Linux IO操作应用编程基础
1. 文件IO
本节函数和代码基于 Ubuntu16.04,内核版本:4.4.0-34-generic
1.1 文件描述符
对于内核而言,所有打开的文件都通过文件描述符引用。文件描述符是一个非负整数。当打开一个现有文件或创建一个新文件时,内核向进程返回一个文件描述符。当读写一个文件时,使用open或creat返回的文件描述符标识该文件,将其作为参数传送给read或write。
按照惯例,Unix系统shell把文件描述符 0 与进程的标准输入关联,文件描述符 1 与标准输出关联,文件描述符 2 与标准错误关联。文件描述符的变化范围为 0 ~ OPEN_MAX - 1
1.2 文件模式
文件模式是文件属性之一,占 16 bit
1 ) 访问权限占 9 bit,格式为 rwx rwx rwx,r 代表可读,w 代表可写,x 代表可执行,三组分别为文件拥有者、同组用户和其他用户的权限。
在创建文件和目录时制定权限,但是会被umask修改。umask是新创建文件、目录应关闭权限的位掩码。可以理解为r=4,w=2,x=1,则一个文件最高的权限为777。如umask是 0022,那么新创建不可执行文件的权限为 0644,目录为 755。
常见的几种umask值为 002、022 和 027,002 阻止其他用户写入你的文件,022 阻止同组成员和其他用户写入你的文件,027 阻止同组成员写入你的文件以及其他用户读、写或执行你的文件。
2 ) 修饰位占 3 bit,设置UID位,设置GID位,粘着位
3 )文件类型占 4 bit,区分普通文件、目录文件、字符设备文件、块设备文件、FIFO文件、套接字文件和符号链接文件。
1.3 open、close函数
函数原型:
SYNOPSIS
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
int creat(const char *pathname, mode_t mode);open函数成功返回文件描述符,失败返回 -1
pathname是要打开的文件名,包含路径,缺省为当前路径
flags参数可用来说明此函数的多个选项,用下列一个或多个常量进行“或”运算构成flags参数,其中以下三个参数必须包含一个:
O_RDONLY : 只读打开
O_WRONLY : 只写打开
O_RDWR : 读、写打开大多数实现将 O_RDONLY 定义为 0,O_WRONLY定义为 1,O_RDWR 定义为 2,以与早期的程序兼容。此外还有许多参数,具体的大家可以自行去man。
如果使用O_CREAT标志创建文件,则需要设定mode参数来表示文件的访问权限。
creat函数用来创建一个新文件,成功返回文件描述符,失败返回 -1
此函数等效于:
open(pathname, O_WRONLY|O_CREAT|O_TRUNC,mode);在早期的Unix版本中,open的第二个参数只能是 0、1 或 2.无法打开一个尚未存在的文件,因此需要另一个系统调用creat来创建新文件。现在open函数提供了选项O_CREAT 和 O_TRUNC,于是也就不再需要单独的creat函数了。
creat函数的另一个不足时它以只写方式打开所创建的文件。在提供open的新版本之前,如果要创建一个临时文件,并要先写该文件然后读该文件,则必须先调用creat、close,然后再调用open。
close函数原型:
SYNOPSIS
#include <unistd.h>
int close(int fd);
//成功返回 0,失败返回 -1接下来我们看一个简单的打开文件的例子:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
int fd;
fd = open("Love",O_CREAT|O_RDONLY,0666);
if(fd < 0)
{
perror("open");
exit(1);
}
printf("open %d.\n",fd);
close(fd);
return 0;
}
编译运行:
root@luxiaodai:/home/luxiaodai/lxd# gcc -o open open.c
root@luxiaodai:/home/luxiaodai/lxd# ./open
open 3.
root@luxiaodai:/home/luxiaodai/lxd# ll Love
-rw-r--r-- 1 root root 0 8月 29 10:43 Love1.4 read和write函数
read函数原型:
SYNOPSIS
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
//功能:从文件描述符fd所指定的文件读取count字节到buf缓冲区,返回值为实际读取字节数,若已到文件尾,返回 0,出错返回 -1接下来来看一个简单的例子,代码如下:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int main(void)
{
int fd;
char buf[1024];
fd = open("Love",O_CREAT|O_RDONLY,0666);
if(fd < 0)
{
perror("open");
exit(1);
}
printf("open %d.\n",fd);
memset(buf, 0, 1024);
int readnum = read(fd, buf, 1024);
if(readnum < 0)
{
perror("read");
exit(1);
}
else if(readnum > 0)
{
printf("read from %d is %s\n",fd,buf);
}
else
printf("end of file.\n");
close(fd);
return 0;
}
执行如下操作:
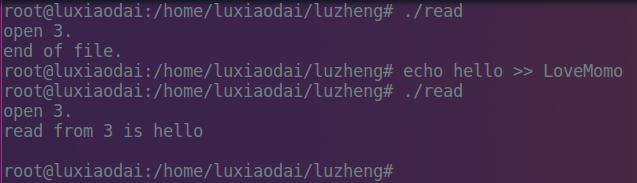
文件最初被创建时里面是空的,所以提示到文件尾了,当文件里有了内容时,read函数将其读取出来。
write函数原型:
#include <unistd.h>
