TransE模型(tensorflow框架)
代码链接:
https://github.com/ZichaoHuang/TransE
代码笔记:
batch-size:
batch-size中文翻译是批量大小,所谓的批量是指学习样本的数量,因为在训练模型时需要将样本图像全部读入到内存中,这么做的原因是提升收敛速度。
如果每次读一个图像到内存然后提取特征然后再取一张,这样有一个问题:深度学习中是随机取样本,并且每次从磁盘读出来也挺耗时的,如果这次是一张图像,下次随机取样本不能保证图像不会重复,所以最好的方式是一次性将图像全部读入内存中然后进行特征提取。
但是这样就会出现一个问题,那就是内存原因,如果样本过多的情况下内存会被塞满,那么就需要一个参数来控制它,一次读内存的大小,如一次读多少张样本进来,那么这个参数就是由Batch-size来控制。
如你的样本是500张,那么Batch-Size大小是250张,那么每次会随机抽250张照片到内存里来进行特征提取,虽然也会有重复性,但是比起一张张的读这样的效率是大大提升的,收敛速度变快了,因为在深度学习中认为从内存中读一次算一次训练,如果你从磁盘读一张上来然后提取样本后就会将这个特征写入神经元,这样的话局部权重可靠性会下降,所以最好的方式是每次读特定大小的图像进行一次特征提取是最好的,因为特征越多权重越可靠。
set:
set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集(&)、差集(-)、并集(|)等。


并集:
a = set([(1,2,3),(3,5,7),(6,2,0)])|set([(1,2,3),(6,5,7),(6,2,0),(7,5,3)])|set([(4,5,6),(9,5,10),(6,3,1),(8,6,7)])
{(8, 6, 7), (6, 2, 0), (7, 5, 3), (3, 5, 7), (1, 2, 3), (6, 5, 7), (6, 3, 1), (9, 5, 10), (4, 5, 6)}
os.path.join()函数:连接两个或更多的路径名组件
1.如果各组件名首字母不包含'/',则函数会自动加上 2.如果有一个组件是一个绝对路径,则在它之前的所有组件均会被舍弃 3.如果最后一个组件为空,则生成的路径以一个'/'分隔符结尾
代码:

import os Path1 = 'home' Path2 = 'develop' Path3 = 'code' Path4 = 'D:\yan\yan_1\studio\learning_assignment' Path5 = '' Path10 = Path1 + Path2 + Path3 Path20 = os.path.join(Path1,Path2,Path3) print ('Path10 = ',Path10) print ('Path20 = ',Path20) Path30 = os.path.join(Path1,Path4) print ('Path30 = ',Path30) Path40 = os.path.join(Path2,Path5) print ('Path40 = ',Path40)
结果:
Path10 = homedevelopcode Path20 = home\develop\code Path30 = D:\yan\yan_1\studio\learning_assignment Path40 = develop\
pandas.read_table:
文本文件的读取:当要读取外部文件时,一般使用Pandas模块中的read_table函数或read_csv函数。这里的“或”并不是指每个函数只能读取一种格式的数据,而是这两种函数均可以读取文本文件的数据。
dict(zip)函数:zip()函数遍历多个列表方法
在对列表的元素进行找寻时,会频繁的说到遍历的理念。对于复杂的遍历要求,如多个列表中查找就显然不适合用for循环。本篇所要带来的时zip()函数的方法,能够对多个迭代器进行遍历。下面我们就python中zip的说明,语法,使用注意点进行讲解,然后带来遍历多个列表的实例。
1.说明
zip()函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
2.语法
zip(iterable,...)
#其中iterable,...表示多个列表,元组,字典,集合,字符串,甚至还可以为range()区间。
3.注意
(1)zip可以平行地遍历多个迭代器,如果可迭代对象的长度不相同将按短的序列为准
(2)python3中zip相当于生成器,遍历过程中产生元组,python2会把元组生成好,一次性返回整份列表
4.实例
使用zip()函数一次处理两个或多个列表中的元素:
alist = ['a1','a2','a3'] blist = ['1','2','3'] for a,b in zip(alist,blist): print(a,b)
结果:
a1 1 a2 2 a3 3
python zip()函数实例扩展:
两个或者多个list
a=[1,2,3] b=[4,5,6] c=[7,8,9,10] print(list(zip(a,b))) print(list(zip(a,b,c)))
结果:
[(1, 4), (2, 5), (3, 6)]
[(1, 4, 7), (2, 5, 8), (3, 6, 9)]
#三个list去zip(),返回的对象的长度和最小的迭代器一致
将zip对象转换成字典看看
a=[1,2,3] d=[['a','b','c'],['aa','bb','cc'],['aaa','bbb','ccc']] print(dict(zip(a,d)))
结果:
{1: ['a', 'b', 'c'], 2: ['aa', 'bb', 'cc'], 3: ['aaa', 'bbb', 'ccc']}
f(X) for X in Z的用法
发现f(X) for X in Z结构的主要用法是对Z中的每一个X单位都执行f(X)操作
print([x for x in range(1, 11)]) print([x * 2 for x in range(1, 11)]) print([x * x for x in range(1, 11)])
结果:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10] [2, 4, 6, 8, 10, 12, 14, 16, 18, 20] [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
python中np.random.permutation函数实例详解:
总体来说他是一个随机排列函数,就是将输入的数据进行随机排列,文档指出,此函数只能针对一位数据随机排列,对于多维数据只能对第一维度的数据进行随机排列。
简而言之:np.random.permutation函数的作用就是按照给定列表生成一个打乱后的随机列表
import numpy as np data = np.array([1, 2, 3, 4, 5, 6, 7]) a = np.random.permutation(data) b = np.random.permutation([5, 0, 9, 0, 1, 1, 1]) print(a) print("data:", data) print(b)
print(np.random.permutation(9))
结果:
[1 3 6 7 2 5 4] data: [1 2 3 4 5 6 7] [1 1 0 0 1 9 5]
[5 6 0 1 4 7 8 2 3]
yield:
首先,如果你还没有对yield有个初步分认识,那么你先把yield看作"return",这个是直观的,它首先是个return,普通的return是什么意思,就是在程序中返回某个值,返回之后程序就不再往下运行了。看做return 之后再把它看做是一个生成器(generator)的一部分(带yield的函数才是真正的迭代器),好了,如果你对这些不明白的话,就先把yield看做return,然后直接看下面的程序,你就会明白yield的全部意思了:
def foo(): print("starting...") while True: res = yield 4 print("res:",res) g = foo() print(next(g)) print("*"*20) print(next(g))
结果:
starting... 4 ******************** res: None 4
解释代码运行顺序,相当于代码单步调试:
1.程序开始执行之后,因为foo函数中有yield关键字,所以foo函数并不会真的执行,而是先得到一个生成器g(相当于一个对象)
2.直到调用next方法,foo函数正式开始执行,先执行foo函数中的print方法,然后进入while循环
3.程序遇到yield关键字,然后把yield想想成return ,return了一个4之后,程序停止,并没有执行赋值给res操作,此时next(g)语句执行完成,所以输出的前两行(第一个是while上面的print的结果,第二个是return出的结果)是执行print(next(g))的结果。
4.程序执行print("*"*20),输出20个*
5.又开始执行下面的print(next(g)),这个时候和上面那个差不多,不过不同的是,这个时候是从刚才那个next程序停止的地方开始执行的,也就是要执行res的赋值操作,这时候要注意,这个时候赋值操作的右边是没有值的(因为刚才那个是return出去了,并没有给赋值操作的左边传参数),所以这个时候res赋值是None,所以接着下面的输出就是res:None.
