,一个联合索引顺序是Name-age-pos。
查询结果和Where条件优化
1.全值匹配,索引中的列正好被全部用到,是最好的;
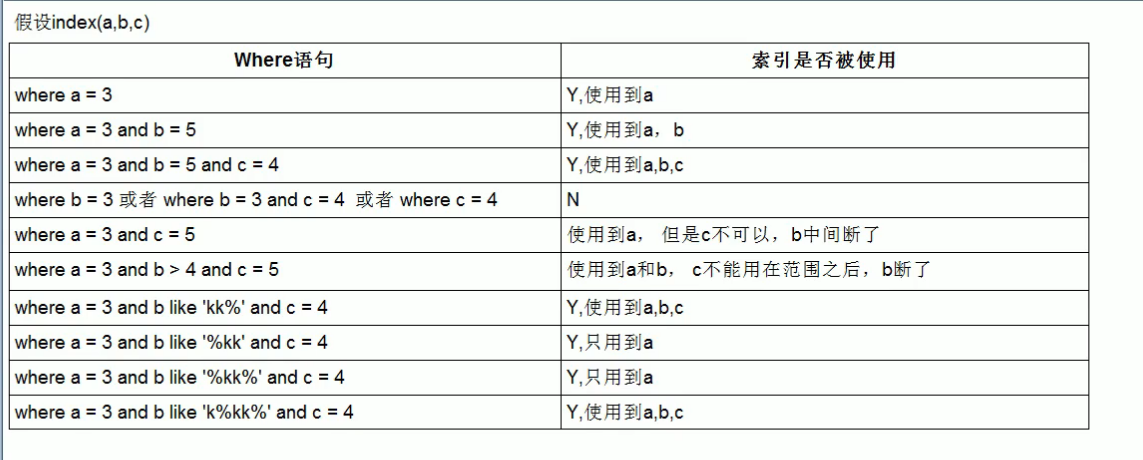
2.最佳左前缀法则,即如果索引了多列,那么查询需要从最左前列开始并且不跳过索引中间的列,以上表为例,where条件可以是,name、name and age、name and age and pos(全值匹配),但是不能是 age、pos、age and pos、name and pos,这里需要注意的是 name and pos 用 执行计划来看是用到了索引,但是只用到了索引中name的那一部分,因为中间跳过了age,所以其实pos部分是失效的,这里需要注意的是,你在where条件里用name,age,pos的时候,顺序可以不跟索引顺序一致,因为数据库的查询分析器不是傻子,会根据索引自动给你调整转换,但是调整转换也会消耗性能(当然极少),索引尽量保持跟索引顺序一致;
3.不在索引列上做任何操作(计算,函数,类型转换),会导致索引失效;
4.存储引擎不能使用索引中范围条件右边的列,即>,<,in,between这种条件出现后,这个范围条件的右边的其他条件即使在索引的列中,也会失效,准确的说是,查找失效,但排序功能还在,这里需要注意的是,失效是按照索引的顺序失效,不是你where条件的顺序,例如索引abcd,where 条件里有d>10这种范围条件,写法是 a=1 and b=2 and d>10 and c=8 ,这种情况下,c这个索引列也不会失效,因为根据第2点里的加黑内容,数据库会先给你调整位置成 a=1 and b=2 and c=8 and d>10,除非你是 c>8 and d= 10这种,d会失效;
5.尽量使用覆盖索引,即用什么查什么,如果用索引列能直接查到实际数据最好;
6.不等于!=,<> 会让索引失效;
7.is null, is not null会让索引失效,所以我们尽量用默认值,例如-1,"暂无"这种来代表没有值;
8.like 以通配符开头,索引会失效,即 a like '%xxxx'这种,哪怕a是索引列,也不会生效,但是'xxxx%' 会生效,因为开头的xxxx限定了范围,所以是range范围查找,如果业务上一定要用'%xxxx%'的话,建议使用覆盖索引;
9.字符串必须加上单引号,否则索引失效,mysql容易出现这种问题,例如一个varchar列的值是个数字,查的时候可以不带'',因为mysql会帮你进行类型转换把数字转成字符串,违反了第3条;
10.少用or;
小总结
order by 优化
使用order by 排序,尽量用 index 也就是索引排序,避免文件排序。
其实就是,where 条件和 order by条件组合起来符合最左前列原则,就可以是 索引排序,需要注意的是,where 条件 的顺序可以被数据库根据索引自行优化,但是 order by 不行,顺序必须一致,当然我们推荐全都和索引顺序一致。
如果使用order by , 不要使用select *,只查询你需要的字段。
小总结

group by 优化
几乎与order by 一致
group by 实质是先排序,再分组,可以遵照最左前列的原则;
只需要注意一点,where 优先级高于having,能写在where里的条件,就不要写到having里。
小表驱动大表
这里引申出 in ,exists,join的问题,因为这几个基本可以相互替换使用,特别是in 和 exists,join 通常是需要查询多表的数据才用。

说白了,用in的时候,内部的子查询先执行,外部的查询从子查询中筛选,用exists的时候,没有所谓的子查询,而是先执行A表的查询,结果集再去B表中验证ture/false,验证成功的返回,这两个明显是可以相互替换使用的,主要是优先让小表的查询先执行。
慢查询日志 (mysql)
作为开发很少用到,了解一下吧。
默认关闭,有需要时才开启,开始后设置。
SHOW VARIABLES LIKE '%slow_query_log%' :这个命令可以查看开启情况和日志所在位置。
SET GLOBAL slow_query_log = 1 : 设置为开启,但是用命令开启的话,只对当前数据库有效,并且在重启数据库服务后失效。
SHOW VARIABLES LIKE 'long_query_time%' :查看多少秒以上算“慢”,默认值是10,指大于10秒。
SET GLOBAL long_query_time = 3 :设置慢值,但是设置完后需要重新开启一个会话才能看见。
想要永久生效,需要修改配置文件,一般不建议,毕竟会影响性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号