Kafka的Exactly-once语义与事务机制
Kafka 0.11.x版本(对应 Confluent Platform 3.3),该版本引入了exactly-once语义。
精确一次确实很难实现(Exactly-once is a really hard problem)
Mathias Verraes说,分布式系统中最难解决的两个问题是:
- 消息顺序保证(Guaranteed order of messages)。
- 消息的精确一次投递(Exactly-once delivery)。
消息系统语义概述(Overview of messaging system semantics)
在一个分布式发布订阅消息系统中,组成系统的计算机总会由于各自的故障而不能工作。在Kafka中,一个单独的broker,可能会在生产者发送消息到一个topic的时候宕机,或者出现网络故障,从而导致生产者发送消息失败。根据生产者如何处理这样的失败,产生了不同的语义:
- 至少一次语义(At least once semantics):如果生产者收到了Kafka broker的确认(acknowledgement,ack),并且生产者的acks配置项设置为all(或-1),这就意味着消息已经被精确一次写入Kafka topic了。然而,如果生产者接收ack超时或者收到了错误,它就会认为消息没有写入Kafka topic而尝试重新发送消息。如果broker恰好在消息已经成功写入Kafka topic后,发送ack前,出了故障,生产者的重试机制就会导致这条消息被写入Kafka两次,从而导致同样的消息会被消费者消费不止一次。每个人都喜欢一个兴高采烈的给予者,但是这种方式会导致重复的工作和错误的结果。
- 至多一次语义(At most once semantics):如果生产者在ack超时或者返回错误的时候不重试发送消息,那么消息有可能最终并没有写入Kafka topic中,因此也就不会被消费者消费到。但是为了避免重复处理的可能性,我们接受有些消息可能被遗漏处理。
- 精确一次语义(Exactly once semantics): 即使生产者重试发送消息,也只会让消息被发送给消费者一次。精确一次语义是最令人满意的保证,但也是最难理解的。因为它需要消息系统本身和生产消息的应用程序还有消费消息的应用程序一起合作。比如,在成功消费一条消息后,你又把消费的offset重置到之前的某个offset位置,那么你将收到从那个offset到最新的offset之间的所有消息。这解释了为什么消息系统和客户端程序必须合作来保证精确一次语义。
必须被处理的故障(Failures that must be handled)
为了描述为了支持精确一次消息投递语义而引入的挑战,让我们从一个简单的例子开始。
假设有一个单进程生产者程序,发送了消息“Hello Kafka“给一个叫做“EoS“的单分区Kafka topic。然后有一个单实例的消费者程序在另一端从topic中拉取消息,然后打印。在没有故障的理想情况下,这能很好的工作,“Hello Kafka“只被写入到EoS topic一次。消费者拉取消息,处理消息,提交偏移量来说明它完成了处理。然后,即使消费者程序出故障重启也不会再收到“Hello Kafka“这条消息了。
然而,我们知道,我们不能总认为一切都是顺利的。在上规模的集群中,即使最不可能发生的故障场景都可能最终发生。比如:
- broker可能故障:Kafka是一个高可用、持久化的系统,每一条写入一个分区的消息都会被持久化并且多副本备份(假设有n个副本)。所以,Kafka可以容忍n-1个broker故障,意味着一个分区只要至少有一个broker可用,分区就可用。Kafka的副本协议保证了只要消息被成功写入了主副本,它就会被复制到其他所有的可用副本(ISR)。
- producer到broker的RPC调用可能失败:Kafka的持久性依赖于生产者接收broker的ack。没有接收成功ack不代表生产请求本身失败了。broker可能在写入消息后,发送ack给生产者的时候挂了。甚至broker也可能在写入消息前就挂了。由于生产者没有办法知道错误是什么造成的,所以它就只能认为消息没写入成功,并且会重试发送。在一些情况下,这会造成同样的消息在Kafka分区日志中重复,进而造成消费端多次收到这条消息。
- 客户端可能会故障:精确一次交付也必须考虑客户端故障。但是我们如何知道一个客户端已经故障而不是暂时和brokers断开,或者经历一个程序短暂的暂停?区分永久性故障和临时故障是很重要的,为了正确性,broker应该丢弃僵住的生产者发送来的消息,同样,也应该不向已经僵住的消费者发送消息。一旦一个新的客户端实例启动,它应该能够从失败的实例留下的任何状态中恢复,从一个安全点开始处理。这意味着,消费的偏移量必须始终与生产的输出保持同步。
Kafka的exactly-once语义
在0.11.x版本之前,Apache Kafka支持at-least-once delivery语义以及partition内部的顺序delivery,如前所述这在某些场景下可能会导致数据重复消费。而Kafka 0.11.x支持exactly-once语义,不会导致该情况发生,其中主要包括三个内部逻辑的改造:
幂等:partition内部的exactly-once顺序语义
幂等操作,是指可以执行多次,而不会产生与仅执行一次不同结果的操作,Producer的send操作现在是幂等的。在任何导致producer重试的情况下,相同的消息,如果被producer发送多次,也只会被写入Kafka一次。要打开此功能,并让所有partition获得exactly-once delivery、无数据丢失和in-order语义,需要修改broker的配置:enable.idempotence = true。
这个功能如何工作?它的工作方式类似于TCP:发送到Kafka的每批消息将包含一个序列号,该序列号用于重复数据的删除。与TCP不同,TCP只能在transient in-memory中提供保证。序列号将被持久化存储topic中,因此即使leader replica失败,接管的任何其他broker也将能感知到消息是否重复。
这种机制的开销相当低:它只是在每批消息中添加了几个额外字段:
- PID,在Producer初始化时分配,作为每个Producer会话的唯一标识;
- 序列号(sequence number),Producer发送的每条消息(更准确地说是每一个消息批次,即ProducerBatch)都会带有此序列号,从0开始单调递增。Broker根据它来判断写入的消息是否可接受。
事务:跨partition的原子性写操作
第二点,Kafka现在支持使用新事务API原子性的对跨partition进行写操作,该API允许producer发送批量消息到多个partition。该功能同样支持在同一个事务中提交消费者offsets,因此真正意义上实现了end-to-end的exactly-once delivery语义。以下是一段示例代码:

