知识图谱-TransE模型原理
1.TransE:多元关系数据嵌入(Translation embeddings for modeling multi-relation data)
原文链接:https://proceedings.neurips.cc/paper_files/paper/2013/hash/1cecc7a77928ca8133fa24680a88d2f9-Abstract.html
1.1TransE模型引入
知识图谱补全任务的前提任务是知识表示学习,在知识表示学习中,最为经典的模型就是TransE模型,TransE模型的核心作用就是将知识图谱中的三元组翻译成embedding向量。
1.2TransE模型思想
为了后面便于表示,我们先设定一些符号:
h表示知识图谱中的头实体的向量;t表示知识图谱中的尾实体的向量;r表示知识图谱中的关系的向量。
在TransE模型中,有这样一个假设 t = h + r
也就是说,正常情况下的尾实体向量 = 头实体向量+关系向量。用图的方式描述如下:
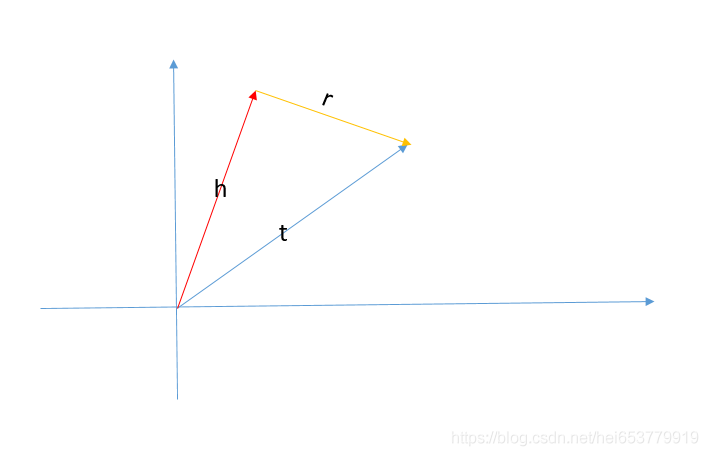
如果一个三元组不满足上述的关系,我们就可以认为这是一个错误的三元组。
1.3 TransE模型的目标函数
首先,我们先来介绍两个数学概念:
L1范数
也称为曼哈顿距离,对于一个向量X而言,其L1范数的计算公式为:
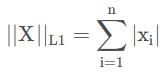
其中,Xi表示向量X的第i个属性值,这里我们取的是绝对值。并且,使用L1范数可以衡量两个向量之间的差异性,也就是两个向量的距离。
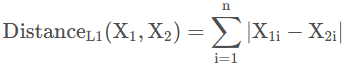
L2范数
也称为欧式距离,对于一个向量X而言,其L2范数的计算公式为:
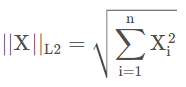
同样,L2范数也可以用来衡量两个向量之间的差距:
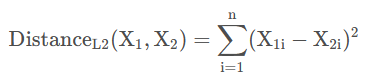
根据我们上面介绍的Trans中的假设,我们可以知道,对于一个三元组而言,头实体向量和关系向量之和与尾实体向量越接近,那么说明该三元组越接近一个正确的三元组,差距越大,那么说明这个三元组越不正常。那么我们可以选择L1或者L2范数来衡量三个向量的差距。而我们的目标就是使得争取的三元组的距离越小越好,错误的三元组距离越大越好,也就是其相反数越小越好。数学化的表示就是:
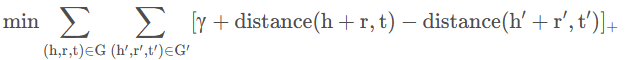
其中:
(h,r,t):表示正确的三元组
(h',r',t'):表示错误的三元组
γ :表示正样本和负样本之间的距离,一个常数
[x]+:表示max(0,x)
我们来简单的解释一下目标函数,我们的目标是让正例的距离最小,也就是min(distance(h+r,t)),让负例的相反数最小也就是(min(-distance(h'+r',t'))),对于每一个正样本和负样本求和,再增加一个常数的间距,就是整体距离的最小值。也就是我们的目标函数。
1.4 目标函数的数学推导
这里,我们采用欧式距离作为distance函数,则目标函数可以改写为:
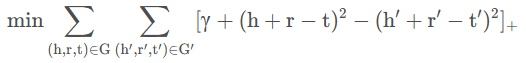
则对于损失函数loss就有:
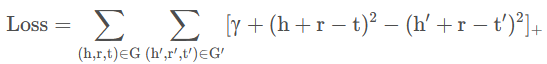
在损失函数中,我们知道所有的参数包括{h,r,t,h',r,t'}。下面,我们来逐个进行梯度推导:
1.首先是对h的梯度,对于某一个hi而言
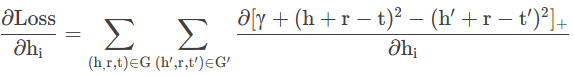
在整个求和的过程中,只针对包括hi的项求导:
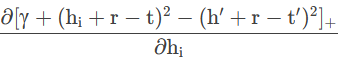
有:
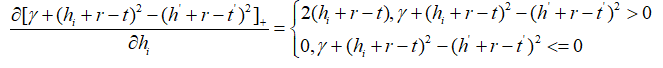
则原式变为:
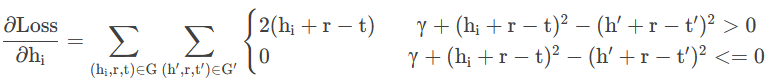
同理对于ti,hi',ti'有:
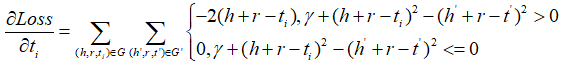
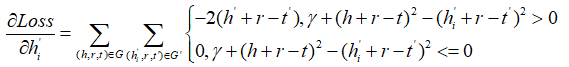
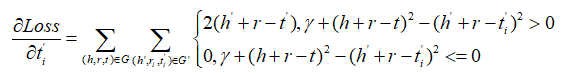
最后对于ri,γ有:
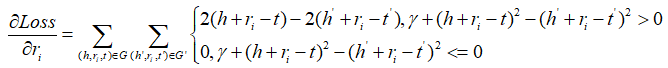
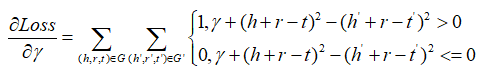
1.5如何产生负样本
在我们之前算法描述中,我们提到了负样本的问题,对于一个知识图谱而言,其中保存的全部都是正样本时肯定的了。那么,我们如何获取负样本呢?
具体的可以通过随机替换头实体的方式来实现一个错误的三元组,或者采用随机替换一个错误的尾实体的方式来形成一个错误的三元组。
同时,为了避免,我们在替换形成的三元组也存在于知识图谱中,我们需要在替换之后形成过滤。
博客链接:https://blog.csdn.net/hei653779919/article/details/104278583
