【基础算法】排序算法 —— 快速排序
| 排序算法 | 时间复杂度 | 空间复杂度 | 稳定性 | 算法核心 |
| 快速排序 | O(nlog2n) | O(1) | 不稳定 | 比较交换 |
一、算法原理
快速排序的核心思想是:
- 从待排序数组中任选一个数字作为 pivot(分区点),然后遍历所有数组元素,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间,此时,pivot 对应的数字排序完成;再将 pivot 左边和右边的数据,分别按照前面的方法进行排序;
- 分治思想。
示例:使用快速排序对数组 arr = [11,8,3,9,7,1,2,5] 从小到大排序。
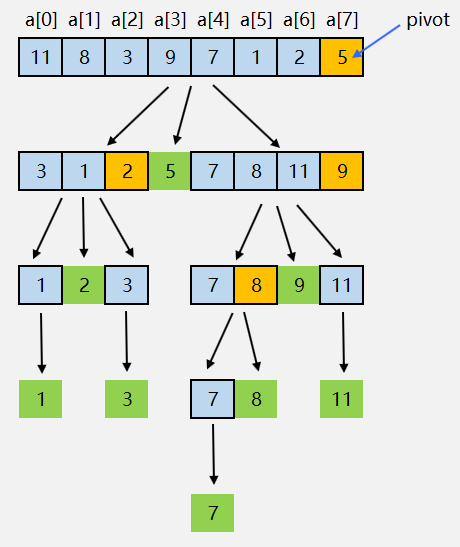
类似于归并排序,快速排序也使用了分治思想,需要用递归来实现。所以,实现快速排序同样需要找到递归的递推公式和终止条件。
递推公式:
quickSort(l...r) = quickSort(l...pivot - 1) + quickSort(pivot + 1...r)
终止条件:
l >= rquickSort(l...r) 表示,给下标从 l 到 r 之间的数组排序。首先,使用分区函数找到 pivot,把小于 pivot 的元素放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。然后,使用同样的办法分别排序 l 到 pivot - 1 的区间、pivot + 1 到 r 的区间。
上述递推公式转换成伪代码如下:
quickSort(arr, l, r) {
if (l >= r) { // 递归终止条件
return
}
// 获取分区点,将小于分区点的元素放在其左边,大于分区点的元素放在其右边
pivot = partition(arr, l, r)
// 分治递归
quickSort(arr, l, pivot - 1)
quickSort(arr, pivot + 1, r)
}
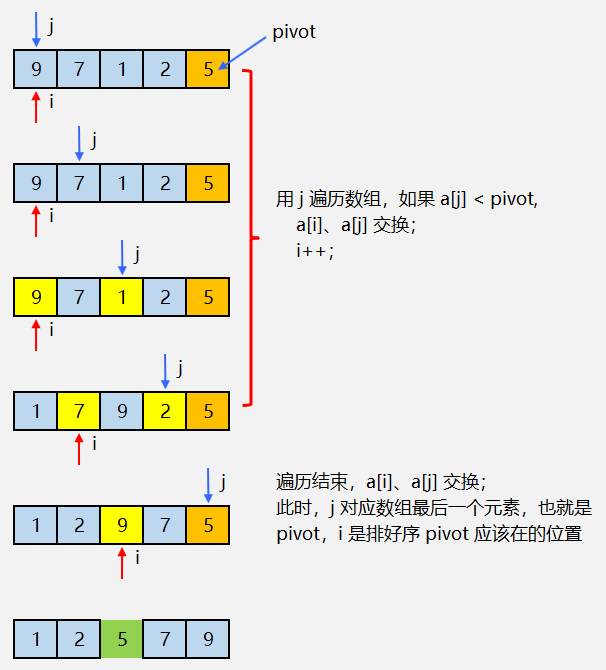
partition 函数的作用是:随机选择一个数字作为 pivot(一般选择最后一个元素),然后遍历所有数组元素,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间,并且返回 pivot 的下标。写成伪代码如下:
partition(arr, l, r) {
pivot = arr[r] // 选择最后一个元素作为分区点
i = l // 小于分区点的索引,初始在数组第一个元素
for (j = l; j < r; j++) {
if (arr[i] < pivot) {
swap(arr, i, j) // 小于分区点的值,交换至 i 对应的位置
i++
}
}
// i 左边都是小于分区点的元素,右边都是大于分区点的元素,所以 i 就是分区点排好序应该在的位置
swap(arr, i, r)
return i
图示如下:
二、代码实现
/**
* 快速排序,时间复杂度 O(nlogn),空间复杂度 O(1),不稳定
*
* @param arr 待排序数组
* @param left 待排序数组左边索引
* @param right 待排序数组右边索引
*/
public static void quickSort(int[] arr, int left, int right) {
if (left >= right) { // 递归终止条件
return;
}