producer.initTransactions(); try { producer.beginTransaction(); producer.send(record1); producer.send(record2); producer.commitTransaction(); } catch(ProducerFencedException e) { producer.close(); } catch(KafkaException e) { producer.abortTransaction(); }
该代码片段描述了如何使用新的producer事务API原子性的发送消息至多个partition。值得注意的是,某个Kafka topic partition内部的消息可能是事务完整提交后的消息,也可能是事务执行过程中的部分消息。
而从consumer的角度来看,有两种策略去读取事务写入的消息,通过"isolation.level"来进行配置:
-
read_committed:可以同时读取事务执行过程中的部分写入数据和已经完整提交的事务写入数据; -
read_uncommitted:完全不等待事务提交,按照offsets order去读取消息,也就是兼容0.11.x版本前Kafka的语义;
我们必须通过配置consumer端的配置isolation.level,来正确使用事务API,通过使用 new Producer API并且对一些unique ID设置transaction.id(该配置属于producer端),该unique ID用于提供事务状态的连续性。
Exactly-once 流处理
基于幂等和原子性,通过Streams API实现exactly-once流处理成为可能。如果要在流应用中实现相关语义,只需要配置 processing.guarantee=exactly_once,这会影响所有的流处理环境中的语义,包括将处理作业和由加工作业创建的所有物理状态同时写回到Kafka的操作。
事务机制原理
事务性消息传递
这一节所说的事务主要指原子性,也即Producer将多条消息作为一个事务批量发送,要么全部成功要么全部失败。
为了实现这一点,Kafka 0.11.0.0引入了一个服务器端的模块,名为Transaction Coordinator,用于管理Producer发送的消息的事务性。
该Transaction Coordinator维护Transaction Log,该log存于一个内部的Topic内。由于Topic数据具有持久性,因此事务的状态也具有持久性。
Producer并不直接读写Transaction Log,它与Transaction Coordinator通信,然后由Transaction Coordinator将该事务的状态插入相应的Transaction Log。
Transaction Log的设计与Offset Log用于保存Consumer的Offset类似。
事务中Offset的提交
许多基于Kafka的应用,尤其是Kafka Stream应用中同时包含Consumer和Producer,前者负责从Kafka中获取消息,后者负责将处理完的数据写回Kafka的其它Topic中。
为了实现该场景下的事务的原子性,Kafka需要保证对Consumer Offset的Commit与Producer对发送消息的Commit包含在同一个事务中。否则,如果在二者Commit中间发生异常,根据二者Commit的顺序可能会造成数据丢失和数据重复:
-
如果先Commit Producer发送数据的事务再Commit Consumer的Offset,即
At Least Once语义,可能造成数据重复。 -
如果先Commit Consumer的Offset,再Commit Producer数据发送事务,即
At Most Once语义,可能造成数据丢失。
用于事务特性的控制型消息
为了区分写入Partition的消息被Commit还是Abort,Kafka引入了一种特殊类型的消息,即Control Message。该类消息的Value内不包含任何应用相关的数据,并且不会暴露给应用程序。它只用于Broker与Client间的内部通信。
对于Producer端事务,Kafka以Control Message的形式引入一系列的Transaction Marker。Consumer即可通过该标记判定对应的消息被Commit了还是Abort了,然后结合该Consumer配置的隔离级别决定是否应该将该消息返回给应用程序。
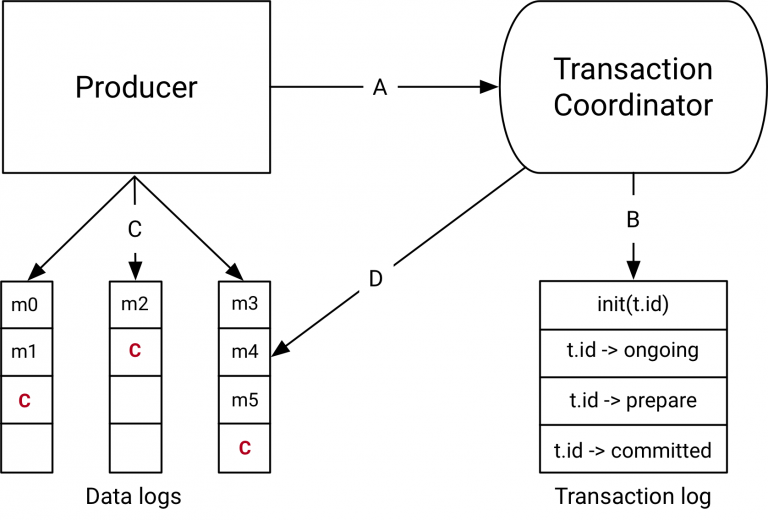
Data flow#
At a high level, the data flow can be broken into four distinct types.
A: the producer and transaction coordinator interaction#
When executing transactions, the producer makes requests to the transaction coordinator at the following points:
- The initTransactions API registers a transactional.id with the coordinator. At this point, the coordinator closes any pending transactions with that transactional.id and bumps the epoch to fence out zombies. This happens only once per producer session.
- When the producer is about to send data to a partition for the first time in a transaction, the partition is registered with the coordinator first.
- When the application calls commitTransaction or abortTransaction, a request is sent to the coordinator to begin the two phase commit protocol.
B: the coordinator and transaction log interaction#