6.程序会继续在while里执行,又一次碰到yield,这个时候同样return 出4,然后程序停止,print函数输出的4就是这次return出的4.
yield和return的关系和区别:带yield的函数是一个生成器,而不是一个函数了,这个生成器有一个函数就是next函数,next就相当于"下一步"生成哪个数,这一次的next开始的地方是接着上一次的next停止的地方执行的,所以调用next的时候,生成器并不会从foo函数的开始执行,只是接着上一步停止的地方开始,然后遇到yield后,return出要生成的数,此步就结束。
def foo(): print("starting...") while True: res = yield 4 print("res:",res) g = foo() print(next(g)) print("*"*20) print(g.send(7))
再看一个这个生成器的send函数的例子,这个例子就把上面那个例子的最后一行换掉了,输出结果:
starting... 4 ******************** res: 7 4
send函数的概念:send是发送一个参数给res的,因为上面讲到,return的时候,并没有把4赋值给res,下次执行的时候只好继续执行赋值操作,只好赋值为None了,而如果用send的话,开始执行的时候,先接着上一次(return 4之后)执行,先把7赋值给了res,然后执行next的作用,遇见下一回的yield,return出结果后结束。
5.程序执行g.send(7),程序会从yield关键字那一行继续向下运行,send会把7这个值赋值给res变量
6.由于send方法中包含next()方法,所以程序会继续向下运行执行print方法,然后再次进入while循环
7.程序执行再次遇到yield关键字,yield会返回后面的值后,程序再次暂停,直到再次调用next方法或send方法。
为什么使用yield生成器,是因为如果用List的话,会占用更大的空间,比如说取0,1,2,3,4,5,6......1000
你可能会这样:
for n in range(1000): a=n
这个时候range(1000)就默认生成一个含有1000个数的list了,所以很占内存。
这个时候可以用yield组合成生成器进行实现,也可以用xrange(1000)这个生成器实现
yield组合:
def foo(num): print("starting...") while num<10: num=num+1 yield num for n in foo(0): print(n)
输出:
starting...
1
2
3
4
5
6
7
8
9
10
xrange(1000):
for n in xrange(1000): a=n
其中要注意的是python3时已经没有xrange()了,在python3中,range()就是xrange(),在python3中查看range()的类型,它已经是个<class 'range'>了,而不是一个list。
np.random.binomial()二项式分布函数:
本文以二项式分布的理论概念为起点,对该函数进行解释。
二项式分布:二项分布是由伯努利提出的概念,指的是重复n次(注意:这里的n和binomial()函数参数n不是一个意思)独立的伯努利试验,如果事件X服从二项式分布,则可以表示为X~B(n,p),则期望E(X)=np,方差D(X)=np(1-p).简单来讲就是在每次试验中只有两种可能的结果(例如:抛一枚硬币,不是正面就是反面,而掷六面体色子就不是二项式分布),而且两种结果发生与否相互对立,并且相互独立,与其它各次试验结果无关,事件发生与否的概率在每一次独立试验中都保持不变。
函数原型及参数:numpy.random.binomial(n,p,size=None)
官方参数的解释如下:

逐个参数进行解释:
参数n:一次试验的样本数n,并且相互不干扰。
参数p:事件发生的概率p,范围[0,1]。这里有个理解的关键就是"事件发生"到底是指的什么事件发生?准确来讲是指:如果一个样本发生的结果要么是A要么是B,事件发生指的是该样本其中一种结果发生。
参数size:限定了返回值的形式(具体见上面return的解释)和实验次数。当size是整数N时,表示实验N次,返回每次实验中事件发生的次数;size是(X,Y)时,表示实验X*Y次,以X行Y列的形式输出每次试验中事件发生的次数。(如果将n解释为试验次数而不是样本数的话,这里返回数组中数值的意义将很难解释)。
return返回值:以size给定的形式,返回每次试验事件发生的次数,次数大于等于0且小于等于参数n.注意:每次返回的结果具有随机性,因为二项式分布本身就是随机试验。
样例:
例1:n=1时,重复伯努利试验。
一次抛一枚硬币试验,正面朝上发生的概率为0.5,做10次实验,求每次试验发生正面朝上的硬币个数:
test = np.random.binomial(1, 0.5, 10) print(test)
输出:
[1 0 0 1 0 1 1 1 0 1]
例2:n>1时,多个样本进行试验:
一次抛5枚硬币,每枚硬币正面朝上概率为0.5,做10次试验,求每次试验发生正面朝上的硬币个数:
test = np.random.binomial(5, 0.5, 10) print(test)
输出:
[4 1 1 4 4 2 2 3 3 3]
例3:
size为元组的形式时:一次抛5枚硬币,每枚硬币正面朝上概率为0.5,做50次试验,求每次试验发生正面朝上的硬币个数:
import numpy as np test = np.random.binomial(5, 0.5, (10, 5)) print(test)
输出:
[[2 4 3 3 5] [1 2 2 3 3] [3 5 1 3 2] [2 4 1 3 4] [2 2 3 4 3] [2 4 2 4 3] [1 2 3 2 3] [3 3 1 2 2] [3 3 2 2 1] [2 3 1 1 2]]
python queue get/put方法_Python Queue模块详解
python的Queue模块提供了一种适用于多线程编程的FIFO实现。它可用于在生产者和消费者之间线程安全地传递消息或其他数据,因此多个线程可以共用同一个Queue实例。
Queue类实现了一个基本的先进先出(FIFO)容器使用put()将元素添加导序列尾端,get()从队列尾部移除元素。
Queue介绍:
1.queue是python中的标准库,俗称队列,可以直接import引用
2.在python中,多个线程之间的数据是共享的,多个线程进行数据交换的时候,不能够保证数据的安全性和一致性,所以当多个线程需要数据交换的时候,队列就出现了。队列可以完美解决线程间的数据交换,保证线程间数据的安全性和一致性。
Queue模块中的常用方法:
Queue.Queue(maxsize=0) FIFO, 若是maxsize小于1就表示队列长度无限
Queue.qsize() 返回队列的大小
Queue.empty() 若是队列为空,返回True,反之False
Queue.full() 若是队列满了,返回True,反之False
Queue.get([block, [timeout]]) 读队列,timeout为等待时间
Queue.put(item, [block, [timeout]]) 写队列,timeout为等待时间
Queue.queue.clear() 清空队列
queue.get():调用队列对象的get()方法从对头删除并返回一个项目。可选参数为block,默认为True。如果队列为空且block为True,get()就使调用线程暂停,直至有项目可用。如果队列且空且block为False,队列将引发Empty异常。
Python queue模块有三种队列及构造函数:
1.Python queue模块的FIFO队列先进先出。 class queue.queue(maxsize)
2.LIFO类似于堆,即先进后出。 class queue.Lifoqueue(maxsize)
3.还有一种时优先级队列级别越低越先出来。 class queue.Priorityqueue(maxsize)
tf.placeholder函数说明:
函数形式:
tf.placeholder( dtype, shape=None, name=None )
参数:
1.dtype:数据类型。常用的是tf.float32,tf.float64等数值类型
2.shape:数据形状。默认是None,就是一维值,也可以是多维(比如[2,3],[None,3]表示列是3,行不定)
3.name:名称
为什么要用placeholder?
Tensorflow的设计理念称之为计算流图,在编写程序时,首先构筑整个系统的graph,代码并不会直接生效,这一点和python的其他数值计算库(如Numpy等)不同,graph为静态的,类似于docker中的镜像。然后,在实际的运行时,启动一个session,程序才会真正的运行。这样做的好处就是:避免反复地切换底层程序实际运行的上下文,tensorflow帮你优化整个系统的代码。我们知道,很多python程序的底层为C语言或者其他语言,执行一行脚本,就要切换一次,是有成本的。tensorflow通过计算流图的方式,帮你优化整个session需要执行的代码,还是很有优势的。
所以placeholer()函数是在神经网络构建graph的时候在模型中的占位,此时并没有把要输入的数据传入模型,它只会分配必要的内存。等建立session,在会话中,运行模型的时候通过feed_dict()函数向占位符喂入数据。
简而言之,tf.placeholder()是一个占位符,通俗的来说就是先定义一个变量形参,然后再sess会话里面赋值进去!
情景:
a,b是不确定的数
我要计算a*b的结果c,并对结果c进行形状的改变,然后形变之后的结果再进行操作!
下一步的操作对象是上一步的结果,每一步环环相扣,我是不是需要定义一个变量来操作呢?
tf.placeholder()就是一定一个变量
tf.placeholder(tf.int32)是定义一个int类型的变量
tf.placeholder(tf.int32,[3,1])不仅定义了变量的类型,还定了维度,这个维度必须是[3,1]三行一列的!
样例1:
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() scale = tf.compat.v1.placeholder(tf.int32,[3,1]) with tf.compat.v1.Session() as sess: print(sess.run(scale,feed_dict={scale:[[9],[4],[9]]}))
输出:
[[9] [4] [9]]
样例2:
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() input1 = tf.compat.v1.placeholder(tf.float32) input2 = tf.compat.v1.placeholder(tf.float32) output = tf.multiply(input1, input2) with tf.compat.v1.Session() as sess: print(input1) print(sess.run(output, feed_dict={input1: [3.], input2: [4.]}))
输出:
Tensor("Placeholder:0", dtype=float32) [12.]
