java写parquet文件
https://blog.csdn.net/u012995897/article/details/76623739
打开ParquetWriter或者ParquetReader发现大部分构造方法都是过时的(@Deprecated),经过仔细的百度,和读源码,才发现原来创建ParquetWriter对象采用内部类Builder来build();
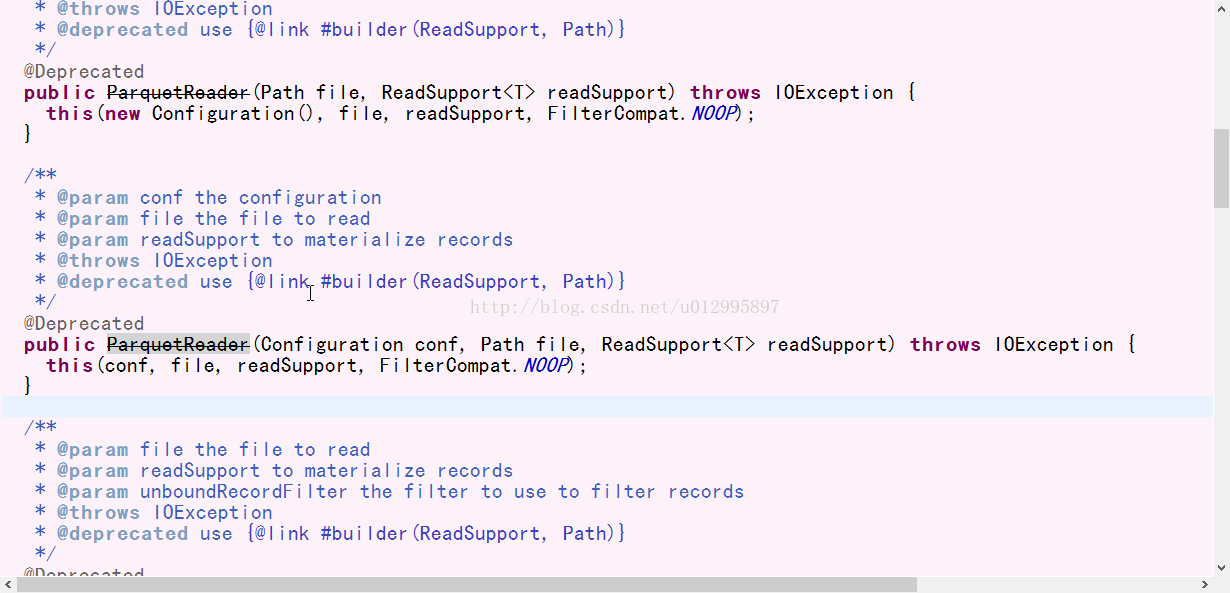
实例:(Apache parquet1.9.0)本次写入文件,没有保存到hdfs如果需要保存到hdfs,则需要配置hdfs配置文件。
/**
* 创建日期:2017-8-2
* 包路径:org.meter.parquet.TestParquetWriter.java
* 创建者:meter
* 描述:
* 版权:copyright@2017 by meter !