ssize_t write(int fd, void *buf, size_t count);
//把count字节从buf写到fd所指定文件中,若成功返回实际写入的字节数,失败返回 -1lseek函数原型:
SYNOPSIS
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);每个打开文件都有一个与其相关联的“当前文件偏移量”。它通常是一个非负整数,用以度量从文件开始处计算的字节数。lseek将文件读写指针相对whence移动offset个字节。操作成功时,返回文件指针相对于文件头的位置。
- 若whence是SEEK_SET,则将该文件的偏移量设置为据文件开始处offset个字节
- 若whence是SEEK_CUR,则将该文件的偏移量设置为其当前值加offset,offset可为正或负
- 若whence是SEEK_END,则将该文件的偏移量设置为文件长度加offset,offset可正可负
lseek仅将当前的文件偏移量记录在内核中,它并不引起任何IO操作。
下面来看一个例子:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int main(void)
{
int fd;
char buf[1024];
fd = open("Love",O_CREAT|O_RDWR,0666); //打开一个文件
if(fd < 0) //打开失败
{
perror("open");
exit(1);
}
printf("open %d.\n",fd);
/*清空缓存,写入数据到buf*/
memset(buf, 0, 1024);
strcpy(buf, "nice weekend");
int writenum = write(fd, buf, strlen(buf)); //写入实际数据长度
if(writenum < 0) //写出错处理
{
perror("write");
exit(1);
}
memset(buf, 0, 1024);
// lseek(fd, SEEK_SET, 0);
int readnum = read(fd, buf, 1024);
if(readnum < 0) //出错
{
perror("read");
exit(1);
}
else if(readnum > 0) //正确读取
{
printf("read from %d is %s\n",fd,buf);
}
else
printf("end of file.\n"); //文件尾
close(fd);
return 0;
}
编译运行一下:
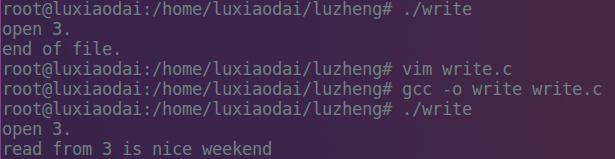
我们发现第一次执行时没有读取到文件里的数据而是读到了文件尾,这是因为写的时候指针自动移动到了文件尾,当读取时,指针并没有移动,我们加入lseek主动将指针移到文件头,即将上面注释的代码加入到程序中,我们发现这个时候再编译运行就能正确读取数据了。
1.5 文件共享
内核使用 3 种数据结构表示打开文件,它们之间的关系决定了文件共享方面一个进程对另一个进程可能产生的影响。
1 )每个进程在进程表中都有一个记录项,每个记录项中有一张打开文件描述符表,可将其视为一个矢量,每个描述符占用一项。与每个文件描述符相关联的是:
a. 文件描述符标志。
b. 指向一个文件表项的指针。
2 )内核为所有打开文件维持一张文件表。每个文件表项包含:
a. 文件状态标志(读、写、增写、同步等)。
b. 当前文件位移量。
c. 指向该文件v节点表项的指针。
3 )每个打开文件(或设备)都有一个v节点(v-node)结构。
v节点包含了文件类型和对此文件进行各种操作的函数的指针信息。对于大多数文件, v节点还包含了该文件的i节点(i-node,索引节点)。例如, i节点包含了文件的所有者、文件长度、文件所在的设备、指向文件在盘上所使用的实际数据块的指针等等
Linux没有使用 v 节点,而是使用了通用i节点结构。虽然两种实现有所不同,但在概念上,v 节点和 i 节点是一样的。两者都指向文件系统特有的 i 节点结构
下图显示了一个进程对应的三张表之间的关系,该进程有两个不同的打开文件,一个文件从标准输入打开(文件描述符0),另一个从标准输出打开(文件描述符为1):
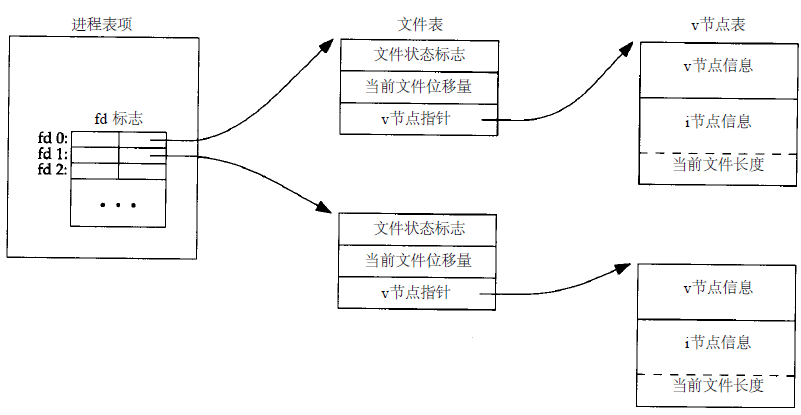
创建 v 节点结构的目的是对在一个计算机系统上的多文件系统类型提供支持。这一工作是贝尔实验室和Sun公司分别独立完成的。Sun把这种文件系统成为虚拟文件系统(virtual file system),把与文件系统无关的 i 节点部分称为 v 节点。Linux没有将相关数据结构分为 i 节点和 v 节点,而是采用了一个与文件系统相关的 i 节点和一个与文件系统无关的 i 节点。
如果两个独立进程各自打开了同一文件,则有下图的关系:
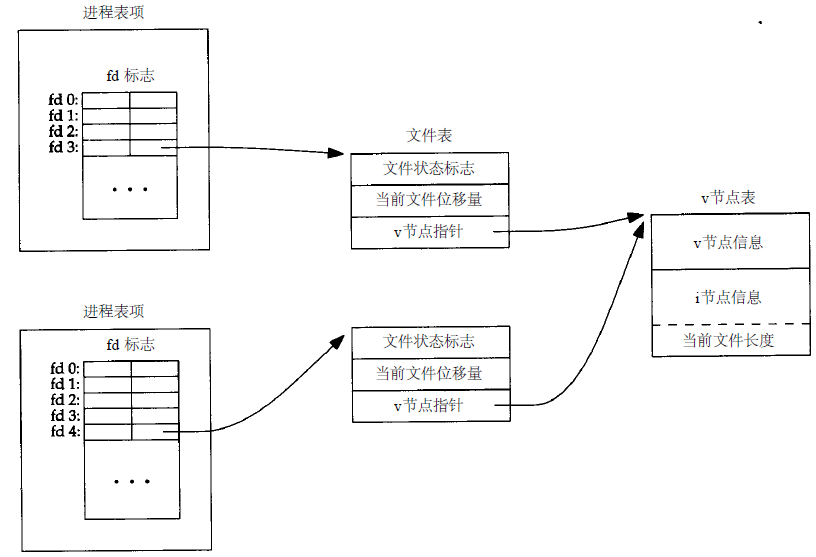
我们假定第一个进程在文件描述符 3 上打开该文件,而另一个进程在文件描述符 4 上打开该文件。打开该文件的每个进程都获得各自的一个文件表项,但对于一个给定的文件只有一个 v 节点表项。之所以每个进程都获得自己的文件表项,是因为这可以使每个进程都有它自己对该文件的当前偏移量。
当给出这些数据结构后,现在对前面所述的操作进一步说明:
-
在完成每个write后,在文件表项中的当前文件偏移量增加所写入的字节数。如果这导致当前文件偏移量超出了当前文件长度,则将 i 节点表项中的当前文件长度设置为当前偏移量
-
如果使用O_APPEND标志打开一个文件,则相应标志也被设置到文件表项的文件状态标志中。每次对这种具有追加标志的文件执行写操作时,文件表项中的当前文件偏移量首先会被设置 i 节点表项中的文件长度。这就使得每次写入的数据都追加到文件的当前尾端处。
-
若一个文件用lseek定位到文件当前的尾端,则文件表项中的当前文件偏移量被设置为 i 节点表项中的当前长度。(这与用O_APPEND标志打开文件不同,详见1.6节)
-
lseek函数只修改文件表项中的当前文件偏移量,不进行任何IO操作。
1.6 原子操作
1.6.1 追加到一个文件