样例3:
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() x = tf.compat.v1.placeholder(tf.float32,shape=(1024,1024)) y = tf.matmul(x,x) with tf.compat.v1.Session() as sess: rand_array = np.random.rand(1024,1024) print(sess.run(y,feed_dict={x:rand_array}))
输出:
[[262.7244 252.65878 253.40938 ... 250.00443 264.14508 257.73468] [258.5675 247.27864 247.18623 ... 247.19658 257.40994 253.93613] [262.11133 255.60678 253.93532 ... 250.42442 260.86267 263.71664] ... [269.29242 254.32071 254.35452 ... 253.12544 264.6571 262.98016] [257.02737 238.13702 247.56474 ... 240.06412 248.77081 249.37445] [272.74384 264.06516 259.91296 ... 261.17944 274.28125 265.03214]]
占位操作与feed
在数据流图中的结点op代表的就是一次操作,这个操作可以是被封装好的函数。
比如在下面的代码中,tf.placeholder()这个函数就是一次操作,代表图中的一个结点。这个操作起到的作用是创建了占位符。
占位可以理解为在图书馆预约好了位子,但是这个位子暂时还没有人去坐,还是空的。所以对于x与y这两个空位的乘法tf.matmul()暂时也是不起作用的。
# 创建两个浮点数占位符 x = tf.placeholder(tf.float32) y = tf.placeholder(tf.float32) #增加一个矩阵乘法 result1 = tf.matmul(x,y)
placeholder函数占据的空位,将在会话session运行时添上。通过Session.run()的feed_dict参数,我们传进去一个字典,字典中需要给出每个用到placeholder的取值。
通俗来说这个字典里的key就是我们刚才预约好的空位子,value就是坐进位置里面的人。
sess1 = tf.Session() # 传入x和y的值 print(sess1.run(result, feed_dict={x:[[1,0],[0,1]], y:[[2,3],[4,5]]}))
placeholder的目的是为了解决在有限的输入结点上实现大量的输入数据的问题。
它的机制是先占位再传值,也就是在TensorFlow的静态图中先定义好输入数据的入口,等到会话运行时可以一次性批量得传入数据。
下面的代码展示了仅利用两个placeholder完成多次一位向量运算的过程。
Session.run()的feed_dict参数中第二项我们一次性传入三个一维向量(也可以是任意个),然后a将分别和这三个向量做加法运算。
a = tf.placeholder(tf.float32) b = tf.placeholder(tf.float32) #增加一个加法op result2 = tf.add(a,b) sess2 = tf.Session() print(sess2.run(result2, feed_dict={a:[1.0,2.0], b:[[2.0,3.0],[4.0,5.0],[1.0,1.0]]}))
tensorflow的variable本质解析
tensorflow采用C实现,variable就是C语言的变量,tensorflow规定变量必须初始化其实是减少变量的不确定性,在C语言里面,变量可以不初始化,但为初始化的变量的值不可预估。
看代码:
a = tf.Variable([0,0,0])//这其实就相当于C的变量的定义,int a[3];
b= tf.assign(a,[1,2,3])//这其实就是变量的赋值,a[3]={1,2,3};
看完整代码:
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() a=tf.Variable([0,0,0]) op1=tf.compat.v1.assign(a,[1,2,3]) op2=tf.compat.v1.assign(a,[4,5,6]) with tf.compat.v1.Session() as sess: print(op1) print(op2) print(sess.run(op1)) print(sess.run(op2))
输出:
<tf.Variable 'AssignVariableOp' shape=(3,) dtype=int32> <tf.Variable 'AssignVariableOp_1' shape=(3,) dtype=int32> [1 2 3] [4 5 6]
tensorflow之variable scope:
Tensorflow为了更好的管理变量,提供了variable scope机制,其官方解释如下:



确定get_variable的prefixed name
代码示例如下:
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() with tf.compat.v1.variable_scope("tet1"): var3 = tf.compat.v1.get_variable("var3",shape=[2],dtype=tf.float32) print(var3.name) with tf.compat.v1.variable_scope("tet2"): var4 = tf.compat.v1.get_variable("var4",shape=[2],dtype=tf.float32) print(var4.name)
输出:
tet1/var3:0
tet2/var4:0
tf.get_variable使用方法
参数数量及其作用
该函数共有十一个参数,常用的有:
名称 name ;变量规格 shape ; 变量类型 dtype ;变量初始化方式 initializer ;所属于的集合 collections
def get_variable(name, shape=None, dtype=None, initializer=None, regularizer=None, trainable=True, collections=None, caching_device=None, partitioner=None, validate_shape=True, use_resource=None, custom_getter=None):
该函数的作用是创建新的tensorflow变量:常见的initializer有:
常量初始化器 tf.constant_initializer
正态分布初始化器 tf.random_normal_initializer
截断正态分布初始化器 tf.truncated_normal_initializer
均匀分布初始化器 tf.random_uniform_initializer
例子
该例子将分别讲述常见的几种initializer的使用方法
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() # 常量初始化器 v1_cons = tf.compat.v1.get_variable('v1_cons', shape=[1, 4], initializer=tf.constant_initializer()) v2_cons = tf.compat.v1.get_variable('v2_cons', shape=[1, 4], initializer=tf.constant_initializer(9)) # 正太分布初始化器 v1_nor = tf.compat.v1.get_variable('v1_nor', shape=[1, 4], initializer=tf.random_normal_initializer()) v2_nor = tf.compat.v1.get_variable('v2_nor', shape=[1, 4], initializer=tf.random_normal_initializer(mean=0, stddev=5, seed=0)) # 均值、方差、种子值 # 截断正态分布初始化器 v1_trun = tf.compat.v1.get_variable('v1_trun', shape=[1, 4], initializer=tf.compat.v1.truncated_normal_initializer()) v2_trun = tf.compat.v1.get_variable('v2_trun', shape=[1, 4], initializer=tf.compat.v1.truncated_normal_initializer(mean=0, stddev=5, seed=0)) # 均值、方差、种子值 # 均匀分布初始化器 v1_uni = tf.compat.v1.get_variable('v1_uni', shape=[1, 4], initializer=tf.random_uniform_initializer()) v2_uni = tf.compat.v1.get_variable('v2_uni', shape=[1, 4], initializer=tf.random_uniform_initializer(maxval=-1., minval=1., seed=0)) # 最大值、最小值、种子值 with tf.compat.v1.Session() as sess: sess.run(tf.compat.v1.global_variables_initializer()) print("常量初始化器v1_cons:", sess.run(v1_cons)) print("常量初始化器v2_cons:", sess.run(v2_cons)) print("正太分布初始化器v1_nor:", sess.run(v1_nor)) print("正太分布初始化器v2_nor:", sess.run(v2_nor)) print("截断正态分布初始化器v1_trun:", sess.run(v1_trun)) print("截断正态分布初始化器v2_trun:", sess.run(v2_trun)) print("均匀分布初始化器v1_uni:", sess.run(v1_uni)) print("均匀分布初始化器v2_uni:", sess.run(v2_uni))
输出:
常量初始化器v1_cons: [[0. 0. 0. 0.]] 常量初始化器v2_cons: [[9. 9. 9. 9.]] 正太分布初始化器v1_nor: [[-0.08459241 0.00539715 0.02442081 -0.018947 ]] 正太分布初始化器v2_nor: [[-8.48517 -2.4068835 -3.3111846 0.43505585]] 截断正态分布初始化器v1_trun: [[-1.1287853 -1.5295993 -0.18698296 -0.14268586]] 截断正态分布初始化器v2_trun: [[-1.9957881 0.8553612 2.7325907 2.1127698]] 均匀分布初始化器v1_uni: [[-0.04401676 0.02470355 -0.00482636 -0.03729339]] 均匀分布初始化器v2_uni: [[ 0.5779691 -0.41201997 -0.60012674 -0.5415845 ]]
tf.summary.histogram
histogram( name, values, collections=None )
Args:
name: A name for the generated node. Will also serve as a series name in TensorBoard. values: A real numeric Tensor. Any shape. Values to use to build the histogram. collections: Optional list of graph collections keys. The new summary op is added to these collections. Defaults to [GraphKeys.SUMMARIES].
Returns:
A scalar Tensor of type string. The serialized Summary protocol buffer.