// 获取分区点,将小于分区点的元素放在其左边,大于分区点的元素放在其右边
int pivot = partition(arr, left, right);
// 分治递归
quickSort(arr, left, pivot - 1);
quickSort(arr, pivot + 1, right);
}
private static int partition(int[] arr, int left, int right) {
int pivot = arr[right]; // 选择最后一个元素作为分区点
int i = left; // 小于分区点的索引,初始在数组第一个元素
for (int j = i; j < right; j++) {
if (arr[j] < pivot) { // 小于分区点的值,交换至 i 对应的位置
swap(arr, i, j);
i++;
}
}
// i 左边都是小于分区点的元素,右边都是大于分区点的元素,所以 i 就是分区点排好序应该在的位置
swap(arr, i, right);
return i;
}三、算法评价
3.1 时间复杂度
最好时间复杂度:O(nlogn)
快速排序也是用递归来实现的。对于递归代码的时间复杂度,归并排序里详细分析过,这里也适用。如果每次分区操作,都能正好把数组分成大小接近相等的两个小区间,那快速排序的时间复杂度递推求解公式跟归并排序是相同的。所以,快速排序的时间复杂度也是 O(nlogn)。
最坏时间复杂度:O(n2)
最好时间复杂度成立的条件是,每次分区操作,都能把数组分成大小接近相等的两个小区间。但是,这种情况很难实现,在最坏的情况下,比如数组 [1,3,5,7,9,11,13],每次选择最后一个元素作为 pivot,得到的两个区间是不均等的,需要进行 n 次分区操作,每次分区平均要扫描 n/2 个元素。这时候,快速排序的时间复杂度退化为 O(n2)。
平均时间复杂度:O(nlogn)
最好时间复杂度和最坏时间复杂度,对应分区极其均衡和极其不均衡的情况。
快速排序的平均情况时间复杂度分析需要用到递归树,这里直接给出结论:大部分情况下的时间复杂度都可以做到 O(nlogn),只有在极端情况下,才会退化到 O(n2)。不仅如此,快速排序算法时间复杂度退化到 O(n2) 的概率非常小,可以通过合理地选择 pivot 来避免这种情况。
3.2 空间复杂度
快速排序的 partition() 函数,只需要常量级的临时空间,所以它的空间复杂度为 O(1),是一个原地排序算法。
3.3 稳定性
快速排序的 partition() 函数,在分区过程中涉及交换操作,如果数组中有两个相同元素,比如数组 [6,8,7,6,3,5,4],在第一次分区操作后,两个 6 的先后位置会被改变。所以,快速排序不是一个稳定的排序算法。
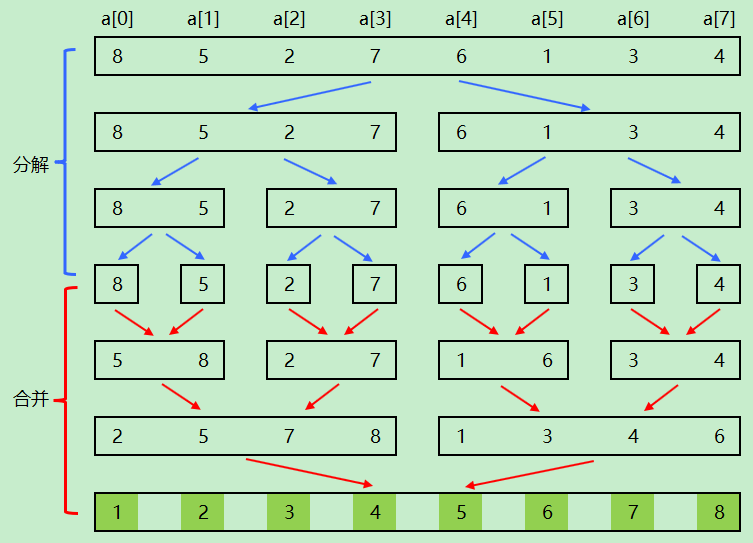
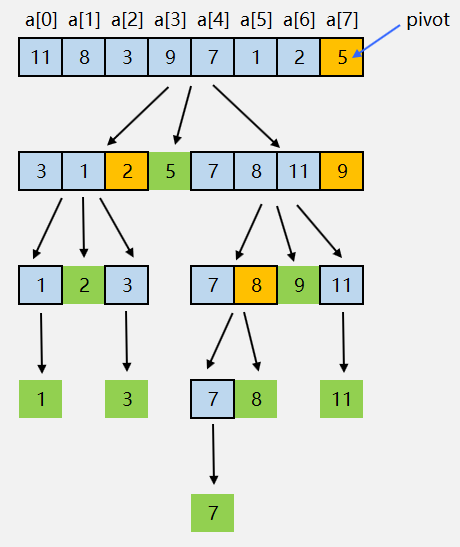
四、快速排序与归并排序的区别
归并排序
快速排序
归并排序与快速排序的区别主要有:
- 归并排序的处理过程是由下到上,先处理子问题,然后再合并。而快速排序正好相反,它是先分区,然后再处理子问题,处理过程是从上到下的。
- 归并排序稳定,快速排序不稳定。
- 归并排序不是原地排序算法,快速排序是原地排序算法。
本文来自博客园,作者:有点成长,转载请注明原文链接:https://www.cnblogs.com/luwei0424/p/17742941.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号