
spider-通过scrapyd网页管理工具执行scrapy框架
1.首先写一个scrapy框架爬虫的项目
scrapy startproject 项目名称 # 创建项目 cd 项目名称 scrapy genspider 爬虫名称 爬虫网址(www.xxxx) #生成一个爬虫 scrapy crawl 爬虫名称 # 启动爬虫
2.部署环境
pip install scrapyd
pip install scrapyd-client
3.在爬虫项目目录下输入命令:scrapyd,已经在本地6800端口运行

4.在爬虫根目录执行:scrapyd-deploy,如果提示不是内部命令,需要到python目录下scripts下新建一个名为scrapyd-deploy.bat的文件,最好复制,其中有必要的空格可能会遗漏导致报错,路径参考各自的路径
@echo off "C:\Users\lu\AppData\Local\Programs\Python\Python37-32\python.exe" "C:\Users\lu\AppData\Local\Programs\Python\Python37-32\Scripts\scrapyd-deploy" %*
5.在爬虫项目根目录下执行:
scrapyd-deploy 爬虫名称 -p 爬虫项目名称
6.如遇到报错:Unknown target: 爬虫名称,找到该爬虫项目的scrapy.cfg,作如下修改:
[deploy:abckg] # 加冒号爬虫名称 url = http://localhost:6800/ # 去掉井号 project = ABCkg # 项目名称
7.重新执行第5条操作:此时提示ok

8.如果打开上图中链接显示状态为error,可以直接在6800端口复制:curl http://localhost:6800/schedule.json -d project=default -d spider=somespider在cmd命令行执行,可以得到状态:ok
curl http://localhost:6800/schedule.json -d project=项目名称 -d spider=爬虫名称
若遇到提示curl不是内部命令,可以在git bash里执行。
9.此时该项目已经部署到网页上

10.点击jobs,此时scrapy项目已经在运行中,点击右侧log可以查看爬虫日志
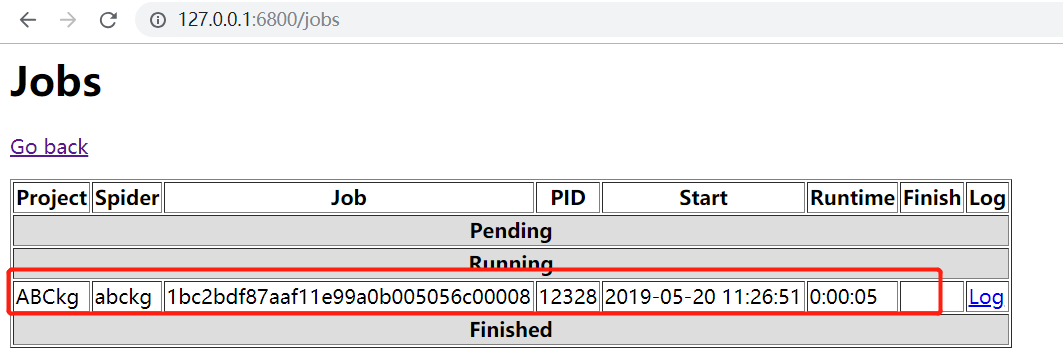
至此! 完毕!!完美实现通过scrapyd网页管理工具执行scrapy框架
python 中文名:蟒蛇,设计者:Guido van Rossum

 浙公网安备 33010602011771号
浙公网安备 33010602011771号