Spark RDDs vs DataFrames vs SparkSQL
简介
Spark的 RDD、DataFrame 和 SparkSQL的性能比较。
2方面的比较
-
单条记录的随机查找
-
aggregation聚合并且sorting后输出
使用以下Spark的三种方式来解决上面的2个问题,对比性能。
-
Using RDD’s
-
Using DataFrames
-
Using SparkSQL
数据源
-
在HDFS中3个文件中存储的9百万不同记录
- 每条记录11个字段
-
总大小 1.4 GB
实验环境
-
HDP 2.4
-
Hadoop version 2.7
-
Spark 1.6
-
HDP Sandbox
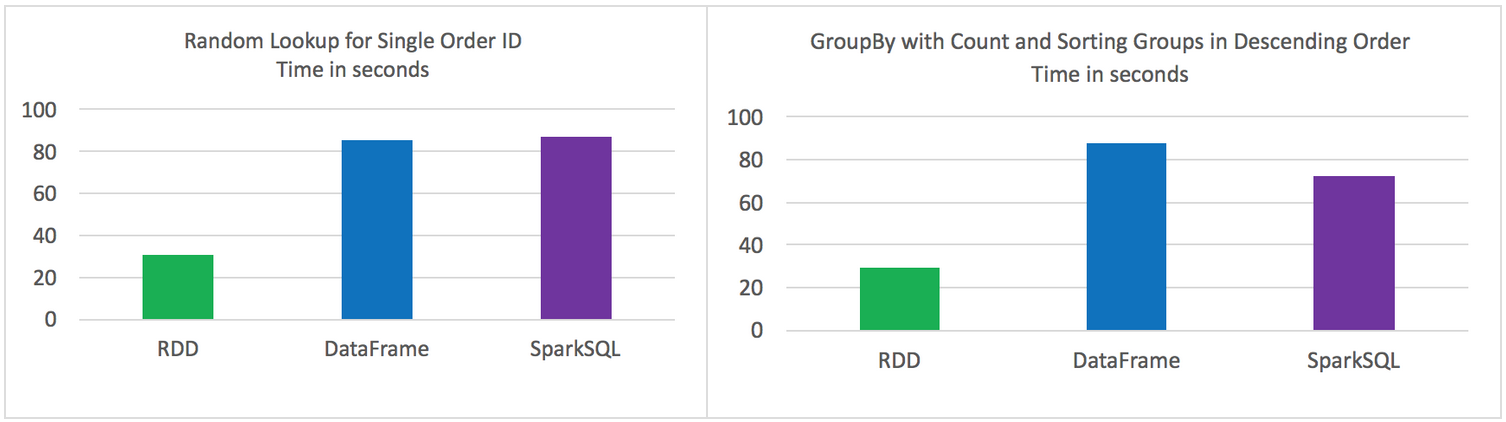
测试结果
-
原始的RDD 比 DataFrames 和 SparkSQL性能要好
-
DataFrames 和 SparkSQL 性能差不多
-
使用DataFrames 和 SparkSQL 比 RDD 操作更直观
-
Jobs都是独立运行,没有其他job的干扰
2个操作
-
Random lookup against 1 order ID from 9 Million unique order ID's
-
GROUP all the different products with their total COUNTS and SORT DESCENDING by product name
代码
RDD Random Lookup

#!/usr/bin/env python from time import time from pyspark import SparkConf, SparkContext conf = (SparkConf() .setAppName("rdd_random_lookup") .set("spark.executor.instances", "10") .set("spark.executor.cores", 2) .set("spark.dynamicAllocation.enabled", "false") .set("spark.shuffle.service.enabled", "false") .set("spark.executor.memory", "500MB")) sc = SparkContext(conf = conf) t0 = time() path = "/data/customer_orders*" lines = sc.textFile(path) ## filter where the order_id, the second field, is equal to 96922894 print lines.map(lambda line: line.split('|')).filter(lambda line: int(line[1]) == 96922894).collect() tt = str(time() - t0) print "RDD lookup performed in " + tt + " seconds"
DataFrame Random Lookup
#!/usr/bin/env python from time import time from pyspark.sql import * from pyspark import SparkConf, SparkContext conf = (SparkConf() .setAppName("data_frame_random_lookup") .set("spark.executor.instances", "10") .set("spark.executor.cores", 2) .set("spark.dynamicAllocation.enabled", "false") .set("spark.shuffle.service.enabled", "false") .set("spark.executor.memory", "500MB")) sc = SparkContext(conf = conf) sqlContext = SQLContext(sc) t0 = time() path = "/data/customer_orders*" lines = sc.textFile(path) ## create data frame orders_df = sqlContext.createDataFrame( \ lines.map(lambda l: l.split("|")) \ .map(lambda p: Row(cust_id=int(p[0]), order_id=int(p[1]), email_hash=p[2], ssn_hash=p[3], product_id=int(p[4]), product_desc=p[5], \ country=p[6], state=p[7], shipping_carrier=p[8], shipping_type=p[9], shipping_class=p[10] ) ) ) ## filter where the order_id, the second field, is equal to 96922894 orders_df.where(orders_df['order_id'] == 96922894).show() tt = str(time() - t0) print "DataFrame performed in " + tt + " seconds"
SparkSQL Random Lookup
#!/usr/bin/env python from time import time from pyspark.sql import * from pyspark import SparkConf, SparkContext conf = (SparkConf() .setAppName("spark_sql_random_lookup") .set("spark.executor.instances", "10") .set("spark.executor.cores", 2) .set("spark.dynamicAllocation.enabled", "false") .set("spark.shuffle.service.enabled", "false") .set("spark.executor.memory", "500MB")) sc = SparkContext(conf = conf) sqlContext = SQLContext(sc) t0 = time() path = "/data/customer_orders*" lines = sc.textFile(path) ## create data frame orders_df = sqlContext.createDataFrame( \ lines.map(lambda l: l.split("|")) \ .map(lambda p: Row(cust_id=int(p[0]), order_id=int(p[1]), email_hash=p[2], ssn_hash=p[3], product_id=int(p[4]), product_desc=p[5], \ country=p[6], state=p[7], shipping_carrier=p[8], shipping_type=p[9], shipping_class=p[10] ) ) ) ## register data frame as a temporary table orders_df.registerTempTable("orders") ## filter where the customer_id, the first field, is equal to 96922894 print sqlContext.sql("SELECT * FROM orders where order_id = 96922894").collect() tt = str(time() - t0) print "SparkSQL performed in " + tt + " seconds"
