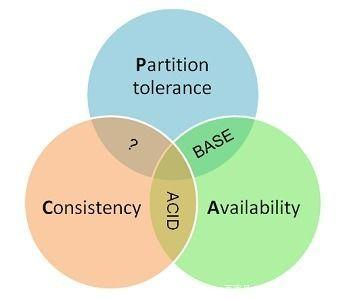
CAP和BASE理论
CAP理论概述
CAP理论作为分布式系统的基础理论,它描述的是一个分布式系统在以下三个特性中:
- 一致性(Consistency)
- 可用性(Availability)
- 分区容错性(Partition tolerance)
最多满足其中的两个特性。也就是下图所描述的。分布式系统要么满足CA,要么CP,要么AP。无法同时满足CAP。

什么是一致性、可用性和分区容错性
分区容错性:指的分布式系统中的某个节点或者网络分区出现了故障的时候,整个系统仍然能对外提供满足一致性和可用性的服务。
也就是说部分故障不影响整体使用。
事实上我们在设计分布式系统是都会考虑到bug,硬件,网络等各种原因造成的故障,所以即使部分节点或者网络出现故障,我们要求整个系统还是要继续使用的
一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立。CAP 定理告诉我们,剩下的 C 和 A 无法同时做到。
可用性: 意思是只要收到用户的请求,服务器就必须给出回应
一致性:在分布式系统完成某写操作后任何读操作,都应该获取到该写操作写入的那个最新的值。相当于要求分布式系统中的各节点时时刻刻保持数据的一致性。
该怎么理解
如果我们事先保证了分区容错性,也意味着若某个节点故障了,用户还是可以继续访问。这时用户在访问过程中就会出现一致性和可用性不能同时满足的情况,参考下图:


如图假设分布式系统有G1,G2两个节点,初始值都是v0。
现在有一个client向系统写入了值v1,这里假设直接写的是节点G1。写完之后client再去读取这个值,这时读到了G2节点,
由于G2节点与G1节点失去连接,这时G1节点上的数据还未同步到G2节点,因此客户端读取到的是修改之前的值v0。
这就出现了不满足一致性的情况了。相当于满足了可用性,失去了一致性。
类似的,如果系统保证了强的一致性,那么在client 写完G1节点后, 而G1向G2节点同步数据出现了问题,
这时如果client再去读取G2节点的数据时,client就会一直处于等待状态,因为系统内各节点数据为同步上,需要等同步上才能使用。
这就相当于满足了一致性,而失去了可用性。

考虑多个客户端访问时,一致性和可用性还可以这么理解:
假如client1 向G1 修改某个值的时候, 写操作还未完成
client2就发起来对该值的读操作,读的是G2节点,这时如果要满足一致性,
那么就得让client2 暂时无法使用,如果要让client2 使用,那么获取到的数据不是最新的,系统就不满足一致性。
CAP三者不可兼得,该如何取舍
(1) CA: 优先保证一致性和可用性,放弃分区容错。 这也意味着放弃系统的扩展性,系统不再是分布式的,有违设计的初衷。(2) CP: 优先保证一致性和分区容错性,放弃可用性。在数据一致性要求比较高的场合(譬如:zookeeper,Hbase) 是比较常见的做法,一旦发生网络故障或者消息丢失,就会牺牲用户体验,等恢复之后用户才逐渐能访问。
(3) AP: 优先保证可用性和分区容错性,放弃一致性。NoSQL中的Cassandra 就是这种架构。跟CP一样,放弃一致性不是说一致性就不保证了,而是逐渐的变得一致。
BASE理论
BASE理论是AP系统的补充理论
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的缩写。
BASE理论是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于CAP定理逐步演化而来的。
BASE理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
接下来看一下BASE中的三要素:
1、基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性----注意,这绝不等价于系统不可用。比如:
(1)响应时间上的损失。正常情况下,一个在线搜索引擎需要在0.5秒之内返回给用户相应的查询结果,但由于出现故障,查询结果的响应时间增加了1~2秒
(2)系统功能上的损失:正常情况下,在一个电子商务网站上进行购物的时候,消费者几乎能够顺利完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面
2、软状态
软状态指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时
3、最终一致性
最终一致性强调的是所有的数据副本,在经过一段时间的同步之后,最终都能够达到一个一致的状态。
因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
总的来说,BASE理论面向的是大型高可用可扩展的分布式系统,和传统的事物ACID特性是相反的
它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。
但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性和BASE理论往往又会结合在一起。
补充
事务具有4个特征,分别是原子性、一致性、隔离性和持久性,简称事务的ACID特性;
一、原子性(atomicity)
一个事务要么全部提交成功,要么全部失败回滚,不能只执行其中的一部分操作,这就是事务的原子性
二、一致性(consistency)
事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态。
如果数据库系统在运行过程中发生故障,有些事务尚未完成就被迫中断,这些未完成的事务对数据库所作的修改有一部分已写入物理数据库,这是数据库就处于一种不正确的状态,也就是不一致的状态
三、隔离性(isolation)
事务的隔离性是指在并发环境中,并发的事务时相互隔离的,一个事务的执行不能不被其他事务干扰。
不同的事务并发操作相同的数据时,每个事务都有各自完成的数据空间,即一个事务内部的操作及使用的数据对其他并发事务时隔离的,并发执行的各个事务之间不能相互干扰。
四、持久性(durability)
一旦事务提交,那么它对数据库中的对应数据的状态的变更就会永久保存到数据库中。
即使发生系统崩溃或机器宕机等故障,只要数据库能够重新启动,那么一定能够将其恢复到事务成功结束的状态
