

索引
1.什么是索引?
索引是帮助数据库高效获取数据的数据结构,本质是通过排序来快速查找。
除了数据,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式指向数据的地址(硬盘位置),这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
索引本身也很大,不可能全在内存中,所以往往也以索引文件的形式保存在磁盘上。
2.索引的作用?
排序 order by,搜索条件 where。
3.索引的数据结构是什么?
一般都是B+Tree(多路搜索树,不一定是二叉的),也有hash索引,full-text全文索引,r-tree索引。
4.索引的优势
4.1 类似图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本;
4.2 通过索引列对数据进行排序,降低了数据排序的成本,降低了cpu的消耗。
5.索引的劣势
5.1 索引其实也是一张表,存储了主键和索引字段,并指向实体表的记录,因此索引也是要占用空间的;
5.2 索引提高了查询速度,但是会降低写的操作,insert,update,delete等,因为这种操作会更新索引;
5.3 索引本身不是一劳永逸,需要根据需求的变化维护,提高了这块的成本。
6.索引的分类
6.1 单值索引:只包含一个列的索引,一个表可以有多个单列索引;
6.2 唯一索引:值必须唯一,但是可以为空;
6.3 复合索引:一个索引包含多个列,比较推荐使用,因为现在很少有单条件查找的情况。
7.索引原理(B+Tree)
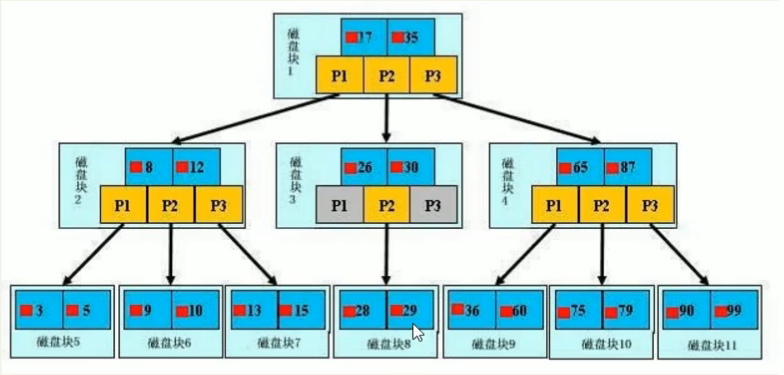
B+树,浅蓝色为磁盘块,每个磁盘块都有深蓝色的数据项和黄色的指针,如磁盘块1有数据项17,35和指针p1,p2,p3。
p1表示小于17的磁盘块2,p2表示17-35之间的磁盘块3,p3表示大于35的磁盘块4。
真实的数据,3,5,9,10,13,15....存在于叶子节点,非叶子节点存储的不是真实的数据,而是引导搜索方向的数据项,如17,35。
已查找29为例,首先加载磁盘1,发生1次IO,判断出29在17和35之间,于是锁定磁盘1的指针p2,通过磁盘1的p2指针的磁盘地址加载磁盘3,发生第2次IO,判断29在26和30之间,锁定磁盘3的指针p2,加载磁盘8,发生第3次IO,同时内存做二分查找查到29,结束查询,一共发生了3次IO。
8.索引适用的场景
8.1 主键自动是唯一索引;
8.2 频繁作为查询条件的字段;
8.3 频繁作为排序的字段;
8.4 查询中统计或分组的字段;
8.5 与其他表的关联字段。
9.索引不适用的场景
9.1 记录很少的表,几百上千万把条的,不需要特意建;
9.2 经常增删改的字段;
9.3 大量重复值的字段,没有意义,例如国籍,性别,省份这种。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号