考虑一个进程,它要将数据添加到一个文件尾端。早期的 UNIX版本并不支持 open的O_APPEND选择项,所以程序被编写成下列形式:
if (lseek(fd, 0L, 2) < 0) /*position to EOF*/
err_sys("lseek error");
if (write(fd, buff, 100) != 100) /*and write*/
err_sys("write error");对单个进程而言,这段程序能正常工作,但若有多个进程时,则会产生问题。 (如果此程序由多个进程同时执行,各自将消息添加到一个日记文件中,就会产生这种情况。 )
假定有两个独立的进程 A和B,都对同一文件进行添加操作。每个进程都已打开了该文件,但未使用 O_APPEND标志。此时每个进程都有它自己的文件表项,但是共享一个 v节点表项。假定进程A调用了lseek,它将对于进程A的该文件的当前位移量设置为1500字节(当前文件尾端处)。然后内核切换进程使进程 B运行。进程B执行lseek,也将其对该文件的当前位移量设置为 1500字节(当前文件尾端处)。然后B调用write,它将B的该文件的当前文件位移量增至 1600。因为该文件的长度已经增加了,所以内核对 v节点中的当前文件长度更新为 1600。然后,内核又进行进程切换使进程 A恢复运行。当A调用write时,就从其当前文件位移量(1500)处将数据写到文件中去。这样也就代换了进程 B刚写到该文件中的数据。
这里的问题出在逻辑操作“定位档到文件尾端处,然后写”使用了两个分开的函数调用。解决问题的方法是使这两个操作对于其他进程而言成为一个原子操作。任何一个要求多于 1个函数调用的操作都不能成为原子操作,因为在两个函数调用之间,内核有可能会临时挂起该进程(正如我们前面所假定的)。
UNIX提供了一种方法使这种操作成为原子操作,其方法就是在打开文件时设置O_APPEND标志。正如前一节中所述,这就使内核每次对这种文件进行写之前,都将进程的当前位移量设置到该文件的尾端处,于是在每次写之前就不再需要调用 lseek。
1.6.2 pread和pwrite
single UNIX Specification包括XSI扩展,该扩展允许原子性地定位并执行IO。pread和pwrite就是这种扩展。
函数原型:
SYNOPSIS
#include <unistd.h>
ssize_t pread(int fd, void *buf, size_t count, off_t offset);
ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);调用pread相当于调用lseek后调用read,但是pread又与这种顺序调用有以下重要区别:
- 调用pread时,无法中断其定位和读操作
- 不更新当前文件偏移量
调用pwrite相当于调用lseek后调用write,但也与它们有类似区别。
1.6.3创建一个文件
在对open函数的 O_CREAT和O_EXCL选择项进行说明时,我们已见到了另一个有关原子操作的例子。当同时指定这两个选择项,而该文件又已经存在时, open将失败。我们曾提及检查该文件是否存在以及创建该文件这两个操作是作为一个原子操作执行的。如果没有这样一个原子操作,那么可能会编写下列程序段:
if ((fd = open(pathname, O_WRONLY)) <0)
if (errno == ENOENT) {
if ((fd = creat(pathname, mode)) < 0)
err_sys("creat error");
} else
err_sys("open error");如果在打开和创建之间,另一个进程创建了该文件,那么就会发生问题。如果在这两个函数调用之间,另一个进程创建了该文件,而且又向该文件写进了一些数据,那么执行这段程序中的creat时,刚写上去的数据就会被擦去。将这两者合并在一个原子操作中,此种问题也就不会产生。
一般而言,原子操作(atomic operation)指的是由多步组成的操作。如果该操作原子地执行,则或者执行完所有步,或者一步也不执行,不可能只执行所有步的一个子集。
1.7 其他函数
1.7.1 dup函数
dup和dup2也是两个非常有用的调用,它们的作用都是用来复制一个文件的描述符。它们经常用来重定向进程的stdin、stdout和stderr。这两个函数的原型如下:
SYNOPSIS
#include <unistd.h>
int dup(int oldfd);
int dup2(int oldfd, int newfd);利用函数dup,我们可以复制一个描述符。传给该函数一个既有的描述符,它就会返回一个新的描述符,这个新的描述符是传给它的描述符的拷贝。这意味着,这两个描述符共享同一个数据结构。例如,如果我们对一个文件描述符执行lseek操作,得到的第一个文件的位置和第二个是一样的。
dup2函数跟dup函数相似,但dup2函数允许调用者规定一个有效描述符和目标描述符的id。dup2函数成功返回时,目标描述符(dup2函数的第二个参数)将变成源描述符(dup2函数的第一个参数)的复制品,换句话说,两个文件描述符现在都指向同一个文件,并且是函数第一个参数指向的文件。下面我们用一段代码加以说明:
int oldfd;
oldfd = open("app_log", (O_RDWR | O_CREATE), 0644 );
dup2( oldfd, 1 );
close( oldfd );在本例中,我们打开了一个新文件,称为“app_log”,并收到一个文件描述符,该描述符叫做fd1。我们调用dup2函数,参数为oldfd和1,这会导致用我们新打开的文件描述符替换掉由1代表的文件描述符(即stdout,因为标准输出文件的id为1)。任何写到stdout的东西,现在都将改为写入名为“app_log”的文件中。需要注意的是,dup2函数在复制了oldfd之后,会立即将其关闭,但不会关掉新近打开的文件描述符,因为文件描述符1现在也指向它。
1.7.2 sync、fsync、fdatasync
传统的Unix系统实现在内核中设有缓冲区高速缓存或页高速缓存,大多数磁盘IO都通过缓冲区进行。当我们向文件写入数据时,内核通常现将数据复制到缓冲区,然后排入队列,晚些时候再写入磁盘。这种方式被称为写延迟(delayed write)。
