Linux3.10.0块IO子系统流程(5)-- 为SCSI命令准备聚散列表
SCSI数据缓冲区组织成聚散列表的形式。Linux内核中表示聚散列表的基本数据结构是scatterlist,虽然名字中有list,但它只对应一个内存缓冲区,聚散列表就是多个scatterlist的组合。这种组合是链表+数组的结合。这是因为他使用的内存以页面为基本单位分配,每个页面相当于一个scatterlist。每个scatterlist以链表方式组织起来。
1 /* 2 * Function: scsi_init_io() 3 * 4 * Purpose: SCSI I/O initialize function. 5 * 6 * Arguments: cmd - Command descriptor we wish to initialize 7 * 8 * Returns: 0 on success 9 * BLKPREP_DEFER if the failure is retryable 10 * BLKPREP_KILL if the failure is fatal 11 */ 12 int scsi_init_io(struct scsi_cmnd *cmd, gfp_t gfp_mask) 13 { 14 struct request *rq = cmd->request; 15 16 // 初始化sg列表 17 int error = scsi_init_sgtable(rq, &cmd->sdb, gfp_mask); 18 if (error) 19 goto err_exit; 20 21 // 如果是双向请求,则为关联的request分配SCSI数据缓冲区,用于另一方向的数据传输,然后调用scsi_init_sgtable分配聚散列表,最后进行映射 22 if (blk_bidi_rq(rq)) { 23 struct scsi_data_buffer *bidi_sdb = kmem_cache_zalloc( 24 scsi_sdb_cache, GFP_ATOMIC); 25 if (!bidi_sdb) { 26 error = BLKPREP_DEFER; 27 goto err_exit; 28 } 29 30 rq->next_rq->special = bidi_sdb; 31 error = scsi_init_sgtable(rq->next_rq, bidi_sdb, GFP_ATOMIC); 32 if (error) 33 goto err_exit; 34 } 35 36 /* 37 * 如果是完整性请求,即原始bio中带有完整性载荷,则调用blk_rq_count_integrity_sg计算完整性数据段的数目 38 * 然后调用scsi_alloc_sgtable分配聚散列表,再调用blk_rq_map_integrity_sg将完整性数据映射到这个聚散列表,最后更新聚散列表已映射的项数 39 * 实际上,完整性请求的处理过程概括了scsi_init_sgtable的操作流程,它实际上是这个过程的一个封装 40 * 即调用scsi_alloc_sgtable分配指定数据数据段的聚散列表,然后调用blk_rq_map_sg进行映射,最后更新列表已映射的项数 41 */ 42 if (blk_integrity_rq(rq)) { 43 struct scsi_data_buffer *prot_sdb = cmd->prot_sdb; 44 int ivecs, count; 45 46 BUG_ON(prot_sdb == NULL); 47 ivecs = blk_rq_count_integrity_sg(rq->q, rq->bio); 48 49 if (scsi_alloc_sgtable(prot_sdb, ivecs, gfp_mask)) { 50 error = BLKPREP_DEFER; 51 goto err_exit; 52 } 53 54 count = blk_rq_map_integrity_sg(rq->q, rq->bio, 55 prot_sdb->table.sgl); 56 BUG_ON(unlikely(count > ivecs)); 57 BUG_ON(unlikely(count > queue_max_integrity_segments(rq->q))); 58 59 cmd->prot_sdb = prot_sdb; 60 cmd->prot_sdb->table.nents = count; 61 } 62 63 return BLKPREP_OK ; 64 65 err_exit: 66 scsi_release_buffers(cmd); 67 cmd->request->special = NULL; 68 scsi_put_command(cmd); 69 return error; 70 }
blk_rq_map_sg函数如下:
1 /* 2 * map a request to scatterlist, return number of sg entries setup. Caller 3 * must make sure sg can hold rq->nr_phys_segments entries 4 */ 5 int blk_rq_map_sg(struct request_queue *q, struct request *rq, 6 struct scatterlist *sglist) 7 { 8 struct bio_vec *bvec, *bvprv; 9 struct req_iterator iter; 10 struct scatterlist *sg; 11 int nsegs, cluster; 12 13 nsegs = 0; 14 cluster = blk_queue_cluster(q); 15 16 /* 17 * for each bio in rq 18 */ 19 bvprv = NULL; 20 sg = NULL; 21 rq_for_each_segment(bvec, rq, iter) { 22 __blk_segment_map_sg(q, bvec, sglist, &bvprv, &sg, 23 &nsegs, &cluster); 24 } /* segments in rq */ 25 26 27 if (unlikely(rq->cmd_flags & REQ_COPY_USER) && 28 (blk_rq_bytes(rq) & q->dma_pad_mask)) { 29 unsigned int pad_len = 30 (q->dma_pad_mask & ~blk_rq_bytes(rq)) + 1; 31 32 sg->length += pad_len; 33 rq->extra_len += pad_len; 34 } 35 36 if (q->dma_drain_size && q->dma_drain_needed(rq)) { 37 if (rq->cmd_flags & REQ_WRITE) 38 memset(q->dma_drain_buffer, 0, q->dma_drain_size); 39 40 sg->page_link &= ~0x02; 41 sg = sg_next(sg); 42 sg_set_page(sg, virt_to_page(q->dma_drain_buffer), 43 q->dma_drain_size, 44 ((unsigned long)q->dma_drain_buffer) & 45 (PAGE_SIZE - 1)); 46 nsegs++; 47 rq->extra_len += q->dma_drain_size; 48 } 49 50 if (sg) 51 sg_mark_end(sg); 52 53 return nsegs; 54 }
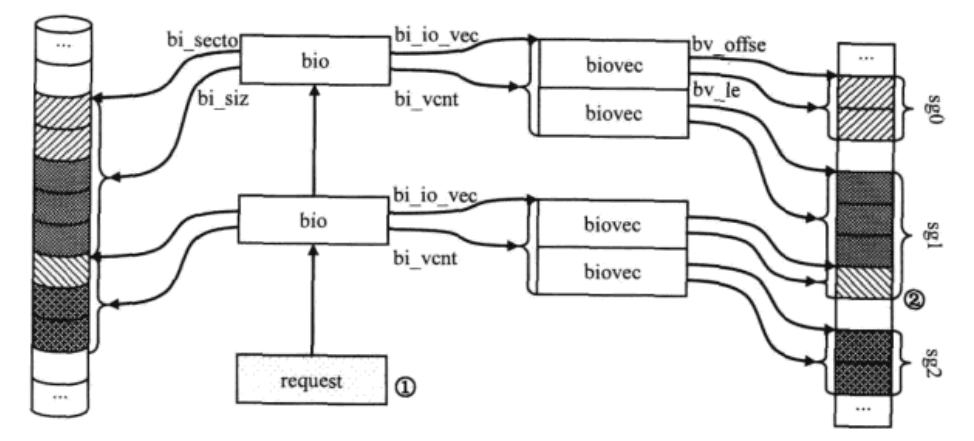
在bio处理过程中的两次合并,第一个合并由IO调度算法负责,它将在磁盘扇区上连续的请求合并到一个request中。第二次合并出现在SCSI策略例程,如果低层驱动支持,则进而将内存中连续的段合并为聚散列表中的一项,如下图,两个bio(每个bio有两段请求)在经过两个合并之后,聚散列表最终有三个项目。
-------------------------------------------------- 少年应是春风和煦,肩头挑着草长莺飞 --------------------------------------------------