As the transaction progresses, the producer sends the requests above to update the state of the transaction on the coordinator. The transaction coordinator keeps the state of each transaction it owns in memory, and also writes that state to the transaction log (which is replicated three ways and hence is durable).
The transaction coordinator is the only component to read and write from the transaction log. If a given broker fails, a new coordinator is elected as the leader for the transaction log partitions the dead broker owned, and it reads the messages from the incoming partitions to rebuild its in-memory state for the transactions in those partitions.
C: the producer writing data to target topic-partitions#
After registering new partitions in a transaction with the coordinator, the producer sends data to the actual partitions as normal. This is exactly the same producer.send flow, but with some extra validation to ensure that the producer isn’t fenced.
D: the coordinator to topic-partition interaction#
After the producer initiates a commit (or an abort), the coordinator begins the two phase commit protocol.
In the first phase, the coordinator updates its internal state to “prepare_commit” and updates this state in the transaction log. Once this is done the transaction is guaranteed to be committed no matter what.
The coordinator then begins phase 2, where it writes transaction commit markers to the topic-partitions which are part of the transaction.
These transaction markers are not exposed to applications, but are used by consumers in read_committed mode to filter out messages from aborted transactions and to not return messages which are part of open transactions (i.e., those which are in the log but don’t have a transaction marker associated with them).
Once the markers are written, the transaction coordinator marks the transaction as “complete” and the producer can start the next transaction.
事务处理样例代码:
Producer<String, String> producer = new KafkaProducer<String, String>(props); // 初始化事务,包括结束该Transaction ID对应的未完成的事务(如果有) // 保证新的事务在一个正确的状态下启动 producer.initTransactions(); // 开始事务 producer.beginTransaction(); // 消费数据 ConsumerRecords<String, String> records = consumer.poll(100); try{ // 发送数据 producer.send(new ProducerRecord<String, String>("Topic", "Key", "Value")); // 发送消费数据的Offset,将上述数据消费与数据发送纳入同一个Transaction内 producer.sendOffsetsToTransaction(offsets, "group1"); // 数据发送及Offset发送均成功的情况下,提交事务 producer.commitTransaction(); } catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) { // 数据发送或者Offset发送出现异常时,终止事务 producer.abortTransaction(); } finally { // 关闭Producer和Consumer producer.close(); consumer.close(); }
参考:
Kafka 0.11.0.0 是如何实现 Exactly-once 语义的
Kafka设计解析(八)- Exactly Once语义与事务机制原理
https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
https://www.confluent.io/blog/transactions-apache-kafka/
作者:阿凡卢
出处:https://www.cnblogs.com/luxiaoxun/p/13048474.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App