通常,当内核需要重用缓冲区来存放其他磁盘块数据时,它会把所有延迟写数据块写入磁盘。为了保证磁盘上实际文件系统与缓冲区中内容的一致性,Unix提供sync、fsync和fdatasync三个函数。
函数原型:
SYNOPSIS
#include <unistd.h>
int fsync(int fd);
int fdatasync(int fd);
void sync(void);sync只是将所有修改过的块缓冲区排入写队列,然后就返回,它并不等待实际写磁盘操作结束。
通常,成为update的系统守护进程周期性地调用(一般每隔30秒)sync函数。这就保证了定期冲洗(flush)内核的块缓冲区。
fsync函数只对由文件描述符fd指定的一个文件起作用,并且等待写磁盘操作结束才返回。fsync可用于数据库这样的应用程序,这种应用程序需要确保修改过的块立即写到磁盘上。
fdatasync函数类似于fsync,但它只影响文件的数据部分。而除数据外,fsync还会同步更新文件的属性。
1.7.3 fcntl函数
fcntl函数可以改变已经打开文件的性质。
函数原型如下:
SYNOPSIS
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* arg */ );在本节的各实例中,第三个参数总是一个整数,与上面所示函数原型中的注释部分相对应。但是说明记录锁时,第三个参数则是指向一个结构的指针。
fcntl函数有五种功能:
• 复制一个现存的描述符(cmd=F_DUPFD或F_DUPFD_CLOEXEC)。
• 获得/设置文件描述符标记(cmd = F_GETFD或F_SETFD)。
• 获得/设置文件状态标志(cmd = F_GETFL或F_SETFL)。
• 获得/设置异步I / O有权(cmd = F_GETOWN或F_SETOWN)。
• 获得/设置记录锁(cmd = F_GETLK , F_SETLK或F_SETLKW)。
2. 标准IO库
2.1 流
上面所讲述的文件IO都是针对文件描述符的。当打开一个文件时,即返回一个文件描述符,然后该文件描述符就用于后读的 IO操作。而对于标准 IO库,它们的操作则是围绕流(stream)进行的。
当用标准IO库打开或创建一个文件时,我们已使一个流与一个文件相结合。当打开一个流时,标准IO函数fopen返回一个指向FILE对象的指针。该对象通常是一个结
构,它包含了IO库为管理该流所需要的所有信息:用于实际 IO的文件描述符,指向流缓存的指针,缓存的长度,当前在缓存中的字符数,出错标志等等。
应用程序没有必要检验 FILE对象。为了引用一个流,需将 FILE指针作为参数传递给每个标准IO函数。在本书中,我们称指向FILE对象的指针(类型为FILE*)为文件指针。
对一个进程预定义了三个流,它们自动地可为进程使用:标准输入、标准输出和标准出错。这三个标准I / O流通过预定义文件指针stdin,stdout和stderr加以引用。这三个文件指针同样定义在头文件
2.2 缓冲
一、什么是缓存I/O(Buffered I/O)
1.缓存I/O有以下优点:
A.缓存I/O使用了操作系统内核缓冲区,在一定程度上分离了应用程序空间和实际的物理设备。
B.缓存I/O可以减少读盘的次数,从而提高性能当应用程序尝试读取某块数据的时候,如果这块数据已经存放在页缓存中,那么这块数据就可以立即返回给应用程序,而不需要经过实际的物理读盘操作。当然,如果数据在应用程序读取之前并未被存放在页缓存中,那么就需要先将数据从磁盘读到页缓存中去。对于写操作来说,应用程序也会将数据先写到页缓存中去,数据是否被立即写到磁盘上去取决于应用程序所采用的写操作机制:如果用户采用的是同步写机制,那么数据会立即被写回到磁盘上,应用程序会一直等到数据被写完为止;如果用户采用的是延迟写机制,那么应用程序就完全不需要等到数据全部被 写回到磁盘,数据只要被写到页缓存中去就可以了。在延迟写机制的情况下,操作系统会定期地将放在页缓存中的数据刷到磁盘上。与异步写机制不同的是,延迟写机制在数据完全写到磁盘上得时候不会通知应用程序,而异步写机制在数据完全写到磁盘上得时候是会返回给应用程序的。所以延迟写机制本省是存在数据丢失的风险的,而异步写机制则不会有这方面的担心。
2.缓存I/O的缺点
在缓存I/O机制中,DMA方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存直接写回到磁盘上,而不能直接在应用程序地址空间和磁盘之间进行数据传输,这样的话,数据在传输过程中需要在应用程序地址空间和页缓存之间进行多次数据拷贝操作,这些数据拷贝操作说带来的cpu以及内存开销是非常大的。
标准IO提供缓存的目的是尽可能减少使用 read和write调用的数量,标准IO提供了三种类型的缓存:
(1) 全缓存。在这种情况下,当填满标准IO缓存后才进行实际IO操作。对于驻在磁盘上的文件通常是由标准IO库实施全缓存的。在一个流上执行第一次 IO操作时,相关标准IO函数通常调用malloc获得需使用的缓存。
术语刷新(flush)说明标准IO缓存的写操作。缓存可由标准 IO例程自动地刷新(例如当填满一个缓存时),或者可以调用函数 fflush刷新一个流。值得引起注意的是在 UNIX环境中,刷新有两种意思。在标准 IO库方面,刷新意味着将缓存中的内容写到磁盘上(该缓存可以只是局部填写的)。在终端驱动程序方面(例如tcflush函数),刷新表示丢弃已存在缓存中的数据。
(2) 行缓存。在这种情况下,当在输入和输出中遇到新行符时,标准 IO库执行IO操作。这允许我们一次输出一个字符(用标准 IO fputc函数),但只有在写了一行之后才进行实际 IO操作。当流涉及一个终端时(例如标准输入和标准输出),典型地使用行缓存。对于行缓存有两个限制。第一个是:因为标准 IO库用来收集每一行的缓存的长度是固定的,所以只要填满了缓存,那么即使还没有写一个新行符,也进行 IO操作。第二个是:任何时候只要通过标准输入输出库要求从 (a)一个不带缓存的流,或者 (b)一个行缓存的流(它预先要求从内核得到数据)得到输入数据,那么就会造成刷新所有行缓存输出流。在 (b)中带了一个在括号中的说明的理由是,所需的数据可能已在该缓存中,它并不要求内核在需要该数据时才进行该操作。很明显,从不带缓存的一个流中进行输入((a)项)要求当时从内核得到数据。
