操作系统学习笔记(五) 页面置换算法
操作系统将内存按照页的进行管理,在需要的时候才把进程相应的部分调入内存。当产生缺页中断时,需要选择一个页面写入。如果要换出的页面在内存中被修改过,变成了“脏”页面,那就需要先写会到磁盘。页面置换算法,就是要选出最合适的一个页面,使得置换的效率最高。页面置换算法有很多,简单介绍几个,重点介绍比较重要的LRU及其实现算法。
一、最优页面置换算法
最理想的状态下,我们给页面做个标记,挑选一个最远才会被再次用到的页面。当然,这样的算法不可能实现,因为不确定一个页面在何时会被用到。
二、最近未使用页面置换算法(NRU)
系统为每一个页面设置两个标志位:当页面被访问时设置R位,当页面(修改)被写入时设置M位。当发生缺页中断时,OS检查所有的页面,并根据它们当前的R和M位的值,分为四类:
(1)!R&!M(2)!R&M(3)R&!M(4)R&M
编号越小的类,越被优先换出。即在最近的一个时钟滴答内,淘汰一个没有被访问但是已经被修改的页面,比淘汰一个被频繁使用但是“clean”的页面要好。
三、先进先出页面置换算法(FIFO)及其改进
这种算法的思想和队列是一样的,OS维护一个当前在内存中的所有页面的链表,最新进入的页面在尾部,最久的在头部,每当发生缺页中断,就替换掉表头的页面并且把新调入的页面加入到链表末尾。
这个算法的问题,显然是太过于“公正了”,没有考虑到实际的页面使用频率。
一种合理的改进,称为第二次机会算法。即给每个页面增加一个R位,每次先从链表头开始查找,如果R置位,清除R位并且把该页面节点放到链表结尾;如果R是0,那么就是又老又没用到,替换掉。
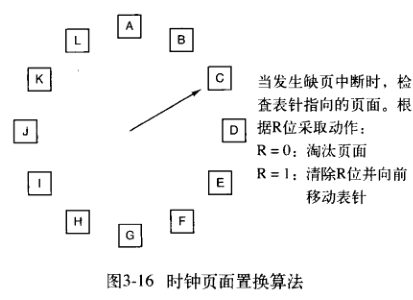
四、时钟页面置换算法(clock)
这种算法只是模型像时钟,其实就是一个环形链表的第二次机会算法,表针指向最老的页面。缺页中断时,执行相同的操作,包括检查R位等。
五、最近最少使用页面置换算法(LRU)
缺页中断发生时,置换未使用时间最长的页面,称为LRU(least recently used)。
LRU是可以实现的,需要维护一个包含所有页面的链表,并且根据实时使用情况更新这个链表,代价是比较大的。
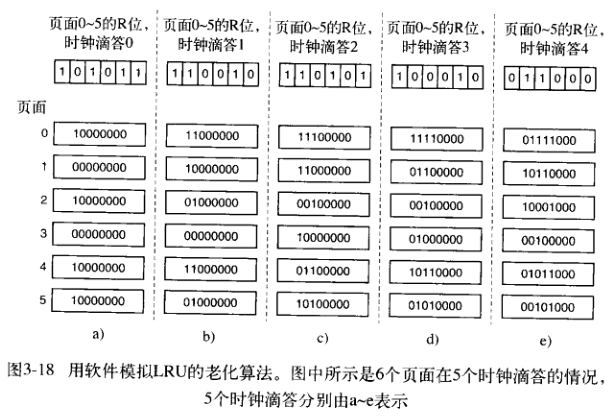
于是,需要对这个算法进行一些改进,也可以说是简化。将每一个页面与一个计数器关联,每次时钟终端,扫描所有页面,将每个页面的R位加到计数器上,这样就大致跟踪了每个页面的使用情况。这种方法称为NFU(not frequently used,最不常用)算法。
这样还是存在一个问题,即很久之前的一次使用,与最近的使用权重相等。
所以,再次改进,将计数器在每次时钟滴答时,右移一位,并把R位加在最高位上。这种算法,称为老化(aging)算法,增加了最近使用的比重。
老化算法只能采用有限的位数,所以可能在一定程度上精度会有所损失。
六、工作集算法
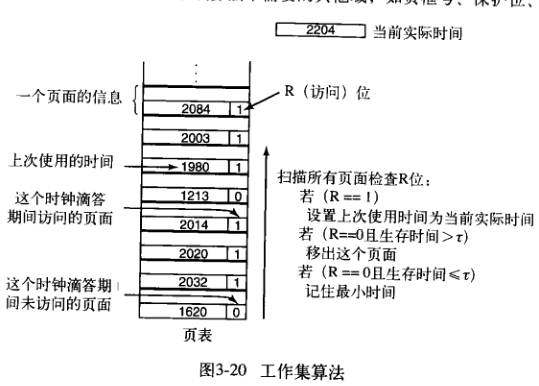
简单来说,工作集就是在最近k次内存访问所使用过的页面的集合。原始的工作集算法同样代价很大,对它进行简化:在过去Nms的北村访问中所用到的页面的集合。
所以,在实现的时候,可以给每个页面一个计时器。需要置换页面时,同实际时间进行对比,R为1,更新到现在时间;R为0,在规定阈值之外的页面可以被置换。
同样,这个算法也可以用时钟的思想进行改进。
七、Linux使用的页面置换算法
Linux区分四种不同的页面:不可回收的、可交换的、可同步的、可丢弃的。
不可回收的:保留的和锁定在内存中的页面,以及内核态栈等。
可交换的:必须在回收之前写回到交换区或者分页磁盘分区。
可同步的:若为脏页面,必须要先写回。
可丢弃的:可以被立即回收的页面。
Linux并没有像我们之前单纯讨论算法时那样,在缺页中断产生的时候才进行页面回收。Linux有一个守护进程kswapd,比较每个内存区域的高低水位来检测是否有足够的空闲页面来使用。每次运行时,仅有一个确定数量的页面被回收。这个阈值是受限的,以控制I/O压力。
每次执行回收,先回收容易的,再处理难的。回收的页面会加入到空闲链表中。
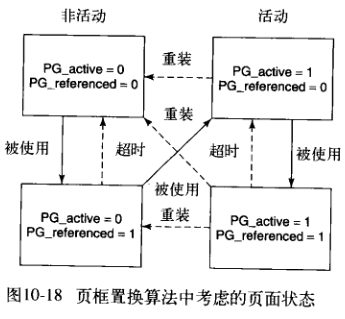
算法是一种改进地LRU算法,维护两组标记:活动/非活动和是否被引用。第一轮扫描清除引用位,如果第二轮运行确定被引用,就提升到一个不太可能回收的状态,否则将该页面移动到一个更可能被回收的状态。
处于非活动列表的页面,自从上次检查未被引用过,因而是移除的最佳选择。被引用但不活跃的页面同样会被考虑回收,是因为一些页面是守护进程访问的,可能很长时间不再使用。
另外,内存管理还有一个守护进程pdflush,会定期醒来,写回脏页面;或者可用内存下降到一定水平后被内核唤醒。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号