flink任务性能优化
如何提高 Flink 任务性能
一、Operator Chain
为了更高效地分布式执行,Flink 会尽可能地将 operator 的 subtask 链接(chain)在一起形成 task,每个 task 在一个线程中执行。将 operators 链接成 task 是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。
Flink 会在生成 JobGraph 阶段,将代码中可以优化的算子优化成一个算子链(Operator Chains)以放到一个 task(一个线程)中执行,以减少线程之间的切换和缓冲的开销,提高整体的吞吐量和延迟。下面以官网中的例子进行说明。
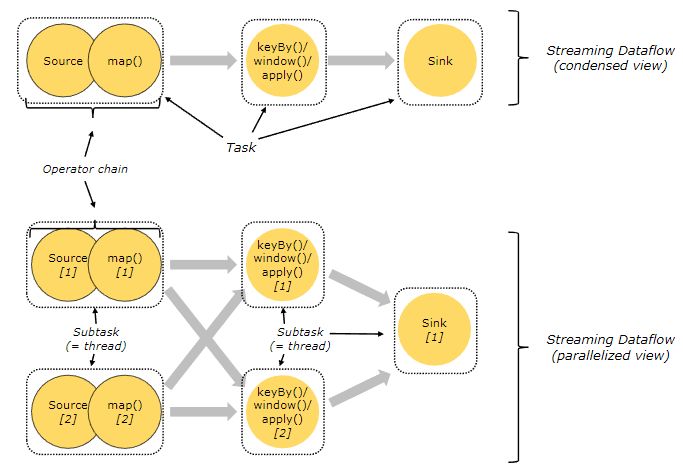
上图中,source、map、[keyBy|window|apply]、sink 算子的并行度分别是 2、2、2、1,经过 Flink 优化后,source 和 map 算子组成一个算子链,作为一个 task 运行在一个线程上,其简图如图中 condensed view 所示,并行图如 parallelized view 所示。算子之间是否可以组成一个Operator Chains,看是否满足以下条件:
- 上下游算子的并行度一致;
- 上下游节点都在同一个slot group 中;
- 下游节点的chain策略为ALWAYS;
- 上游节点的chain策略为ALWAYS或HEAD;
- 两个节点间数据分区方式是forward;
- 用户没有禁用chain。
二、Slot Sharing
Slot Sharing 是指,来自同一个 Job 且拥有相同 slotSharingGroup(默认:default)名称的不同 Task 的 SubTask 之间可以共享一个 Slot,这使得一个 Slot 有机会持有 Job 的一整条 Pipeline,这也是上文提到的在默认 slotSharing 的条件下 Job 启动所需的 Slot 数和 Job 中 Operator 的最大 parallelism 相等的原因。通过 Slot Sharing 机制可以更进一步提高 Job 运行性能,在 Slot 数不变的情况下增加了 Operator 可设置的最大的并行度,让类似 window 这种消耗资源的 Task 以最大的并行度分布在不同 TM 上,同时像 map、filter 这种较简单的操作也不会独占 Slot 资源,降低资源浪费的可能性。
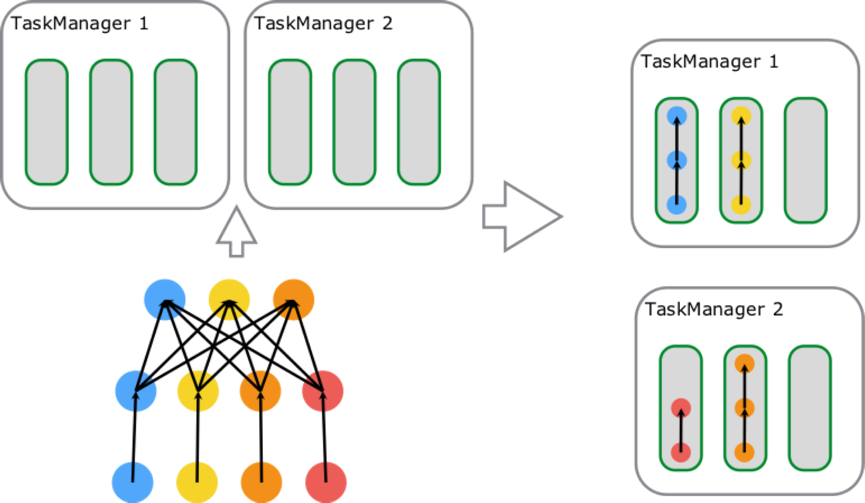
图中包含 source-map[6 parallelism]、keyBy/window/apply[6 parallelism]、sink[1 parallelism] 三种 Task,总计占用了 6 个 Slot;由左向右开始第一个 slot 内部运行着 3 个 SubTask[3 Thread],持有 Job 的一条完整 pipeline;剩下 5 个 Slot 内分别运行着 2 个 SubTask[2 Thread],数据最终通过网络传递给 Sink 完成数据处理。
三、Flink 异步 IO
流式计算中,常常需要与外部系统进行交互,而往往一次连接中你那个获取连接等待通信的耗时会占比较高。下图是两种方式对比示例:
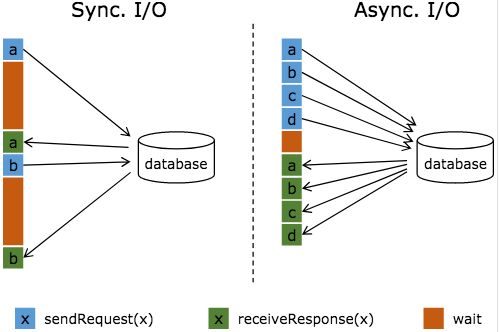
图中棕色的长条表示等待时间,可以发现网络等待时间极大地阻碍了吞吐和延迟。为了解决同步访问的问题,异步模式可以并发地处理多个请求和回复。也就是说,你可以连续地向数据库发送用户 a、b、c 等的请求,与此同时,哪个请求的回复先返回了就处理哪个回复,从而连续的请求之间不需要阻塞等待,如上图右边所示。这也正是 Async I/O 的实现原理。
四、数据倾斜
1、定位反压
Flink Web UI 自带的反压监控(直接方式)、Flink Task Metrics(间接方式)。通过监控反压的信息,可以获取到数据处理瓶颈的 Subtask。
2、确定数据倾斜
Flink Web UI 自带Subtask 接收和发送的数据量。当 Subtasks 之间处理的数据量有较大的差距,则该 Subtask 出现数据倾斜。
解决
1、数据源 source 消费不均匀