(3) 不带缓存。标准 IO库不对字符进行缓存。如果用标准 IO函数写若干字符到不带缓存的流中,则相当于用 write系统调用函数将这些字符写至相关联的打开文件上。
标准出错流stderr通常是不带缓存的,这就使得出错信息可以尽快显示出来,而不管它们是否含有一个新行字符。
ISO C要求下列缓存特征:
(1) 当且仅当标准输入和标准输出并不涉及交互作用设备时,它们才是全缓存的。
(2) 标准出错决不会是全缓存的。
但是,这并没有告诉我们如果标准输入和输出涉及交互作用设备时,它们是不带缓存的还是行缓存的,以及标准输出是不带缓存的,还是行缓存的。 很多系统默认使用下列类型的缓存:
• 标准出错是不带缓存的。
• 若是指向终端设备的流,则它们是行缓存的;否则是全缓存的。
对任何一个给定的流,如果我们并不喜欢这些系统默认,可用 setbuf 和 setvbuf 函数设置缓冲类型已经缓冲区大小,使用fflush函数冲洗缓冲区。
2.3 打开和关闭流
打开函数原型:
SYNOPSIS
#include <stdio.h>
FILE *fopen(const char *path, const char *mode);
FILE *fdopen(int fd, const char *mode);
FILE *freopen(const char *path, const char *mode, FILE *stream);
/* 成功返回FILE类型指针,出错返回NULL */这三个函数的区别是:
(1)fopen打开路径名由pathname指示的一个文件
(2)freopen常用于一个打开的流重新定向。比如stdout是标准输出,我们可以把它重定向到由path指定的一个文件。
(3)fdopen取一个现存的文件描述符,并使一个标准的I/O流与该描述符相结合。
fopen的参数mode与open的参数 flags之间的等价关系:
r ——–>O_RDONLY
r+——->O_RDWR
w——–>O_WRONLY | O_CREAT | O_TRUNC,0666
w+——>O_RDWR | O_CREAT | O_TRUNC,0666
a———>O_WRONLY | O_CREAT | O_APPEND,0666
a+——–>O_RDWR | O_CREAT | O_APPEND,0666
关闭函数原型:
SYNOPSIS
#include <stdio.h>
int fclose(FILE *stream);
/* 成功返回0,出错返回EOF */下面是一个简单的打开文件的例子:
#include <stdio.h>
#include <errno.h>
#include <stdlib.h>
int main(void)
{
FILE *fp;
fp = fopen("Love","w+");
if(fp == NULL)
{
perror("fopen");
exit(1);
}
printf("success open the file.\n");
if(fclose(fp) == EOF)
{
perror("fclose");
exit(1);
}
return 0;
}
2.4 读写流
一旦打开了流,则可在三种不同类型的非格式化 IO中进行选择,对其进行读、写操作。
(1) 每次一个字符的IO。一次读或写一个字符,如果流是带缓存的,则标准 IO函数处理所有缓存。
(2) 每次一行的IO。使用fgets和fputs一次读或写一行。每行都以一个新行符终止。当调用fgets时,应说明能处理的最大行长。
(3) 直接I / O。 fread和fwrite函数支持这种类型的 IO。每次IO操作读或写某种数量的对象,而每个对象具有指定的长度。这两个函数常用于从二进制文件中读或写一个结构。
直接IO这个术语来自ISO C标准,有时也被称为:二进制IO、一次一个对象IO、面向记录的IO或面向结构的IO。不要把这个特性和Linux支持的open函数的O_DIRECT标志混淆,它们之间是没有关系的。
2.4.1 每次一个字符的IO
函数原型:
SYNOPSIS
#include <stdio.h>
int fgetc(FILE *stream);
int getc(FILE *stream);
int getchar(void);函数getchar等同于getc(stdin)。 前两个函数的区别是getc可被实现为宏,而fgetc则不能实现为宏。这意味着:
(1) getc的参数不应当是具有副作用的表达式。
(2) 因为fgetc一定是个函数,所以可以得到其地址。这就允许将fgetc的地址作为一个参数传送给另一个函数。
(3) 调用fgetc所需时间很可能长于调用getc ,因为调用函数通常所需的时间长于调用宏。
从上面观察我们发现,这几个函数都是用来读取一个字符的,但是返回值都是int,为什么要这样做呢?我们看下面的探究:
<1>字节的读取
在正常情况下,fgetc或getc以unsigned char的方式读取文件流,扩张为一个整数,并返回。也就是说,fgetc或getc从文件流中取一个字节,并加上24个0,称为一个小于256的整数,然后返回。
int c;
while((c = fgetc(rfp)) != -1)//-1就是EOF
fputc(c,wfp);上面fputc中的c虽然是整数,但在fputc将其写入文件流之前,又把整数的高24位去掉了,因此fgetc,fputc配合能够实现文件复制。
<2>判断文件结束
多数人认为文件中有一个EOF,用于表示文件的结尾。但这个观点实际上是错误的,在文件所包含的数据中,并没有什么文件结束符。对fgetc或getc而言,如果不能从文件中读取,则返回一个整数-1,这就是所谓的EOF,返回 EOF无非是出现了两种情况,一是文件已经读完;二是文件读取出错,反正是读不下去了。
注意:在正常读取的情况下,返回的整数均小于256,,即0x00-0xff,而读不出返回的是0xffffffff,但,假如你用fputc把0xffffffff向文件里头写,高24位被屏蔽,写入的将是0xff
<3>0xff会使我们混淆吗?
