【ceph相关】bucket动态分片
1、背景说明
参考说明:
https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/2/html/object_gateway_guide_for_ubuntu/administration_cli#configuring-bucket-index-sharding
https://ceph.com/community/new-luminous-rgw-dynamic-bucket-sharding/
1.1、问题描述
性能测试中出现性能暴跌(间歇性性能波动),出现一段时间无法写入情况(时延一百多秒)
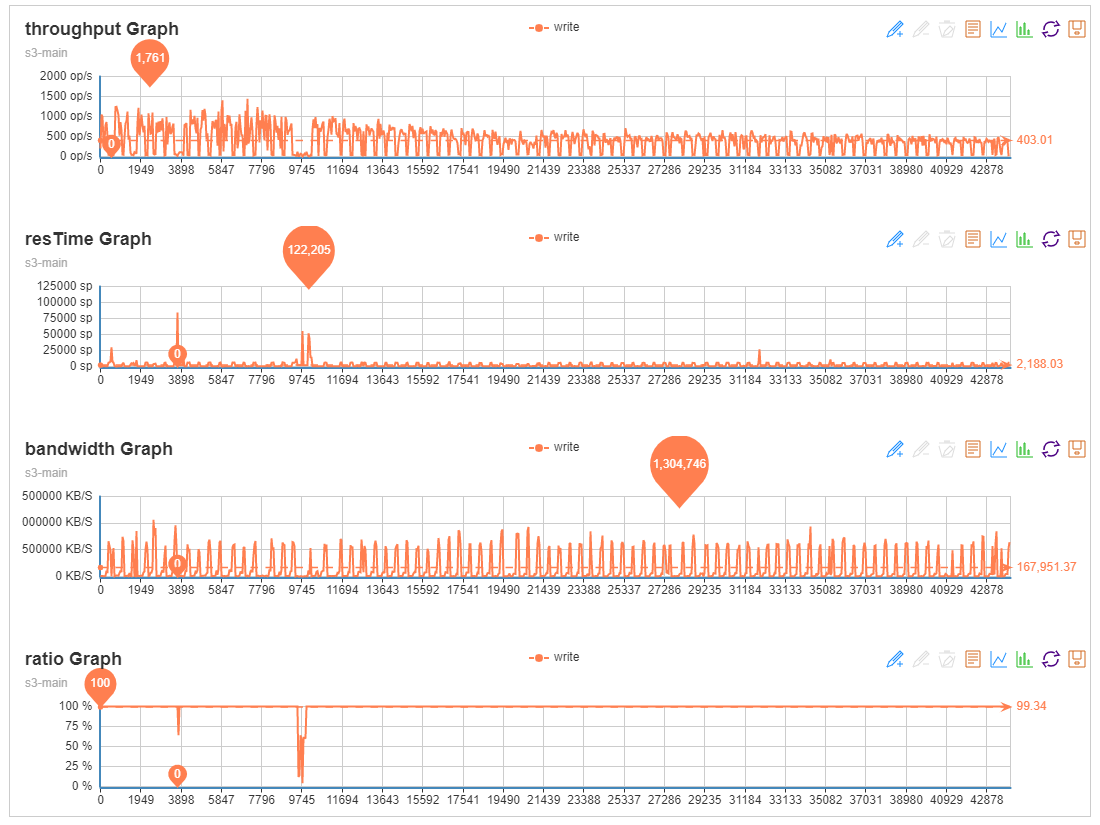
1.2、问题排查
查看rgw日志,发现单桶对象数写入太多,触发自动分片resharding操作
[root@node113 ~]# cat /var/log/ceph/ceph-client.rgw.node113.7480.log | grep reshard
2020-09-16 04:51:50.239505 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000009 ret=-16
2020-09-16 06:11:56.304955 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000013 ret=-16
2020-09-16 06:41:58.919390 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000004 ret=-16
2020-09-16 08:02:00.619906 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000002 ret=-16
2020-09-16 08:22:01.038502 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000012 ret=-16
2020-09-16 08:31:58.229956 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000000 ret=-16
2020-09-16 08:52:06.020018 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000006 ret=-16
2020-09-16 09:22:12.882771 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000000 ret=-16查看rgw相关配置,集群每个分片最大存放10w个对象,当前设置每个桶分片数为8,当写入对象数超过80w时,则会触发自动分片操作reshard
[root@node111 ~]# ceph --show-config | grep rgw_dynamic_resharding
rgw_dynamic_resharding = true
[root@node111 ~]# ceph --show-config | grep rgw_max_objs_per_shard
rgw_max_objs_per_shard = 100000
[root@node111 ~]# ceph --show-config | grep rgw_override_bucket_index_max_shards
rgw_override_bucket_index_max_shards = 8
[root@node111 ~]# radosgw-admin bucket limit check
"user_id": "lifecycle01",
"buckets": [
{
"bucket": "cosbench-test-pool11",
"tenant": "",
"num_objects": 31389791,
"num_shards": 370,
"objects_per_shard": 84837,
"fill_status": "OK"
},
{
"bucket": "cycle-1",
"tenant": "",
"num_objects": 999,
"num_shards": 8,