*/
package org.meter.parquet;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.parquet.column.ParquetProperties;
import org.apache.parquet.example.data.Group;
import org.apache.parquet.example.data.simple.SimpleGroup;
import org.apache.parquet.example.data.simple.SimpleGroupFactory;
import org.apache.parquet.format.converter.ParquetMetadataConverter;
import org.apache.parquet.hadoop.ParquetFileReader;
import org.apache.parquet.hadoop.ParquetFileWriter;
import org.apache.parquet.hadoop.ParquetReader;
import org.apache.parquet.hadoop.ParquetWriter;
import org.apache.parquet.hadoop.api.ReadSupport;
import org.apache.parquet.hadoop.example.ExampleParquetWriter;
import org.apache.parquet.hadoop.example.GroupReadSupport;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
import org.apache.parquet.hadoop.metadata.ParquetMetadata;
import org.apache.parquet.schema.MessageType;
import org.apache.parquet.schema.MessageTypeParser;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* @author meter
* 文件名:TestParquetWriter
* @描述:
*/
public class TestParquetWriter {
private static Logger logger = LoggerFactory
.getLogger(TestParquetWriter.class);
private static String schemaStr = "message schema {" + "optional int64 log_id;"
+ "optional binary idc_id;" + "optional int64 house_id;"
+ "optional int64 src_ip_long;" + "optional int64 dest_ip_long;"
+ "optional int64 src_port;" + "optional int64 dest_port;"
+ "optional int32 protocol_type;" + "optional binary url64;"
+ "optional binary access_time;}";
static MessageType schema =MessageTypeParser.parseMessageType(schemaStr);
/**
* 创建时间:2017-8-3
* 创建者:meter
* 返回值类型:void
* @描述:输出MessageType
*/
public static void testParseSchema(){
logger.info(schema.toString());
}
/**
* 创建时间:2017-8-3
* 创建者:meter
* 返回值类型:void
* @描述:获取parquet的Schema
* @throws Exception
*/
public static void testGetSchema() throws Exception {
Configuration configuration = new Configuration();
// windows 下测试入库impala需要这个配置
System.setProperty("hadoop.home.dir",
"E:\\mvtech\\software\\hadoop-common-2.2.0-bin-master");
ParquetMetadata readFooter = null;
Path parquetFilePath = new Path("file:///E:/mvtech/work/isms_develop/src/org/meter/parquet/2017-08-02-10_91014_DPI0801201708021031_470000.parq");
readFooter = ParquetFileReader.readFooter(configuration,
parquetFilePath, ParquetMetadataConverter.NO_FILTER);
MessageType schema =readFooter.getFileMetaData().getSchema();
logger.info(schema.toString());
}
/**
* 创建时间:2017-8-3
* 创建者:meter
* 返回值类型:void
* @描述:测试写parquet文件
* @throws IOException
*/
private static void testParquetWriter() throws IOException {
Path file = new Path(
"file:///C:\\Users\\meir\\Desktop\\linuxtetdir\\logtxt\\test.parq");
ExampleParquetWriter.Builder builder = ExampleParquetWriter
.builder(file).withWriteMode(ParquetFileWriter.Mode.CREATE)
.withWriterVersion(ParquetProperties.WriterVersion.PARQUET_1_0)
.withCompressionCodec(CompressionCodecName.SNAPPY)
//.withConf(configuration)
.withType(schema);
/*
* file, new GroupWriteSupport(), CompressionCodecName.SNAPPY, 256 *
* 1024 * 1024, 1 * 1024 * 1024, 512, true, false,
* ParquetProperties.WriterVersion.PARQUET_1_0, conf
*/
ParquetWriter<Group> writer = builder.build();
SimpleGroupFactory groupFactory = new SimpleGroupFactory(schema);
String[] access_log = { "111111", "22222", "33333", "44444", "55555",
"666666", "777777", "888888", "999999", "101010" };
for(int i=0;i<1000;i++){
writer.write(groupFactory.newGroup()
.append("log_id", Long.parseLong(access_log[0]))
.append("idc_id", access_log[1])
.append("house_id", Long.parseLong(access_log[2]))
.append("src_ip_long", Long.parseLong(access_log[3]))
.append("dest_ip_long", Long.parseLong(access_log[4]))
.append("src_port", Long.parseLong(access_log[5]))
.append("dest_port", Long.parseLong(access_log[6]))
.append("protocol_type", Integer.parseInt(access_log[7]))
.append("url64", access_log[8])
.append("access_time", access_log[9]));
}
writer.close();
}
/**
* 创建时间:2017-8-3
* 创建者:meter
* 返回值类型:void
* @throws IOException
* @描述:测试读parquet文件
*/
private static void testParquetReader() throws IOException{
Path file = new Path(
"file:///C:\\Users\\meir\\Desktop\\linuxtetdir\\logtxt\\test.parq");
ParquetReader.Builder<Group> builder = ParquetReader.builder(new GroupReadSupport(), file);
ParquetReader<Group> reader = builder.build();
SimpleGroup group =(SimpleGroup) reader.read();
logger.info("schema:"+group.getType().toString());
logger.info("idc_id:"+group.getString(1, 0));
}
/**
* 创建时间:2017-8-2 创建者:meter 返回值类型:void
*
* @描述:
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
//testGetSchema();
//testParseSchema();
//testParquetWriter();
testParquetReader();
}
}
所需jar包:
maven:
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-hadoop</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号