收集变量:
#收集高维度的变量参数
tf.compat.v1.summary.histogram(name='weight',values=weight)
tf.name_scope():
tf.name_scope主要结合tf.Variable()来使用,方便参数命名管理。
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() # 也就是说,它的主要目的是为了更加方便地管理参数命名。 # 与 tf.Variable() 结合使用。简化了命名 with tf.name_scope('conv1') as scope: weights1 = tf.Variable([1.0, 2.0], name='weights') bias1 = tf.Variable([0.3], name='bias') # 下面是在另外一个命名空间来定义变量的 with tf.name_scope('conv2') as scope: weights2 = tf.Variable([4.0, 2.0], name='weights') bias2 = tf.Variable([0.33], name='bias') # 所以,实际上weights1 和 weights2 这两个引用名指向了不同的空间,不会冲突 print(weights1.name) print(weights2.name)
输出:
conv1/weights:0
conv2/weights:0
tf.nn.embedding_lookup:
tf.nn.embedding_lookup( params, ids, partition_strategy='mod', name=None, validate_indices=True, max_norm=None )
作用:在params表中按照ids查询向量。params是一个词表,大小为N*H,N为词的数量,H为词向量维度的大小。图中的params大小为3*10,表示有3个词,每个词有10维。一句话中有四个词,对应的id为0,2,0,1,按照ids在params中查找。
(注意此处只是举例说明,Params可以是任意含义的表,不一定是词表,可以是张量,可以是list)
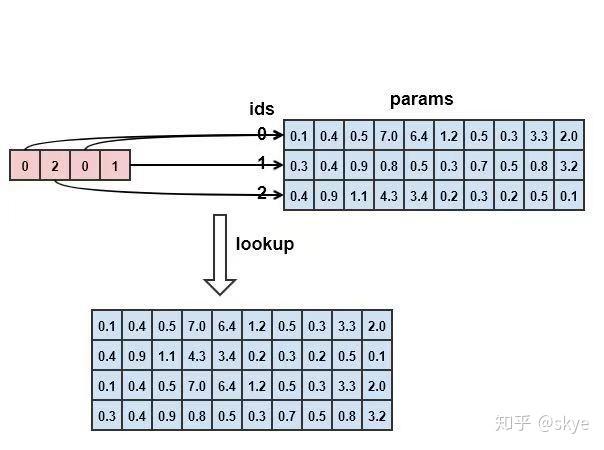
代码:
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() params = tf.constant([[0.1, 0.4, 0.5, 7.0, 6.4, 1.2, 0.5, 0.3, 3.3, 2.0], [0.3, 0.4, 0.9, 0.8, 0.5, 0.3, 0.7, 0.5, 0.8, 3.2], [0.4, 0.9, 1.1, 4.3, 3.4, 0.2, 0.3, 0.2, 0.5, 0.1]]) ids = tf.constant([0, 2, 0, 1]) with tf.compat.v1.Session() as sess: lookup = sess.run(tf.nn.embedding_lookup(params, ids)) print(lookup)
输出:
[[0.1 0.4 0.5 7. 6.4 1.2 0.5 0.3 3.3 2. ] [0.4 0.9 1.1 4.3 3.4 0.2 0.3 0.2 0.5 0.1] [0.1 0.4 0.5 7. 6.4 1.2 0.5 0.3 3.3 2. ] [0.3 0.4 0.9 0.8 0.5 0.3 0.7 0.5 0.8 3.2]]
Python中的[:,0]和[:,1]以及[1:]和[1,:]
先创建一个测试样例
import numpy as np a= np.array([[0,1],[2,3],[4,5],[6,7],[8,9],[10,11],[12,13],[14,15],[16,17],[18,19]]) print(a)
输出结果:
[[ 0 1] [ 2 3] [ 4 5] [ 6 7] [ 8 9] [10 11] [12 13] [14 15] [16 17] [18 19]]
测试[1:]以及[1,:]
print(a[1:]) print('------------') print(a[1,:])
输出:
[[ 2 3] [ 4 5] [ 6 7] [ 8 9] [10 11] [12 13] [14 15] [16 17] [18 19]] ------------ [2 3]
测试[:,0]以及[:,1]
print(a[:,0]) print('------------') print(a[:,1])
输出:
[ 0 2 4 6 8 10 12 14 16 18] ------------ [ 1 3 5 7 9 11 13 15 17 19]
[:,0]就是取所有行第0个数据;[:,1]就是取所有行第1个数据
测试[:0],[:1],[:2]
print(a[:0]) print('------------') print(a[:1]) print('------------') print(a[:2])
输出:
[] ------------ [[0 1]] ------------ [[0 1] [2 3]]
实际应用:
在做知识图谱嵌入时,存好的数据存入dataset,再放入dataloader,然后转换成nump,通过[:,0]就可以取到所有头实体id
dataset = tripleDataset(posDataPath=args.validpath, entityDictPath=args.entpath, relationDictPath=args.relpath) dataloader = DataLoader(dataset, batch_size=len(dataset), shuffle=False, drop_last=False) for tri in dataloader: tri=tri.numpy() print(tri) print('-------------') print(tri[:,0]) exit()
输出:
[[ 6431 52 790] [ 127 326 2874] [13176 3 12512] ... [ 6330 9 5895] [ 7895 26 4826] [ 626 166 1240]] ------------- [ 6431 127 13176 ... 6330 7895 626]
tf.reduce_sum
reduce_sum应该理解为压缩求和,抹去求和,用于降维
1.什么是sum
2.什么是reduce
3.什么是维度(indices,现在均改为了axis和numpy等包一致)
1.什么是维度?什么是轴(axis)?如何索引轴(axis)?
维基百科:维度,又称维数,是数学中独立参数的数目。在物理学和哲学的领域内,指独立的时空坐标的数目。
0维是一点,没有长度。1维是线,只有长度。2维是一个平面,是由长度和宽度(或曲线)形成面积。3维是2维加上高度形成“体积面”。虽然在一般人中习惯了整数维,但在分形中维度不一定是整数,可能会是一个非整的有理数或者无理数。
维度是用来索引一个多维数组中某个具体数所需要最少的坐标数量。
0维,又称0维张量,数字,标量:1;1维,又称1维张量,数组,vector:[1,2,3];2维,又称2维张量,矩阵,二维数组:[[1,2],[3,4]];3维,又称3维张量,立方(cube) ,三维数组:[[[1,2],[3,4]],[[5,6],[7,8]]]
...
再多的维只不过是是把上一个维度当作自己的元素
1维的元素是标量,2维的元素是数组,3维的元素是矩阵。
从0维到3维,边看边念“维度是用来索引一个多维数组中某个具体数所需要最少的坐标。”
axis是多维数组每个维度的坐标。
也就是说,对于[ [[1,2], [3,4]], [[5,6], [7,8]] ]这个3维情况,[[1,2],[3,4]], [[5,6], [7,8]]这两个矩阵,高维的元素低一个维度,因此三维立方的元素是二维矩阵的axis是0,[1,2],[3,4],[5,6],[7,8]这4个数组(二维矩阵的元素是一维数组)的axis是1,而1,2,3,4,5,6,7,8这8个数的axis是2。
越往里axis就越大,依次加1。
2.什么是reduce
对一个n维的情况进行reduce,就是将执行操作的这个维度压缩。还是上面tf.reduce_sum(a,axis=1)的例子,输出[[4,6],[12,14]]是二维,显然是被压缩了,压缩的维度就是被操作的维度,第2个维度,也就是axis=1(0开始索引)。tf.reduce_sum(a,axis=1)具体执行步骤如下:
1.找到a中axis=1的元素,也就是[1,2],[3,4],[5,6],[7,8]这4个数组(两两一组,因为前两个和后两个的地位相同)
2.在axis的维度进行相加也就是[1,2]+[3,4]=[4,6],[5,6]+[7,8]=[12, 14]
3.压缩这一维度,也就是说掉一层方括号,得出[[ 4, 6], [12, 14]]
3.什么是keepdims
keepdims也就是保持维度,直观来看就是“不掉一层方括号”,就是本来应该被压缩的那一层。f.reduce_sum(a, axis=1, keepdims=True)得出[[[ 4, 6]], [[12, 14]]],可以看到还是3维。这种尤其适合reduce完了要和别的同维元素相加的情况。
下面举个多维tensor例子简单说明。下面是个2*3*4的tensor.