"objects_per_shard": 124,
"fill_status": "OK"
},参数说明
- rgw_dynamic_resharding
[L版官方引入新的参数](https://ceph.com/community/new-luminous-rgw-dynamic-bucket-sharding/,该参数默认开启,当单个bucketfill_status达到OVER 100.000000%时(objects_per_shard > rgw_max_objs_per_shard),动态进行resharding(裂变新的分片,重新均衡数据)
这个参数有个致命的缺陷,resharding过程中bucket无法进行读写,因为元数据对象正在重新分散索引,需要保证一致性,同时,数据量越大时间会越来越长
- rgw_override_bucket_index_max_shards
单个bucket创建分片数,默认参数值为0,最大参数值为7877(即单bucket最大写入对象数为7877x100000)
分片数参数计算方式为number of objects expected in a bucket / 100,000,若预估单桶对象数为300w,则分片数设置为30(300w/10w)
示例集群分片数为8,即创建bucket时默认创建8个分片,当每个分片对象数超过10w时,继续resharding创建新的分片,同时重新均衡索引到所有的分片内 - rgw_max_objs_per_shard
单个分片最大存放对象数,默认参数值为10w - rgw_reshard_thread_interval
自动分片线程扫描的间隔,默认为十分钟
1.3、分片说明
- 索引对象
RGW为每个bucket维护一份索引,里边存放了bucket中全部对象的元数据。RGW本身没有足够有效遍历对象的能力,bucket索引影响到对象写入、修改、遍历功能(不影响读)。
bucket索引还有其他用处,比如为版本控制的对象维护日志、bucket配额元数据和跨区同步的日志。
默认情况下,每个bucket只有一个索引对象,索引对象过大会导致以下问题,所以每个bucket所能存储的对象数量有限
--会造成可靠性问题,极端情况下,可能会因为缓慢的数据恢复,导致osd进程挂掉
--会造成性能问题,所有对同一bucket的写操作,都会对一个索引对象进行修改和序列化操作
- bucket分片
Hammer版本以后,新增bucket分片功能用以解决单桶存储大量数据的问题,bucket的索引数据可以分布到多个RADOS对象上,bucket存储对象数量随着索引数据的分片数量增加而增加。
但这只对新增的bucket有效,需要提前根据bucket最终存放数据量规划分片数。当存储桶写入对象超过分片所能承载的最大数时,写入性能暴跌,此时需要手动修改分片数量,以此去承载更多的对象写入。
- 动态bucket分片
Luminous版本以后,新增动态 bucket分片功能,随着存储对象的增加,RADOSGW 进程会自动发现需要进行分片的 bucket,并安排进行自动分片。
2、解决措施
主要分为以下两种情况
2.1、确定单bucket最终写入对象数
关闭动态分片功能(避免调整过程中出现性能暴跌问题),根据最终单bucket写入对象数设置分片数
示例最终单bucket写入对象数为300w,设置分片数为30
追加参数配置在/etc/ceph/ceph.conf配置文件[global]字段内
[root@node45 ~]# cat /etc/ceph/ceph.conf
[global]
rgw_dynamic_resharding = false
rgw_max_objs_per_shard = 30
重启RGW服务进程
[root@node45 ~]# systemctl restart ceph-radosgw.target2.2、不确定单bucket最终写入对象数
不关闭动态分片功能,大概设置一个分片数
追加参数配置在/etc/ceph/ceph.conf配置文件[global]字段内
[root@node45 ~]# cat /etc/ceph/ceph.conf
[global]
rgw_max_objs_per_shard = 8
重启RGW服务进程
[root@node45 ~]# systemctl restart ceph-radosgw.target

 浙公网安备 33010602011771号
浙公网安备 33010602011771号