RDD with GroupBy, Count, and Sort Descending
#!/usr/bin/env python from time import time from pyspark import SparkConf, SparkContext conf = (SparkConf() .setAppName("rdd_aggregation_and_sort") .set("spark.executor.instances", "10") .set("spark.executor.cores", 2) .set("spark.dynamicAllocation.enabled", "false") .set("spark.shuffle.service.enabled", "false") .set("spark.executor.memory", "500MB")) sc = SparkContext(conf = conf) t0 = time() path = "/data/customer_orders*" lines = sc.textFile(path) counts = lines.map(lambda line: line.split('|')) \ .map(lambda x: (x[5], 1)) \ .reduceByKey(lambda a, b: a + b) \ .map(lambda x:(x[1],x[0])) \ .sortByKey(ascending=False) for x in counts.collect(): print x[1] + '\t' + str(x[0]) tt = str(time() - t0) print "RDD GroupBy performed in " + tt + " seconds"
DataFrame with GroupBy, Count, and Sort Descending
#!/usr/bin/env python from time import time from pyspark.sql import * from pyspark import SparkConf, SparkContext conf = (SparkConf() .setAppName("data_frame_aggregation_and_sort") .set("spark.executor.instances", "10") .set("spark.executor.cores", 2) .set("spark.dynamicAllocation.enabled", "false") .set("spark.shuffle.service.enabled", "false") .set("spark.executor.memory", "500MB")) sc = SparkContext(conf = conf) sqlContext = SQLContext(sc) t0 = time() path = "/data/customer_orders*" lines = sc.textFile(path) ## create data frame orders_df = sqlContext.createDataFrame( \ lines.map(lambda l: l.split("|")) \ .map(lambda p: Row(cust_id=int(p[0]), order_id=int(p[1]), email_hash=p[2], ssn_hash=p[3], product_id=int(p[4]), product_desc=p[5], \ country=p[6], state=p[7], shipping_carrier=p[8], shipping_type=p[9], shipping_class=p[10] ) ) ) results = orders_df.groupBy(orders_df['product_desc']).count().sort("count",ascending=False) for x in results.collect(): print x tt = str(time() - t0) print "DataFrame performed in " + tt + " seconds"
SparkSQL with GroupBy, Count, and Sort Descending
#!/usr/bin/env python from time import time from pyspark.sql import * from pyspark import SparkConf, SparkContext conf = (SparkConf() .setAppName("spark_sql_aggregation_and_sort") .set("spark.executor.instances", "10") .set("spark.executor.cores", 2) .set("spark.dynamicAllocation.enabled", "false") .set("spark.shuffle.service.enabled", "false") .set("spark.executor.memory", "500MB")) sc = SparkContext(conf = conf) sqlContext = SQLContext(sc) t0 = time() path = "/data/customer_orders*" lines = sc.textFile(path) ## create data frame orders_df = sqlContext.createDataFrame(lines.map(lambda l: l.split("|")) \ .map(lambda r: Row(product=r[5]))) ## register data frame as a temporary table orders_df.registerTempTable("orders") results = sqlContext.sql("SELECT product, count(*) AS total_count FROM orders GROUP BY product ORDER BY total_count DESC") for x in results.collect(): print x tt = str(time() - t0) print "SparkSQL performed in " + tt + " seconds"
原文:https://community.hortonworks.com/articles/42027/rdd-vs-dataframe-vs-sparksql.html
作者:阿凡卢
出处:https://www.cnblogs.com/luxiaoxun/p/6397996.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App