[[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
[[13 14 15 16]
[17 18 19 20]
[21 22 23 24]]]
如果计算tf.reduce_sum(tensor,axis=0),axis=0说明是按第一个维度进行求和,也就是说把
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
和
[[13 14 15 16]
[17 18 19 20]
[21 22 23 24]]
相加,所以第一个维度(也就是2)抹去,求和结束得到的tensor_ans是3*4(之前tensor是2*3*4)。显然tensor_ans的元素分别是1+13;2+14;3+15......;12+24。即:
[[1+13 2+14 3+15 4+16]
[5+17 6+18 7+19 8+20]
[9+21 10+22 11+23 12+24]]。
依次类推,如果axis=1,那么求和结果shape是2*4,即:
[[ 1 + 5 + 9 2 + 6+10 3 + 7+11 4 + 8+12]
[13+17+21 14+18+22 15+19+23 16+20+24]]
如果axis=2,那么求和结果shape是2*3,即:
[[1+2+3+4 5+6+7+8 9+10+11+12]
[13+14+15+16 17+18+19+20 21+22+23+24]]
tf.summary.scalar()简介
作用:主要用来显示标量的信息,一般在画loss,accuary时会用到这个函数。
其格式为:
下面展示一些内联代码片
// tf.summary.scalar()用法
tf.summary.scalar(name,tensor,collections=None,family=None)
主要参数
name,生成节点的名字
tensor,包含一个值的实数tensor
collection,图的集合键值的可选列表
family,可选项,设置时用作求和标签名称的前缀,这影响着tensorboard所显示的标签名。
AdamOptimizer
tf.train.AdamOptimizer()函数(在tf2.0版本中改为tf.compat.v1.train.AdamOptimizer())是Adam优化算法:
是一个寻找全局最优点的优化算法,引入了二次方梯度校正
tf.train.AdamOptimizer.__init__( learning_rate=0.001, #张量或浮点值,学习速率 beta1=0.9, #一个浮点值或一个常量浮点张量,一阶矩估计的指数衰减率 beta2=0.999, #一个浮点值或一个常量浮点张量,二阶矩估计的指数衰减率 epsilon=1e-08,#数值稳定性的一个小常数 use_locking=False, #如果True,要使用lock进行更新操作 name='Adam'#应用梯度时为了创建操作的可选名称,默认为Adam )
本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。

机器学习优化器Optimizer的总结:https://zhuanlan.zhihu.com/p/150113660
tf.compat.v1.summary.merge_all()用法
tf.compat.v1.summary.merge_all():合并默认图中收集的所有摘要。
tf.compat.v1.summary.merge_all( key=tf.GraphKeys.SUMMARIES, scope=None, name=None )
Args:
key:GraphKey用于收集摘要。默认为GraphKeys.SUMMARIES
scope:用于筛选摘要操作的可选范围,使用re.math
Returns:
如果未收集任何摘要,则返回无。否则,返回Tensor类型的标量,string其中包含Summary合并产生的序列化协议缓冲区。
Raises:
RuntimeError:如果在启用急切执行的情况下调用。
Eager Compatibility:
与急切执行不兼容。要在渴望执行的情况下编写TensorBoard摘要,请改用tf.contrib.summary.
通俗理解tf.name_scope(),tf.variable_scope()
通过在tf1.15版本上运行,发现第一个代码样例无法运行,具体原因在于tf.variable_scope()会判断是否要共享变量名,而在样例中,因为首先创建了"V1/a1",而在"V2"中设置“reuse=True”去共享变量名,如果继续创建“a1”则会报错,这就是代码无法运行的原因。修改代码如下:
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() with tf.compat.v1.variable_scope('V1', reuse=None): a1 = tf.compat.v1.get_variable(name='a1', shape=[1, 2], initializer=tf.constant_initializer(1)) a2 = tf.Variable(tf.compat.v1.random_normal(shape=[2, 3], mean=0, stddev=1), name='a2') with tf.compat.v1.variable_scope('V2', reuse=None): a3 = tf.compat.v1.get_variable(name='a1', shape=[1], initializer=tf.constant_initializer(1)) a4 = tf.Variable(tf.compat.v1.random_normal(shape=[3, 3], mean=0, stddev=1), name='a2') with tf.compat.v1.Session() as sess: sess.run(tf.compat.v1.initialize_all_variables()) print(a1.name, a1) print(a2.name, a2) print(a3.name, a3) print(a4.name, a4)
输出:
V1/a1:0 <tf.Variable 'V1/a1:0' shape=(1, 2) dtype=float32> V1/a2:0 <tf.Variable 'V1/a2:0' shape=(2, 3) dtype=float32> V2/a1:0 <tf.Variable 'V2/a1:0' shape=(1,) dtype=float32> V2/a2:0 <tf.Variable 'V2/a2:0' shape=(3, 3) dtype=float32>
此时,可以发现“V1”和“V2”没有共享参数,分别各自创建了属于自己的“a1”,"a2",而且分别具备不同的size。
然后,我们修改“V2”为“tf.variable_scope('V2',reuse=True)”,具体如下:
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() with tf.compat.v1.variable_scope('V1', reuse=None): a1 = tf.compat.v1.get_variable(name='a1', shape=[1, 2], initializer=tf.constant_initializer(1)) a2 = tf.Variable(tf.compat.v1.random_normal(shape=[2, 3], mean=0, stddev=1), name='a2') with tf.compat.v1.variable_scope('V2', reuse=True): # a3 = tf.compat.v1.get_variable(name='a1', shape=[1], initializer=tf.constant_initializer(1)) a4 = tf.Variable(tf.compat.v1.random_normal(shape=[3, 3], mean=0, stddev=1), name='a2') with tf.compat.v1.Session() as sess: sess.run(tf.compat.v1.initialize_all_variables()) print(a1.name, a1) print(a2.name, a2) # print(a3.name, a3) print(a4.name, a4)
输出
V1/a1:0 <tf.Variable 'V1/a1:0' shape=(1, 2) dtype=float32> V1/a2:0 <tf.Variable 'V1/a2:0' shape=(2, 3) dtype=float32> V2/a2:0 <tf.Variable 'V2/a2:0' shape=(3, 3) dtype=float32> 如果不注释a:
ValueError: Variable V2/a1 does not exist, or was not created with tf.get_variable(). Did you mean to set reuse=tf.AUTO_REUSE in VarScope?
将“tf.variable_scope('V2',reuse=True)”修改为“tf.variable_scope('V1',reuse=True)”:
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() with tf.compat.v1.variable_scope('V1', reuse=None): a1 = tf.compat.v1.get_variable(name='a1', shape=[1, 2], initializer=tf.constant_initializer(1)) a2 = tf.Variable(tf.compat.v1.random_normal(shape=[2, 3], mean=0, stddev=1), name='a2') with tf.compat.v1.variable_scope('V1', reuse=True): a3 = tf.compat.v1.get_variable(name='a1', shape=[1, 2], initializer=tf.constant_initializer(1)) a4 = tf.Variable(tf.compat.v1.random_normal(shape=[2, 3], mean=0, stddev=1), name='a2') with tf.compat.v1.Session() as sess: sess.run(tf.compat.v1.initialize_all_variables()) print(a1.name, a1) print(a2.name, a2) print(a3.name, a3) print(a4.name, a4)
输出:
V1/a1:0 <tf.Variable 'V1/a1:0' shape=(1, 2) dtype=float32> V1/a2:0 <tf.Variable 'V1/a2:0' shape=(2, 3) dtype=float32> V1/a1:0 <tf.Variable 'V1/a1:0' shape=(1, 2) dtype=float32> V1_1/a2:0 <tf.Variable 'V1_1/a2:0' shape=(2, 3) dtype=float32>
之后,进一步将代码修改为:
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() with tf.compat.v1.variable_scope('V1', reuse=None): a1 = tf.compat.v1.get_variable(name='a1', shape=[1, 2], initializer=tf.constant_initializer(1)) a2 = tf.Variable(tf.compat.v1.random_normal(shape=[2, 3], mean=0, stddev=1), name='a2') with tf.compat.v1.variable_scope('V1', reuse=True): a3 = tf.compat.v1.get_variable(name='a1', shape=[1], initializer=tf.constant_initializer(1)) a4 = tf.Variable(tf.compat.v1.random_normal(shape=[3, 3], mean=0, stddev=1), name='a2') with tf.compat.v1.Session() as sess: sess.run(tf.compat.v1.initialize_all_variables()) print(a1.name, a1) print(a2.name, a2) print(a3.name, a3) print(a4.name, a4)
输出:
ValueError: Trying to share variable V1/a1, but specified shape (1,) and found shape (1, 2).