不会,前提是,接收返回值的c要按原型定义为int。如果下一个读取的字符将为oxff,则
int c;
c = fgetc(rfp);//c = 0x000000ff
if(c != -1)//当然不等,-1是0xffffffff
fputc(c,wfp);//oxff写入成功注意:字符0xff,其本身并不是EOF
<4>将c定义为char
假定下一个读取的字符为0xff,则
char c;
c = fgetc(rfp);//fgetc(rfp)的值为0x000000ff,暗中降为字节,c =0xff
if(c != -1)//字符与整数比较?c被带符号(signed)扩展为0xffffffff,条件成立,文件复制提前结束
fputc(c,wfp);<5>将c定义为unsigned char
unsigned char c;
c =fgetc(rfp);
if(c != -1)//此时条件将恒成立,因为c是一个无符号数,不可能是-1的。
fputc(c,wfp);<6>为何需要feof?
fgetc返回-1时,我们任然无法确信文件已经结束,因为可能是读取错误!这时我们需要feof和ferror。不管是出错还是到达文件尾端,这三个函数都返回同样的值。为了区分这两种不同的情况,必须调用ferror()或feof()。
SYNOPSIS
#include <stdio.h>
void clearerr(FILE *stream);
int feof(FILE *stream);
int ferror(FILE *stream);在大多数实现的FILE对象中,为每个流保持了两个标志:
• 出错标志。
• 文件结束标志。
调用clearerr可以清除这两个标志。
对应于上面所述的每个输入函数都有一个输出函数:
SYNOPSIS
#include <stdio.h>
int fputc(int c, FILE *stream);
int putc(int c, FILE *stream);
int putchar(int c);与输入函数一样, putchar(c) 等同于putc (c, stdout), putc 可被实现为宏,而fputc 则不能实现为宏。
下面看一个例子:
#include <stdio.h>
FILE *open_file(const char *name,const char *mode)
{
FILE *fp;
if((fp = fopen(name,mode)) == NULL)
{
perror("Fail to fopen");
return NULL;
}
return fp;
}
int do_copy(FILE *src_fp,FILE *dest_fp)
{
int ch;
while((ch = fgetc(src_fp)) != EOF)
fputc(ch,dest_fp);
if(feof(src_fp))
{
printf("we have read end of file.\n");
return 0;
}
else
{
printf("read file error.\n");
return -1;
}
}
int main(int argc, char *argv[])
{
FILE *rfp,*wfp;
if(argc < 2)
{
fprintf(stderr,"usage : %s src_file dest_file",argv[0]);
return -1;
}
if((rfp = open_file(argv[1],"r")) == NULL)
return -1;
if((wfp = open_file(argv[2],"w")) == NULL)
return -1;
if(do_copy(rfp,wfp) < 0)
return -1;
return 0;
}
运行结果:
root@luxiaodai:/home/luxiaodai/lxd# ./singlechar rfp_file wfp_file
we have read end of file.
root@luxiaodai:/home/luxiaodai/lxd# cat wfp_file
im here,just feel it
root@luxiaodai:/home/luxiaodai/lxd# cat rfp_file
im here,just feel it
2.4.2 每次一行的IO
fgets和fputs函数原型:
SYNOPSIS
#include <stdio.h>
char *fgets(char *s, int size, FILE *stream);
/*成功返回buf,若已到达文件尾端或出错,返回NULL*/
int fputs(const char *s, FILE *stream);
/*成功返回非负值,出错返回EOF*/ fgets在三种情况下,会结束读取
<1>成功读取了size-1个字符
<2>读取的时候遇到’\n’
<3>读到文件尾
这三种情况下,fgets都必做一件事情,就是在结束的时候,都会加上’\0’
fgets()返回值为NULL时,可能流中没有字符可读了,可能读取出错
fputs函数是将一个字符串写入流,但是不会将’\0’进行写入
下面看一个例子:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main(void)
{
char buf[15] = "aaa\0bbb\ncccccc";
FILE *fp;
int i = 0;
char testbuf[20];
if((fp = fopen("test.txt","w+")) == NULL)
{
perror("fopen");
return -1;
}
for(i=0 ; i<sizeof(buf) ; i++)
fputc(buf[i],fp);
memset(testbuf , 'b' , sizeof(testbuf));
fseek(fp , 0 , SEEK_SET);
system("od -c test.txt");
if(fgets(testbuf , sizeof(testbuf) , fp) == NULL)
perror("fail to testbuf");
putchar('\n');
for(i=0 ; i<sizeof(testbuf) ; i++)
printf("%3d",testbuf[i]);
printf("\n\n");
fputs(testbuf , fp);
fflush(fp);
system("od -c test.txt");
return 0;
}
运行结果如下:
root@luxiaodai:/home/luxiaodai/lxd# ./fgets_fputs
0000000 a a a \0 b b b \n c c c c c c \0
0000017
97 97 97 0 98 98 98 10 0 98 98 98 98 98 98 98 98 98 98 98
0000000 a a a \0 b b b \n a a a c c c \0
0000017
从上面我们可以看到,fgets函数在读取文件的时候,遇到’\n’结束,并在最后面加上了’\0’;
fputs函数对testbuf数组中内容进行输入时,只输入了’\0’之前的字符
SYNOPSIS
#include <stdio.h>
char *gets(char *s);gets是一个不推荐使用的函数。问题是调用者在使用gets时不能指定缓存的长度。这样就可能造成缓存越界(如若该行长于缓存长度),写到缓存之后的存储空间中,从而产生不可预料的后果。这种缺陷曾被利用,造成 1988年的因特网蠕虫事件。
注意:
<1>本函数可以无限读取。不会判断上限,所以程序员应该确保buffer的空间足够大,以便在执行读操作时不发生溢出。
<2>gets(s)与scanf(“%s”,s)相似,但完全不同,使用scanf(“%s”,s)函数输入字符串时存在一个问题,就是如果输入了空格会认为字符串结束,空格后的字符将作为下一个输入项处理,但gets()函数将接收输入的整个字符串直到遇到换行符为止。
2.4.3 二进制IO
