TransX数据集
TransE是一种常见的知识图谱嵌入方法,它需要一个包含实体,关系和三元组的知识图谱数据作为输入。以下是制作TransE数据集的一般步骤:
1.收集知识图谱数据:首先需要收集实体和关系的信息,这可以通过网站,数据库或其他来源获得。这些数据通常以三元组的形式呈现,其中每个三元组包含一个头实体,一个关系和一个尾实体。
2.清洗数据:在收集到数据后,需要进行数据清洗以确保数据的质量。这可以包括去除重复的三元组,去除不一致或不完整的实体和关系等。
3.划分训练,验证和测试集:为了评估TransE模型的性能,需要将数据集划分为训练,验证和测试集。通常,大部分数据被用于训练模型,而验证和测试集用于评估模型的性能。
4.根据三元组构建实体和关系的集合:为了使用TransE模型,需要将实体和关系表示为向量。为此,可以根据三元组构建实体和关系的集合,并为每个实体和关系分配唯一的ID。然后,可以将这些ID用作TransE模型的输入。
5.为每个三元组生成训练数据:对于每个三元组,可以将其表示为头实体,关系和尾实体的向量表示。然后,可以使用这些向量表示来生成训练数据,其中训练数据由头实体,关系,尾实体和标签组成。标签表示该三元组是否存在于知识图谱中。
6.保存数据:最后,将生辰的数据保存为恰当的格式,以供TransE模型使用。常见的格式包括CSV,JSON和RDF等。
以上是制作TransE数据集的一般步骤,具体实现可能因应用场景的不同而有所变化。
经典知识图谱如Yago,WordNet,Freebase,是算法研究过程中常用以计算指标的验证数据集。
- WordNet最早在1995年被George A.Miller在论文WordNet:A Lexical Database for English中提出。
- Yago在2007年Fabian M.Suchanek,Gjergji Kasneci和Gerhard Weikum的工作Yago:a core og semantic knoeledge中进入人们眼球
- Freebase则出现最晚,2008年Kurt D.Bollacker,Colin Evans,Praveen Paritosh,Tim Sturge和Jamie Taylor的文章Freebase: a collaboratively created graph database for structuring human knowledge 中正式给出关于Freebase的描述。
WordNet数据集:是一个描述英文词汇之间关联特点的数据集,同时也是一个数据库。该数据库将英语名词,动词,形容词和副词与同义词联系起来,这些同义词通过语义关系相互联系,从而确定单词的定义。
在最近的研究中使用WordNet数据集,并不是使用1995年提出的,而是使用子集的WN18和WN18RR。
- WN18(2013)是WordNet1995的子集,该子集中relatioin关系的主要模式是对称关系,非对称关系和反转关系。关系的类型对于知识工程任务中的信息提取,信息表征具有影响,影响模型的构建,相同算法在关系类型不同的数据集上性能的表现是不同的。
- WN18RR(2017)是WN18的子集,其中更多的保留了原数据集中的对称关系,非对称关系和组合关系,而去除了反转关系。
常用知识图谱数据集FB15K,YAGO,WN18
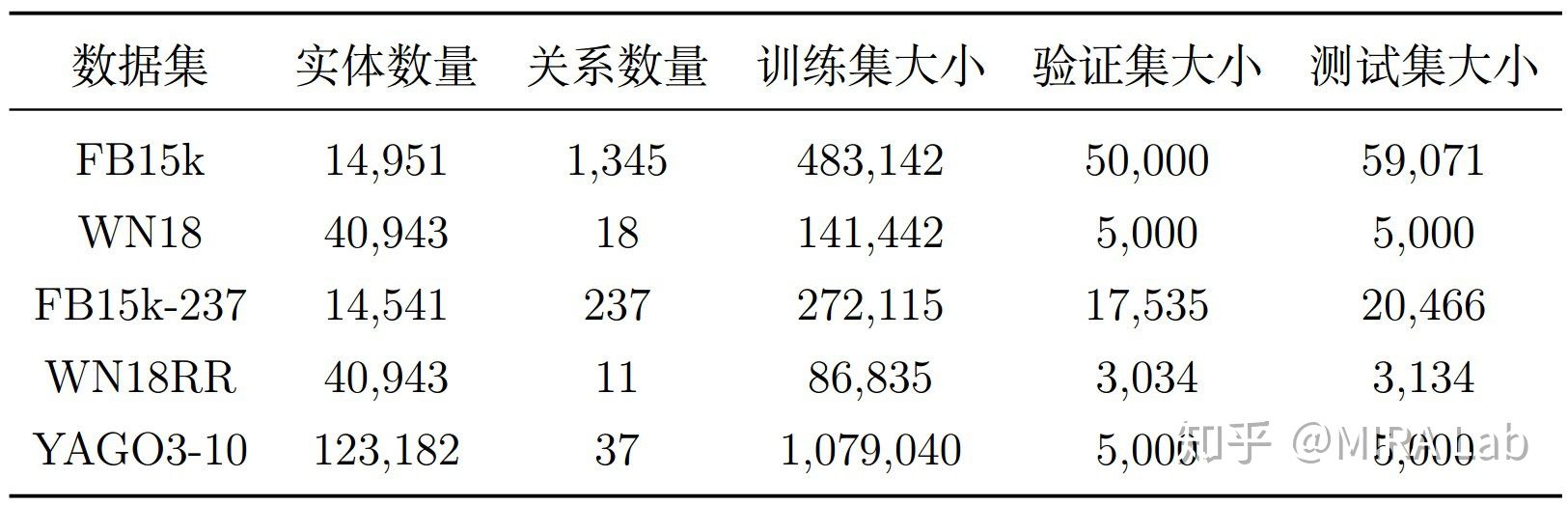
FB15K-237:FB15K-237知识图谱数据集的介绍与分析,Freebase

 浙公网安备 33010602011771号
浙公网安备 33010602011771号