上述两个样例清楚说明了tf.get_variable()和tf.Variable()的区别:
在一个命名空间“V1”内,tf.get_variable()会执行监测机制,并且节点信息相同,会直接运行,否则会报错,而tf.Variable()会自动创建新的命名空间。
对于tf.name_scope(),tf.variable_scope()邓进行了较为深刻的比较,记录相关笔记:
tf.name_scope(),tf.variable_scope()是两个作用域函数,一般与两个创建/调用变量的函数tf.variable()和tf.get_variable()搭配使用。常用于:
1)变量共享 2)tensorboard画流程图进行可视化封装变量。
通俗理解就是:tf.name_scope(),tf.variable_scope()会在模型中开辟各自的空间,而其中的变量均在这个空间内进行管理,但是之所以有两个,主要还是有着各自的区别。
1.name_scope()和variable_scope():
name_scope和variable_scope主要用于变量共享。其中,变量共享主要涉及两个函数:tf.Variable()和tf.get_variable();即就是必须要在tf.variable_scope()的作用域下使用tf.get_variable()函数。这里用tf.get_variable()而不用tf.Variable(),是因为前者拥有一个变量检查机制,会检测已经存在的变量是否设置为共享变量,如果已经存在的变量没有设置为共享变量,TensorFlow运行到第二个拥有相同名字的变量的时候,就会报错。
注意,tf.Variable()和tf.get_variable()有不同的创建变量的方式:tf.Variable()每次都会新建变量。如果希望重用(共享)一些变量,就需要用到了get_variable(), 它会去搜索变量名,有就直接用,没有再新建。此外,为了对不同位置或者范围的共享进行区分,就引入名字域。既然用到变量名,就涉及到了名字域的概念。这就是为什么会有scope的概念。name_scope作用域操作,variable_scope可以通过设置reuse标志以及初始化方式来影响域下的变量,因为想要达到变量共享的效果,就要在tf.variable_scope()的作用域下使用tf.get_variable()这种方式产生和提取变量。不像tf.Variable()每次都会产生新的变量,tf.get_variable()如果遇到了已经存在名字的变量时,它会单纯的提取这个相同名字的变量,如果不存在名字的变量再创建。
例如:
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() with tf.compat.v1.variable_scope('V1', reuse=None): a1 = tf.compat.v1.get_variable(name='a1', shape=[1], initializer=tf.constant_initializer(1)) a2 = tf.Variable(tf.compat.v1.random_normal(shape=[2, 3], mean=0, stddev=1), name='a2') with tf.compat.v1.variable_scope('V2', reuse=True): a3 = tf.compat.v1.get_variable(name='a1', shape=[1], initializer=tf.constant_initializer(1)) a4 = tf.Variable(tf.compat.v1.random_normal(shape=[2, 3], mean=0, stddev=1), name='a2') with tf.compat.v1.Session() as sess: sess.run(tf.compat.v1.initialize_all_variables()) print(a1.name, a1) print(a2.name, a2) print(a3.name, a3) print(a4.name, a4)
输出:
ValueError: Variable V2/a1 does not exist, or was not created with tf.get_variable(). Did you mean to set reuse=tf.AUTO_REUSE in VarScope?
2.name_scope()和variable_scope()区别
TF中有两种作用域类型:
命名域(name_scope),通过tf.name_scope()或tf.op_scope()创建
变量域(variable_scope),通过tf.variable_scope()或tf.variable_op_scope()创建;
这两种作用域,对于使用tf.Variable()方式创建的变量,具有相同的效果,都会在变量名称前面,加上域名称。对于通过tf.get_variable()方式创建的变量,只有variable_scope名称会加到变量名称前面,而name_scope()不会作为前缀。
举例1:
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() with tf.name_scope("my_name_scope"): v1 = tf.compat.v1.get_variable("var1", [1], dtype=tf.float32) v2 = tf.Variable(1, name="var2", dtype=tf.float32) a = tf.add(v1, v2) print(v1.name) print(v2.name) print(a.name)
输出:
var1:0 my_name_scope/var2:0 my_name_scope/Add:0
举例2:
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() with tf.compat.v1.variable_scope("my_variable_scope"): v1 = tf.compat.v1.get_variable("var1", [1], dtype=tf.float32) v2 = tf.Variable(1, name="var2", dtype=tf.float32) a = tf.add(v1, v2) print(v1.name) print(v2.name) print(a.name)
输出:
my_variable_scope/var1:0 my_variable_scope/var2:0 my_variable_scope/Add:0
总结:
1.name_scope()不会作为tf.get_variable()变量的前缀,但是会作为tf.Variable()的前缀
2.在variable_scope()的作用域下,tf.get_variable()和tf.Variable()都加了scope_name()前缀。因此,在tf.variable_scope()的作用域下,通过get_variable()可以使用已经创建的变量,实现了变量的共享,即可以通过get_variable()在tf.variable_scope()设定的作用域范围内进行变量共享。
3.在重复使用的时候,一定要在代码中强调scope.reuse_variables().
tf.nn.top_k()
tensorflow1.x: tf.nn.top_k()
tensorflow2.x:tf.math.top_k()
api功能为:
用于查找输入tensor的最大值。即输入tensor,沿着最后的一个维度独立查找k个最大元素,返回其值和索引下标。
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() # 选出每一行的最大的前两个数字 # 返回的是最大的k个数字,同时返回的是最大的k个数字在最后的一个维度的下标 a = tf.constant(np.random.rand(3, 4)) _,b = tf.nn.top_k(a,k=2) with tf.compat.v1.Session() as sess: print(sess.run(a)) print(sess.run(_)) print(sess.run(b))
输出:
[[0.47293845 0.52853858 0.4053933 0.73776129] [0.9535238 0.66438971 0.87704678 0.03834804] [0.54107036 0.93889426 0.01262607 0.99136354]] [[0.73776129 0.52853858] [0.9535238 0.87704678] [0.99136354 0.93889426]] [[3 1] [0 2] [3 1]]
函数参数列表为:
tf.nn.top_k( input, k=1, sorted=True, name=None )
input是输入张量;k是需要查找的最大元素的个数;sorted如果是True则按照大小顺序排序;name名字
先总结再举例:
1.一定是沿着最后一个维度去搜索最大值;
2.返回两个,先返回搜索出来的最大值,再返回其索引;
3.最大值和索引是相同形状的。
用tf2举例说明:
1.一维
只有一个轴,只能在这个向量上搜索k个最大值
import tensorflow as tf a = tf.constant([1,2,3,4,5,6]) b, c = tf.math.top_k(a,2) print(b) ''' 打印输出: <tf.Tensor: shape=(2,), dtype=int32, numpy=array([6, 5])> ''' print(c) ''' 打印输出: <tf.Tensor: shape=(2,), dtype=int32, numpy=array([5, 4])> '''
2.二维
有两个轴,shape为(2,3),所以
第一回合(0,x),固定第一个维度为0,让最后一个轴x在0,1,2变化,搜索k个最大值
第二回合(1,x),固定第一个维度为1,让最后一个轴x在0,1,2变化,搜索k个最大值
import tensorflow as tf a = tf.constant([[11,12,13], [21,22,23]]) b, c = tf.math.top_k(a,2) print(b) ''' 打印输出: <tf.Tensor: shape=(2, 2), dtype=int32, numpy= array([[13, 12], [23, 22]])> ''' print(c) ''' 打印输出: <tf.Tensor: shape=(2, 2), dtype=int32, numpy= array([[2, 1], [2, 1]])> '''
3.三维
有三个轴,shape为(2,2,3),所以
第一回合(0,0,x),固定第一个轴为0,固定第二个轴为0,让最后一个轴在x,在0,1,2中变化,搜索k个最大值
第二回合(0,1,x),固定第一个轴为0,固定第二个轴为1,让最后一个轴在x,在0,1,2中变化,搜索k个最大值
第一回合(1,0,x),固定第一个轴为1,固定第二个轴为0,让最后一个轴在x,在0,1,2中变化,搜索k个最大值
第一回合(1,1,x),固定第一个轴为1,固定第二个轴为1,让最后一个轴在x,在0,1,2中变化,搜索k个最大值。