2.4.1节中的函数以一次一个字符或一次一行的方式进行操作。如果为二进制 IO,那么我们更愿意一次读或写整个结构。为了使用getc或putc做到这一点,必须循环通过整个结构,一次读或写一个字节。因为 fputs在遇到null字节时就停止,而在结构中可能含有null字节,所以不能使用每次一行函数实现这种要求。相类似,如果输入数据中包含有null字节或新行符,则fgets也不能正确工作。因此,提供了下列两个函数以执行二进制 IO操作。
SYNOPSIS
#include <stdio.h>
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
size_t fwrite(const void *ptr, size_t size, size_t nmemb,
FILE *stream);这些函数有两个常见的用法:
(1) 读或写一个二进制数组。例如,将一个浮点数组的第 2至第5个元素写至一个文件上,
可以写作:
float data 〔 1 0〕 ;
if (fwrite(&data〔 2〕 , sizeof(float), 4, fp) != 4)
err_sys("fwrite error");其中,指定size为每个数组元素的长度,nobj为欲写的元素数。
(2) 读或写一个结构。例如,可以写作:
struct {
short count;
long total;
char name [ N A M E S I Z E];
} item;
if (fwrite(&item, sizeof(item), 1, fp) != 1)
err_sys("fwrite error");其中,指定size为结构的长度,nobj为1(要写的对象数)。
将这两个例子结合起来就可读或写一个结构数组。为了做到这一点, size应当是该结构的sizeof ,nobj应是该数组中的元素数。
fread和f write返回读或写的对象数。对于读,如果出错或到达文件尾端,则此数字可以少于nobj。在这种情况,应调用 ferror或feof以判断究竟是那一种情况。对于写,如果返回值少于所要求的nobj,则出错。
使用二进制IO的基本问题是,它只能用于读已写在同一系统上的数据。多年之前,这并无问题(那时,所有UNIX系统都运行于PDP-11上),而现在,很多异构系统通过网络相互连接起来,而且,这种情况已经非常普遍。常常有这种情形,在一个系统上写的数据,在另一个系统上处理。在这种环境下,这两个函数可能就不能正常工作,其原因是:
(1) 在一个结构中,同一成员的位移量可能随编译程序和系统的不同而异(由于不同的对准要求)。确实,某些编译程序有一选择项,它允许紧密包装结构(节省存储空间,而运行性能则可能有所下降)或准确对齐,以便在运行时易于存取结构中的各成员。这意味着即使在单一系统上,一个结构的二进制存放方式也可能因编译程序的选择项而不同。
(2) 用来存储多字节整数和浮点值的二进制格式在不同的系统结构间也可能不同。
在不同系统之间交换二进制数据的实际解决方法是使用较高层次的协议。
例子:
#include <stdio.h>
#define MAX 50
FILE *open_file(const char *name, const char *mode)
{
FILE *fp;
if((fp = fopen(name,mode)) == NULL)
{
perror("fopen");
return NULL;
}
return fp;
}
int do_copy(FILE *src_fp, FILE *dest_fp)
{
char buf[MAX];
int n;
while((n = fread(buf , sizeof(char) , sizeof(buf), src_fp)) == sizeof(buf))
fwrite(buf , sizeof(char) , n , dest_fp);
//对于读,出错或到文件尾返回值都可以小于nobj,此时要调用ferror或feof来判断
if(feof(src_fp))
{
fwrite(buf , sizeof(char) , n , dest_fp);
printf("read end of file.\n");
}
else
{
printf("read error.\n");
return -1;
}
return 0;
}
int main(int argc , char * argv[])
{
FILE *rfp,*wfp;
if(argc < 2)
{
fprintf(stderr,"usage : %s src_file dest_file\n",argv[0]);
return -1;
}
if((rfp = open_file(argv[1] , "r")) == NULL)
return -1;
if((wfp = open_file(argv[2] , "w")) == NULL)
return -1;
if(do_copy(rfp,wfp) < 0)
return -1;
return 0;
}
运行结果
root@luxiaodai:/home/luxiaodai/lxd# cat r_file
hello,im lu xiao dai
root@luxiaodai:/home/luxiaodai/lxd# cat w_file
root@luxiaodai:/home/luxiaodai/lxd# ./fread_write r_file w_file
read end of file.
root@luxiaodai:/home/luxiaodai/lxd# cat w_file
hello,im lu xiao dai
2.4.4 定位流
函数原型:
SYNOPSIS
#include <stdio.h>
int fseek(FILE *stream, long offset, int whence);
long ftell(FILE *stream);
void rewind(FILE *stream);
int fgetpos(FILE *stream, fpos_t *pos);
int fsetpos(FILE *stream, const fpos_t *pos);
fseek函数是用来定位流的文件指示器的位置的,其中whence有三个参数
SEEK_SET从文件头开始
SEEK_CUR从文件指示器当前位置开始
SEEK_END从文件尾开始
如:
fseek(fp,0,SEEK_SET);将文件指示器定位到文件头
fseek(fp,35,SEEK_CUR);将文件指示器从当前位置向后移动35byte;
fseek(fp,0,SEEK_END);将文件指示器定位到文件尾部
ftell函数用来获得文件指示器当前位置
rewind函数用来将文件指示器重新定位到文件头
fgetpos和fsetpos函数相当于ftell和fseek(whence设置为SEEK_SET)的另一种写法,读取文件当前位置并保存在pos中,或用pos指向的值设置当前文件位置。
2.4.5 格式化IO
输出函数原型:
SYNOPSIS
#include <stdio.h>
int printf(const char *format, ...);
int fprintf(FILE *stream, const char *format, ...);
int sprintf(char *str, const char *format, ...);
printf函数将格式化数据写到标准输出,fprintf写至指定的流,sprintf将格式化的字符输入数组buf中 。fprintf在该数组的尾端自动加一个NULL字节,但该字节不包括在返回值中。
例子:
#include <stdio.h>
int main(void)
{
char buf[50];
printf("hello world.\n");
fprintf(stdout,"im here\n");
sprintf(buf,"%d",520);
puts(buf);
return 0;
}运行结果:
root@luxiaodai:/home/luxiaodai/lxd# ./test
hello world.