通过调整Flink并行度,解决数据源消费不均匀或者数据源反压的情况。例如kafka数据源,调整并行度的原则:Source并行度与 kafka分区数是一样的,或者 kafka 分区数是KafkaSource 并发度的整数倍,建议是并行度等于分区数。
2、key 分布不均匀
上游数据分布不均匀,使用keyBy来打散数据的时候出现倾斜。通过添加随机前缀,打散 key 的分布,使得数据不会集中在几个 Subtask。
两阶段聚合解决 KeyBy(加盐局部聚合+去盐全局聚合) 预聚合:加盐局部聚合,在原来的 key 上加随机的前缀或者后缀。聚合:去盐全局聚合,删除预聚合添加的前缀或者后缀,然后进行聚合统计。
五、Checkpoint 优化
Flink 实现了一套强大的 checkpoint 机制,使它在获取高吞吐量性能的同时,也能保证 Exactly Once 级别的快速恢复。
首先提升各节点 checkpoint 的性能考虑的就是存储引擎的执行效率。Flink官方支持的三种 checkpoint state 存储方案中,Memory 仅用于调试级别,无法做故障后的数据恢复。其次还有 Hdfs 与 Rocksdb,当所做 Checkpoint 的数据大小较大时,可以考虑采用 Rocksdb 来作为 checkpoint 的存储以提升效率。
其次的思路是资源设置,我们都知道 checkpoint 机制是在每个 task 上都会进行,那么当总的状态数据大小不变的情况下,如何分配减少单个 task 所分的 checkpoint 数据变成了提升 checkpoint 执行效率的关键。
最后,增量快照。非增量快照下,每次 checkpoint 都包含了作业所有状态数据。而大部分场景下,前后 checkpoint 里,数据发生变更的部分相对很少,所以设置增量 checkpoint,仅会对上次 checkpoint 和本次 checkpoint 之间状态的差异进行存储计算,减少了 checkpoint 的耗时。
使用 checkpoint 的使用建议
■ Checkpoint 间隔不要太短
虽然理论上 Flink 支持很短的 checkpoint 间隔,但是在实际生产中,过短的间隔对于底层分布式文件系统而言,会带来很大的压力。另一方面,由于检查点的语义,所以实际上 Flink 作业处理 record 与执行 checkpoint 存在互斥锁,过于频繁的 checkpoint,可能会影响整体的性能。当然,这个建议的出发点是底层分布式文件系统的压力考虑。
■ 合理设置超时时间
默认的超时时间是 10min,如果 state 规模大,则需要合理配置。最坏情况是分布式地创建速度大于单点(job master 端)的删除速度,导致整体存储集群可用空间压力较大。建议当检查点频繁因为超时而失败时,增大超时时间。
六、资源配置
1、并行度(parallelism):保证足够的并行度,并行度也不是越大越好,太多会加重数据在多个solt/task manager之间数据传输压力,包括序列化和反序列化带来的压力。
2、CPU:CPU资源是task manager上的solt共享的,注意监控CPU的使用。
3、内存:内存是分solt隔离使用的,注意存储大state的时候,内存要足够。
4、网络:大数据处理,flink节点之间数据传输会很多,服务器网卡尽量使用万兆网卡。
总结
Operator Chain 是将多个 Operator 链接在一起放置在一个 Task 中,只针对 Operator。Slot Sharing 是在一个 Slot 中执行多个 Task,针对的是 Operator Chain 之后的 Task。这两种优化都充分利用了计算资源,减少了不必要的开销,提升了 Job 的运行性能。异步IO能解决需要高效访问其他系统的问题,提升任务执行的性能。Checkpoint优化是集群配置上的优化,提升集群本身的处理能力。
参考:
https://www.infoq.cn/article/ZmL7TCcEchvANY-9jG1H
https://blog.icocoro.me/2019/06/10/1906-apache-flink-asyncio/
作者:阿凡卢
出处:https://www.cnblogs.com/luxiaoxun/p/12114728.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App