import tensorflow as tf a = tf.constant([ [[111,112,113], [121,122,123]], [[211,212,213], [221,222,223]] ]) b, c = tf.math.top_k(a,2) print(b) ''' 打印输出: <tf.Tensor: shape=(2, 2, 2), dtype=int32, numpy= array([[[113, 112], [123, 122]], [[213, 212], [223, 222]]])> ''' print(c) ''' 打印输出: <tf.Tensor: shape=(2, 2, 2), dtype=int32, numpy= array([[[2, 1], [2, 1]], [[2, 1], [2, 1]]])> '''
multiprocessing多进程模块Process
1 Process进程
1.1 Process进程基础语法
创建进程的类
Process([group[,target[,name [,args [,kwargs]]]]])
group:实质上不使用,线程组,目前还没有实现,库引用中提示必须是None
target:调用对象/目标函数
name:给进程赋予一个名字
args:调用对象的位置参数元组/按位置给目标函数传参
kwargs:调用对象的字典/以字典形式向目标函数传参
实例方法:
p为进程对象的属性
p.start()启动某一个进程
p.join([timeout])主进程阻塞等待子进程timeout时间后的退出,在时间内若主进程已执行完成,暂时不会退出,而是等待子进程的退出,然后处理子进程后自己再退出
p.is_alive()进程的状态
p.run()调用run方法,如果实例进程时未制定传入target,这start执行默认run()方法。
p.terminate()不管任务是否完成,立即停止工作进程。
属性:
p.name 创建的进程的名称
p.authkey
p.exitcode(进程在运行时为None、如果为–N,表示被信号N结束)。
p.pid 创建的子进程PID号
p.daemon 若设置必须置于start调用前进行(和线程的setDeamon功能一样(将父进程设置为守护进程,当父进程结束时,子进程也结束);
默认为false,即主进程执行结束后不退出,等待子进程执行后先退出,然后主进程再退出;
设置为True时,主进程执行后立即退出,并且该主进程的所有子进程也退出
np.linalg.norm()用法总结:
linalg=linear+algebra,也就是线性代数的意思,是numpy库中进行线性代数运算方面的函数。使用np.linalg这个模块,可以计算范数,逆矩阵,求特征值,解线性方程组以及求解行列式等。
np.linalg.norm()用于求范数,linalg本意为linear(线性)+algebra(代数),norm则表示范数
用法:
np.linalg.norm(x, ord=None, axis=None, keepdims=False)
1.x:表示矩阵(一维矩阵也是可以的~)
2.ord:表示范数类型
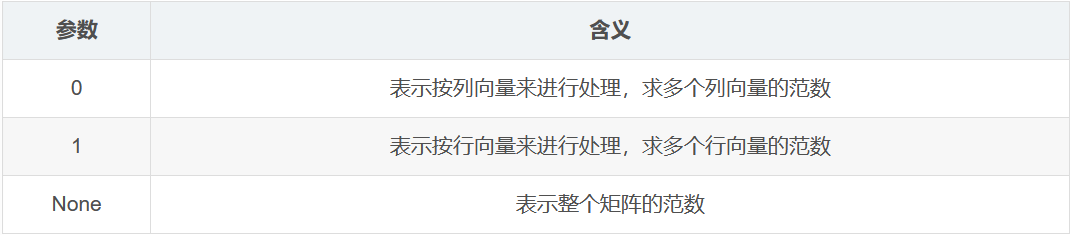
向量的范数:

矩阵的向量:
ord = 1:表示求列和的最大值
ord = 2:|λE-ATA|=0,求特征值,然后求最大特征值得算术平方根
ord = ∞:表示求行和的最大值
ord = None:表示求整体的矩阵元素平方和,再开根号
3.axis:
4.keepdims:表示是否保持矩阵的二位特性,True表示保持,False表示不保持,默认为False
例子
1.默认状态下:
import numpy as np X = [[1, 2, 3], [4, 5, 6]] print(np.linalg.norm(X))
输出:
9.539392014169456
2.改变axis:
import numpy as np X = [[1, 2, 3], [4, 5, 6]] print(np.linalg.norm(X, axis=1))
输出:
[3.74165739 8.77496439]
或
import numpy as np X = [[1, 2, 3], [4, 5, 6]] print(np.linalg.norm(X, axis=0))
输出:
[4.12310563 5.38516481 6.70820393]
3.改变ord:
import numpy as np X = [[1, 2, 3], [4, 5, 6]] print(np.linalg.norm(X, ord=1))
输出:
9.0
import numpy as np X = [[1, 2, 3], [4, 5, 6]] print(np.linalg.norm(X, ord=2))
输出:
9.508032000695724
4.改变keepdims
import numpy as np X = [[1, 2, 3], [4, 5, 6]] print(np.linalg.norm(X, axis=0, keepdims=True))
输出:
[[4.12310563 5.38516481 6.70820393]]
import numpy as np X = [[1, 2, 3], [4, 5, 6]] print(np.linalg.norm(X, axis=0))
输出:
[4.12310563 5.38516481 6.70820393]
【显存不足完美解决方案】Could not create cudnn handle:CUDNN_STATUS_INTERNAL_ERROR
一.问题出现
在使用TensorFlow或者Keras准备进行网络训练时,有时候会出现如下报错:
Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
二.问题分析
有的时候,电脑gpu显存明显是足够的,为何还是会报错呢?
一般情况下,如果不加以限制,很多深度学习框架的代码在运行的时候会申请整个显存空间(即使它不需要那么多的资源,但是它申请了之后就不允许其他的程序使用),所以在这种状态下运行代码,就会出现显存不够用的问题(因为还有其他的程序或操作也需要显存资源)。
三.解决方案
为了解决以上问题,我们在训练网络之前,需要在代码加入一些指令,控制显存的使用,以TensorFLow2为例:
config = tf.compat.v1.ConfigProto(gpu_options=tf.compat.v1.GPUOptions(allow_growth=True))
sess = tf.compat.v1.Session(config=config)
解释:
- tf.compact.v1.ConfigProto()。这是tensorflow2版本的写法,这个方法的作用就是设置运行tensorflow代码的时候的一些配置,例如如何分配显存,是否打印日志等;所以它的参数都是配置名称=True/False(默认为False)这种形式;
- gpu_options=tf.compact.v1.GPUOptions(allow_growth=True)限制GPU资源的使用,此处allow_growth=True是动态分配显存,需要多少,申请多少;
- sess=tf.compact.v1.Session(config=config),让这些配置生效。
Python基本使用(3) -多进程
1.多进程
是一种多核运算,Multiprocessing和多线程threading类似,它弥补了threading的一些劣势,比如GIL。
1.1 添加进程process + 存储进程输出 queue
创建方式与线程的类似
Queue的功能是将每个核或线程的运算结果放在队列中,等到每个线程或核运行完毕后再从队列中取出结果,继续加载运算。原因很简单,多线程调用的函数不能有返回值,所以使用Queue存储多个线程运算的结果。
args的参数只有一个值的时候,参数后面需要加一个逗号,表示args是可迭代的,后面可能还有别的参数,不加逗号会出错
import multiprocessing as mp def job(a): res = 0 for i in range(100): res += i + i ** 2 + i ** 3 a.put(res) if __name__ == '__main__': a = mp.Queue() # 定义一个多线程队列,用来存储结果 p1 = mp.Process(target=job, args=(a,)) # 定义两个线程函数,用来处理同一个任务,注意args的参数 p2 = mp.Process(target=job, args=(a,)) p1.start() p2.start() p1.join() p2.join() res1 = a.get() res2 = a.get() print(res1) print(res2) print(res1 + res2)
输出:
24835800 24835800 49671600
1.2多线程,多进程效率对比
import multiprocessing as mp import threading as td import time def job(q): res = 0 for i in range(1000000): res += i + i ** 2 + i ** 3 q.put(res) # queue def multicore(): q = mp.Queue() # 定义一个多进程队列,用来存储结果 p1 = mp.Process(target=job, args=(q,)) # 定义两个线程函数,用来处理同一个任务,注意args的参数 p2 = mp.Process(target=job, args=(q,)) p1.start() p2.start() p1.join() p2.join() res1 = q.get() res2 = q.get() print('multicore:', res1 + res2) def multithread(): # 多线程 q = mp.Queue() # thread可放入process同样的queue中 t1 = td.Thread(target=job, args=(q,)) t2 = td.Thread(target=job, args=(q,)) t1.start() t2.start() t1.join() t2.join() res1 = q.get() res2 = q.get() print('multithread:', res1 + res2) def normal(): # 普通函数 res = 0 for _ in range(2): for i in range(1000000): res += i + i ** 2 + i ** 3 print('normal:', res) if __name__ == '__main__': st = time.time() normal() st1 = time.time() print('normal time:', st1 - st) multithread() st2 = time.time() print('multithread time:', st2 - st1) multicore() print('multicore time:', time.time() - st2)
输出:
normal: 499999666667166666000000 normal time: 1.3963274955749512 multithread: 499999666667166666000000 multithread time: 1.3174450397491455 multicore: 499999666667166666000000 multicore time: 3.827815532684326