im here
520
3. 系统调用和库函数的区别
Linux下对文件操作有两种方式:系统调用(system call)和库函数调用(Library functions)。系统调用实际上就是指最底层的一个调用,在linux程序设计里面就是底层调用的意思,面向的是硬件。而库函数调用则面向的是应用开发的,相当于应用程序的api,采用这样的方式有很多种原因:
第一,双缓冲技术的实现;
第二,可移植性;
第三,底层调用本身的一些性能方面的缺陷;
第四:让api也可以有了级别和专门的工作面向。
3.1 系统调用
系统调用提供的函数如open, close, read, write, ioctl等,需包含头文件unistd.h。
以write为例:其函数原型为 size_t write(int fd, const void *buf, size_t nbytes),其操作对象为文件描述符或文件句柄fd(file descriptor),要想写一个文件,必须先以可写权限用open系统调用打开一个文件,获得所打开文件的fd,例如 fd=open(\”/dev/video\”, O_RDWR)。fd是一个整型值,每新打开一个文件,所获得的fd为当前最大fd加1。Linux系统默认分配了3个文件描述符值:0-standard input,1-standard output,2-standard error。
系统调用通常用于底层文件访问(low-level file access),例如在驱动程序中对设备文件的直接访问。
系统调用是操作系统相关的,因此一般没有跨操作系统的可移植性。
系统调用发生在内核空间,因此如果在用户空间的一般应用程序中使用系统调用来进行文件操作,会有用户空间到内核空间切换的开销。事实上,即使在用户空间使用库函数来对文件进行操作,因为文件总是存在于存储介质上,因此不管是读写操作,都是对硬件(存储器)的操作,都必然会引起系统调用。也就是说,库函数对文件的操作实际上是通过系统调用来实现的。例如C库函数fwrite()就是通过write()系统调用来实现的。
这样的话,使用库函数也有系统调用的开销,为什么不直接使用系统调用呢?这是因为,读写文件通常是大量的数据(这种大量是相对于底层驱动的系统调用所实现的数据操作单位而言),这时,使用库函数就可以大大减少系统调用的次数。这一结果又缘于缓冲区技术。在用户空间和内核空间,对文件操作都使用了缓冲区,例如用fwrite写文件,都是先将内容写到用户空间缓冲区,当用户空间缓冲区满或者写操作结束时,才将用户缓冲区的内容写到内核缓冲区,同样的道理,当内核缓冲区满或写结束时才将内核缓冲区内容写到文件对应的硬件媒介。
3.2 库函数调用
标准C库函数提供的文件操作函数如fopen, fread, fwrite, fclose, fflush, fseek等,需包含头文件stdio.h。
以fwrite为例,其函数原型为size_t fwrite(const void *buffer, size_t size, size_t item_num, FILE *pf),其操作对象为文件指针FILE *pf,要想写一个文件,必须先以可写权限用fopen函数打开一个文件,获得所打开文件的FILE结构指针pf,例如pf=fopen(\”~/proj/filename\”, \”w\”)。实际上,由于库函数对文件的操作最终是通过系统调用实现的,因此,每打开一个文件所获得的FILE结构指针都有一个内核空间的文件描述符fd与之对应。同样有相应的预定义的FILE指针:stdin-standard input,stdout-standard output,stderr-standard error。
库函数调用通常用于应用程序中对一般文件的访问。
库函数调用是系统无关的,因此可移植性好。
由于库函数调用是基于C库的,因此也就不可能用于内核空间的驱动程序中对设备的操作。
3.3 函数库调用 VS 系统调用
| 函数库调用 | 系统调用 |
|---|---|
| 在所有的ANSI C编译器版本中,C库函数是相同的 | 各个操作系统的系统调用是不同的 |
| 它调用函数库中的一段程序(或函数) | 它调用系统内核的服务 |
| 与用户程序相联系 | 是操作系统的一个入口点 |
| 在用户地址空间执行 | 在内核地址空间执行 |
| 它的运行时间属于“用户时间” | 它的运行时间属于“系统”时间 |
| 属于过程调用,调用开销较小 | 需要在用户空间和内核上下文环境间切换,开销较大 |
| 在C函数库libc中有大约300个函数 | 在UNIX中大约有90个系统调用 |
4. Linux出错处理
当UNIX函数出错时,往常返回一个负值,而且整型变量errno通常设置为具有特定信息的一个值。例如,open函数如成功执行则返回一个非负文件描述符,如出错则返回-1。在open出错时,有大约1 5种不同的errno值(文件不存在,许可权问题等 )。某些函数并不返回负值而是使用另一种约定。例如,返回一个指向对象的指针的大多数函数,在出错时,将返回一个null指针。文件< errno.h>中定义了变量errno以及可以赋与它的各种常数。这些常数都以E开头。
C标准定义了两个函数,它们帮助打印出错信息。
SYNOPSIS
#include <string.h>
char *strerror(int errnum);此函数将errnum(它通常就是 errno值) 映射为一个出错信息字符串,并且返回此字符串的指针。
perror函数在标准出错上产生一条出错消息 (基于errno的当前值),然后返回。
SYNOPSIS
#include <stdio.h>
void perror(const char *s);它首先输出由s指向的字符串,然后是一个冒号,一个空格,然后是对应于 errno值的出错信息,然后是一个新行符。
下面例子展示两个函数的使用方法:
#include <stdio.h>
#include <string.h>
#include <errno.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
fprintf(stderr,"EACCES:%s\n",strerror(EACCES));
errno = ENOENT;
perror(argv[0]);
exit(0);
}执行结果:
root@luxiaodai:/home/luxiaodai/lxd# ./error
EACCES:Permission denied
./error: No such file or directory
但我们经常不直接调用strerror或perror,而是使用出错函数使我们可以只用一条C语句就可以利用IOS C的可变参数表功能处理出错情况。
参考文献:
1.Linux系统调用和库函数调用的区别
2.Unix环境高级编程 第三版 W.Richard Stevens、Stephen A.Rago著
3.Linux内核设计与实现 第三版 Robert Love著
4.标准IO相关函数
5.linux 标准IO缓冲机制探究
6.一步步理解LinuxIO(1)