我们发现多核/多进程最快,说明在同时间运行了多个任务。而多线程的运行时间居然比什么都不做的程序还要慢一点,说明多线程还是有一定的短板的。
sess.run()详解
TensorFlow与我们正常的编程思维略有不同:
- 先预定义一些操作/占位符构建graph,所有的操作op和变量都视为节点,TensorFlow中的语句不会立即执行;
- 当构建完graph图后,需要在一个session会话中启动图,启动的第一步是创建一个Session对象。
- 等到开启会话session的时候,才会执行session.run()中的语句。在执行session.run()时,tensorflow并不是计算了整个图,只是计算了与想要fetch的值相关的部分。
创建session对象
tf.compat.v1.Session(
target=’’, graph=None, config=None)
Session对象的方法run()
run(fetches, feed_dict=None, options=None, run_metadata=None)
参数:
- fetches:可以是list或者tensor向量
- feed_dict:以字典的方式填充占位
返回值:sess.run()可以将tensor格式转成numpy格式,在python语言中,返回的tensor是numpy ndarray对象。
feed_dict作用
feed_dict的作用是给使用placeholder创建出来的tensor赋值。其实,他的作用更加广泛:feed使用一个值临时替换一个op的输出结果。你可以提供feed数据作为run()调用的参数。只在调用它的方法内有效,方法结束,feed_dict就会消失。
替换graph中的某个tensor
feed_dict使用一个值临时替换一个op的输出结果
a = tf.add(2, 5) b = tf.multiply(a, 3) with tf.Session() as sess: sess.run(b, feed_dict = {a:15}) # 重新给a赋值为15 运行结果:45 sess.run(b) #feed_dict只在调用它的方法内有效,方法结束,feed_dict就会消失。 所以运行结果是:21
设置graph的输入值
feed_dict可以给使用placeholder创建出来的tensor赋值
# 使用tf.placeholder()创建占位符 ,在session.run()过程中再投递数据 x = tf.placeholder(tf.float32, shape=(1, 2)) #设置矩阵x,用占位符表示 w1 = tf.Variable(tf.random_normal([2, 3],stddev=1,seed=1)) w2 = tf.Variable(tf.random_normal([3, 1],stddev=1,seed=1)) # 创建op, 设置矩阵相乘 a = tf.matmul(x,w1) y = tf.matmul(a,w2) # 启动graph,运行op with tf.Session() as sess: # 对变量进行初始化,变量运行前必须做初始化操作 sess.run(tf.global_variables_initializer()) # 使用feed_dict将数据投入到y中 print(sess.run(y, feed_dict={x:[[0.7, 0.5]]})) #运行结果: [[3.0904665]]
注意:此时的x是一个占位符(placeholder)。我们定义了它的type和shape,但是并没有具体的值。在后面定义graph的代码中,placeholder看上去和普通的tensor对象一样。在运行程序的时候我们用feed_dict的方式把具体的值提供给placeholder,达到了给graph提供input的目的。
placeholder有点像在定义函数的时候用到的参数。我们在写函数内部代码的时候,虽然用到了参数,但并不知道参数所代表的值。只有在调用函数的时候,我们才把具体的值传递给参数。
JoinableQueue
通俗理解:就是可以join的队列,这个队列的特点就是比Queue额外增加了一个Join函数。
Join函数的作用
该函数为阻塞函数,会阻塞直到队列中所有的数据都被处理完毕,它才继续往下运行。
# 会导致进程无法结束 q = JoinableQueue() q.put(1) q.get() q.join()
上述代码进程无法结束,是因为get仅仅是取出数据,而join是等待数据处理完毕,所以取出数据处理结束还得告知队列处理完毕,这里就用到了task_done
q = JoinableQueue() q.put(1) q.get() q.task_done() q.join()
这里task_done用的是计数方法,每告知一次减一次,所以task_done的调用次数必等于队列中的数据个数,join才能正常结束。
q = JoinableQueue() q.put(1) q.put(1) q.get() q.task_done() q.get() q.task_done() q.join()
JoinableQueue([maxsize])
这就像是一个Queue对象,但队列允许项目的使用者通知生成者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
参数介绍
maxsize是队列中允许最大项数,省略则无大小限制。
方法介绍
JoinableQueue的实例p除了与Queue对象相同的方法之外还具有:
q.task_done():使用者使用此方法发出信号,表示q.get()的返回项目已经被处理。如果调用此方法的次数大于从队列中删除项目的数量,将引发ValueError异常
q.join():生产者调用此方法进行阻塞,直到队列中所有的项目均被处理。阻塞将持续到队列中的每个项目均调用q.task_done()方法为止
import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() from multiprocessing import Process,JoinableQueue import time,random,os def consumer(q,name): while True: res=q.get() time.sleep(random.randint(1,3)) print('\033[43m%s 吃 %s\033[0m' %(name,res)) q.task_done() #发送信号给q.join(),说明已经从队列中取走一个数据并处理完毕了 def producer(q,name,food): for i in range(3): time.sleep(random.randint(1,3)) res='%s%s' %(food,i) q.put(res) print('\033[45m%s 生产了 %s\033[0m' %(name,res)) q.join() #等到消费者把自己放入队列中的所有的数据都取走之后,生产者才结束 print("?????") if __name__ == '__main__': q=JoinableQueue() #使用JoinableQueue() #生产者们:即厨师们 p1=Process(target=producer,args=(q,'egon1','包子')) p2=Process(target=producer,args=(q,'egon2','骨头')) p3=Process(target=producer,args=(q,'egon3','泔水')) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,'alex1')) c2=Process(target=consumer,args=(q,'alex2')) c1.daemon=True c2.daemon=True #开始 p1.start() p2.start() p3.start() c1.start() c2.start() p1.join() p2.join() p3.join() #1、主进程等生产者p1、p2、p3结束 #2、而p1、p2、p3是在消费者把所有数据都取干净之后才会结束 #3、所以一旦p1、p2、p3结束了,证明消费者也没必要存在了,应该随着主进程一块死掉,因而需要将生产者们设置成守护进程 print('主')
输出:
egon2 生产了 骨头0
egon3 生产了 泔水0
egon1 生产了 包子0
alex1 吃 骨头0
egon3 生产了 泔水1
egon2 生产了 骨头1
egon3 生产了 泔水2
alex2 吃 泔水0
egon1 生产了 包子1
alex1 吃 包子0
alex1 吃 骨头1
egon2 生产了 骨头2
alex2 吃 泔水1
egon1 生产了 包子2
alex1 吃 泔水2
alex2 吃 包子1
alex2 吃 包子2
alex1 吃 骨头2
?????
?????
?????
主
eval()
eval()其实就是tf.Tensor的Session.run()的另外一种写法,但两者有差别
1.eval():将字符串string对象转化为有效的表达式参与求值运算返回计算结果
2.eval()也是启动计算的一种方式。基于Tensorflow的基本原理,首先需要定义图,然后计算图,其中计算图的函数常见的有run()函数,如sess.run()。同样eval()也是此类函数
3.要注意的是,eval()只能用于tf.Tensor类对象,也就是有输出的Operation。对于没有输出的Operation,可以用.run()或者Session.run();Session.run()没有这个限制。
Tensor.run和Tensor.eval的区别
在会话中需要运行结点,会碰到两种方式:Session.run()和Tensor.eval()
解释一:

- 如果t是tf.Tensor对象,则tf.Tensor.eval是tf.Session.run的缩写(其中sess是当前的tf.get_default_session)。下面的两个代码片段是等价的;
- 在第二个示例中,会话充当上下文管理器,其作用是将其安装为with块的生命周期的默认会话。上下文管理器方法可以为简单用例(比如单元测试)提供更简洁的代码;如果您的代码处理多个图形和会话,则可以更直接地对Session.run()进行显式调用。
解释二:
如果你有一个Tensor,在使用t.eval()时,等价于:tf.get_default_session().run(t)
举例:
t = tf.constant(42.0) sess = tf.Session() with sess.as_default(): # or `with sess:` to close on exit assert sess is tf.get_default_session() assert t.eval() == sess.run(t)
这其中最主要的区别就在于你可以使用sess.run()在同一步获取多个tensor中的值
例如
t = tf.constant(42.0) u = tf.constant(37.0) tu = tf.mul(t, u) ut = tf.mul(u, t) with sess.as_default(): tu.eval() # runs one step ut.eval() # runs one step sess.run([tu, ut]) # evaluates both tensors in a single step
注意到:每次使用eval和run时,都会执行整个计算图,为了获取计算的结果,将它分配给tf.Variable,然后获取。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)